CUDA和Tensorflow安装问题,包括如何在一台机器上配置多个CUDA环境和Tensorflow版本
CUDA和Tensorflow安装相关问题
- 安装CUDA和Tensorflow一般流程
-
-
- 1. 查看显卡可安装的CUDA版本
- 2. Tensorflow版本以及对应CUDA、cuDNN版本如何查看
-
- Python安装
- Tensorflow安装
- Cuda相关安装
-
- cuda安装:其实cuda不一定需要匹配
- cuDnn和cudatoolkit 安装
- 多Cuda环境切换
-
- 遇到的问题
-
- Cuda版本问题
-
- 1. 驱动版本过高,报错:cublasSgemm_v2:CUBLAS_STATUS_EXECUTION_FAILED #332
- 2. Could not dlopen library 'libcudart.so.9.0'
- 项目移植问题
-
-
- 使用conda.yaml导出库存在conda Solving environment: failed ResolvePackageNotFound问题
-
之前在其他服务器上配置项目环境,遇到许多许多问题,研究许久觉得已经明白CUDA和Tensorflow安装,在此总结梳理一下。
我需要安装的是GPU版本的tensorflow-1.11、环境是CUDA 9.0;(我项目本身只需要tensorflow1.x即可跑起来)
我尝试的三个服务器本身环境是:
| 类别 | A (原本的服务器) | B(待安装服务器1) | C(待安装服务器2) |
|---|---|---|---|
| 显卡 | GeForce RTX 2080 Ti | GeForce RTX 2080 Ti | a10 |
| Cuda | cuda 10.2 | cuda 11.2 | cuda 10.1 |
| cudatoolkit | cudatoolkit=9.0=h13b8566_0 | ----- | – |
| cudnn | cudnn=7.6.5=cuda9.0_0 | ----- | – |
| tensorflow | tensorflow-1.11 | tensorflow-2.0 | – |
最后运行起来的服务器是A、B
| 类别 | A (原本的服务器) | B |
|---|---|---|
| 显卡 | GeForce RTX 2080 Ti | GeForce RTX 2080 Ti |
| Cuda | cuda 10.2 | cuda 9.0(多cuda切换) |
| cudatoolkit | cudatoolkit=9.0=h13b8566_0 | cudatoolkit=10.2=h8f6ccaa_9 |
| cudnn | cudnn=7.6.5=cuda9.0_0 | cudnn=7.6.5=cuda10.2 |
| tensorflow | tensorflow-1.11 | tensorflow-1.11 |
安装CUDA和Tensorflow一般流程
1. 查看显卡可安装的CUDA版本
如果没有安装显卡驱动 Linux下Nvidia驱动的安装需要先安装
安装完成后,使用下面命令查看显卡情况
nvidia-smi
不是NVIDIA显卡:Linux(Ubuntu)系统查看显卡型号
命令行结果如下:

最上面一行显示当前显卡可支持的CUDA最大版本是 11.4;
接下来查看需要安装什么Tensorflow和CUDA以及cuDNN
注:以上概念的区别
显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?
一文讲清楚CUDA、CUDA toolkit、CUDNN、NVCC关系
Nvidia Driver决定着系统最高可以支持什么版本的cuda和cudatoolkit
Nvidia Driver是向下兼容的
cuda和cudatoolkit不同,前者说的是系统安装的cuda,它是由Nvidia官方提供的(/usr/local/cuda就是系统安装的cuda的软链接)。后者是anaconda官方提供的用来build 的一个工具包,它是Nvidia所提供的cuda的一个子集。
cudnn:为深度学习计算设计的软件库。
CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。
2. Tensorflow版本以及对应CUDA、cuDNN版本如何查看
匹配规则的网站:https://tensorflow.google.cn/install/source_windows?hl=en#gpu
点开可以看到:tensorflow-1.11需要python 3.5~3.6;cuDNN 7 CUDA 9.0
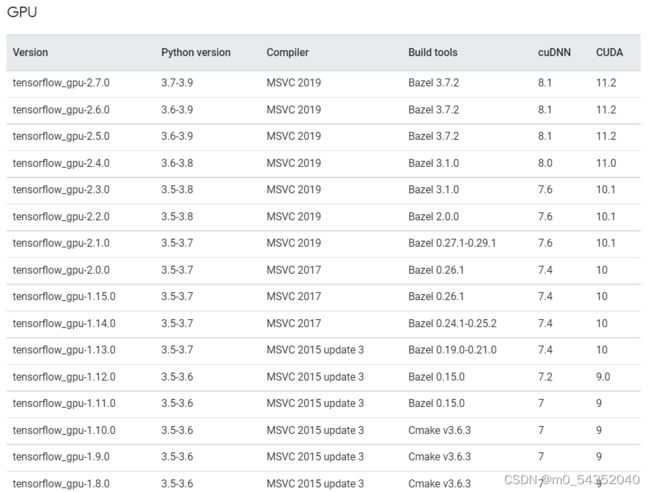
Python安装
使用conda环境安装,创建新环境的时候一起安装了
conda create -n tf1 python=3.6
Tensorflow安装
pip install tensorflow-gpu==1.11
Cuda相关安装
cuda安装:其实cuda不一定需要匹配
我需要安装的tensorflow-gpu=1.11,需要安装的cuda是9.0;cuDNN是7
![]()
但是我能够运行的服务器
- 服务器A是cuda 10.2不匹配,但是 cudatoolkit安装的是 cudatoolkit=9.0=h13b8566_0;对应9.0即可以运行
- 服务器B是cuda 9.0,cudatoolkit 安装的是10.2;也可以运行;
相对来说cuda安装更麻烦一点,所以可以不安装对应的cuda,不过我当时遇见一个问题是cudatoolkit在服务器B上的源中搜索不到9.0的版本,所以我安装了cuda9.0
在服务器B上原本存在cuda 11.2,一个服务器可以有多个cuda版本只需要做好多版本cuda管理即可
具体的安装流程可以看:Linux下安装cuda和对应版本的cudnn 比较详细
总结就是:官网下载安装包,安装,选择好安装地址和安装配置,等待安装完成
最终安装好会显示如下信息:
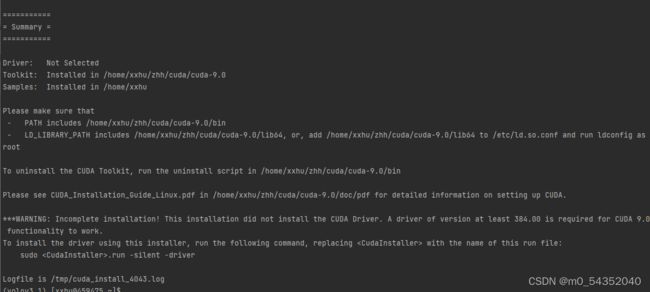
cuDnn和cudatoolkit 安装
conda install cudatoolkit=10.2
conda install cudnn=7.6
我是因为安装源只能搜到10.2的cudatoolkit所以安装的10.2对应的cudatoolkit
多Cuda环境切换
两个链接
(yolov3) [xxhu@459475 ~]$ export PATH=/home/……/cuda/cuda-9.0/bin${PATH:+:${PATH}}
(yolov3) [xxhu@459475 ~]$ export LD_LIBRARY_PATH=/home/……/cuda/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
可以用nvcc -V查看当前cuda链接上的版本
遇到的问题
Cuda版本问题
1. 驱动版本过高,报错:cublasSgemm_v2:CUBLAS_STATUS_EXECUTION_FAILED #332
很坑,我安装的一个服务器上,是A10的显卡,算力过高,导致不能使用匹配 CUDA10 或更低的 tensorflow1.x
这个问题我是在链 https://github.com/qqwweee/keras-yolo3/issues/332.看到的解答,这个解答里给出的解决方案是:使用 nvidia-tensorflow1.x 并可以使用 CUDA11.x 来加速
https://github.com/NVIDIA/tensorflow#install
我并没有尝试。
2. Could not dlopen library ‘libcudart.so.9.0’
没有安装对应版本的cudatoolkit、cuda。
需要cuda9.0的共享库:cuda、cudatoolkit有一个的包能提供对应tensorflow类别的共享库即可;
- 服务器A是cuda 10.2,但是 cudatoolkit安装的是 cudatoolkit=9.0=h13b8566_0;就可以找到对应的共享库;
- 服务器B是cuda 9.0,cudatoolkit 安装的是10.2,也可以找到对应的共享库
多cuda可以看看cuda是否链接到9.0的版本
或者看看cudatoolkit版本对不对
就是确保:1. 电脑里有这个共享库,没有就下载 2. 有这个库,要能找到,找不到就链接上去
项目移植问题
使用conda.yaml导出库存在conda Solving environment: failed ResolvePackageNotFound问题
用服务器A中的环境导出Conda.yaml,在服务器B中安装conda env create -f envname.yml,存在conda Solving environment: failed ResolvePackageNotFound的项目移植问题:导出的时候会把包的详细信息包括机器配置信息也导出来造成其他机器使用不了
解决方法:删去后面包的信息
例如: cudatoolkit=9.0=h13b8566_0,修改为 cudatoolkit=9.0或者 cudatoolkit
具体可看:conda Solving environment: failed ResolvePackageNotFound: