TVM Relay Pass探究
引言
Relay 是 TVM 中十分重要的基础组件之一,用于对接不同格式的深度学习模型以及进行模型的 transform。深度学习编译器的核心功能就是进行各种各样的 transform 变换,这个变换过程部分是由 Pass 来实现。当需要遍历计算图时,底层究竟是如何执行的?本文打算一探究竟。
1. 简介
Pass 两层设计:
TIR 层,基于
target的优化,主要涉及 lower 到 target 时采用的优化策略,包括:VectorizeLoop、UnrollLoop、RemoveNoOp、SkipAssert、ThreadSync 等;此部分 Pass 有时可以直接复用底层编译器的 pass,如 LLVM/CUDA C 等编译器。TVM 主要关注和 ML 相关且底层编译器未考虑到的场景。Relay 层:基于
计算图的优化,主要通过对 AST 分析,进行 node 的修改来实现。
Pass 功能上可分为三类:
module level:
tvm.transform.ModulePass,利用全局信息进行优化,可以增加或删除 module 内的 function;例如 FlattenNestedTuples, RemoveUnusedFunctions, PartitionGraph, InferType, dead code elimination, A-normal form conversion, lambda lifting;
function level:
tvm.relay.transform.FunctionPass、tvm.tir.transform.PrimFuncPass,对 IRModule 内的单个或多个 function 进行改写,TVM 中绝大部分 Pass 都是这类;例如 comm subexpression elimination, vectorizition;
sequential level:
tvm.transform.Sequential,是一个 container,可以装载多个 Pass,顺序执行;可以认为是前两个的一个封装而已。
TVM 中有较多的 Pass,运行我们在调用时可以创建一个 PassContext 上下文环境,调用优先级:disabled_pass > required_pass > opt_level。
首先检查该 Pass 是否被用户 disable,然后检查该 pass 是 required,最后检查 Pass 的 opt_level 是否低于 pass context 中的 opt_level。如上均满足条件后,该 pass 即为 enabled。对应代码如下:
bool PassContext::PassEnabled(const PassInfo& info) const {
if (PassArrayContains(operator->()->disabled_pass, info->name)) {
return false;
}
if (PassArrayContains(operator->()->required_pass, info->name)) {
return true;
}
return operator->()->opt_level >= info->opt_level;
}常用 Pass 的 opt_level见下面列表,可以看到 FuseOps 作为推理性能强相关的 Pass,其优先级默认设置为了最高(0,数字越小,优先级越高),FoldConstant 常量折叠的优先级也被设置为了 2。更为激进的性能优化 Pass 如 CombineParallelConv2d、FastMath、DenseToSparse 和 Conv2dToSparse2 等都被设置为了 4 和 5。由于 TVM demo 中大部分都是设置 opt_level=3,上面提到的更为激进的性能优化 Pass 并没有 enable。因此,我们可以设置更高的 opt_level,同时在 required_pass 参数列表中加入所需 pass,则可以进一步提升模型的推理性能哦。10 行代码改动,性能提升 10% 不是梦。
FuseOps:0
DeadCodeElimination:1
FoldConstant:2
ConvertLayout:3
EliminateCommonSubexpr:3
CombineParallelConv2d:4
CombineParallelDense:4
CombineParallelBatchMatmul:4
FastMath:4
DenseToSparse:4
Conv2dToSparse2:5
2. 添加 Pass
作为推理性能优化开发者,免不了对 Pass 进行修改或新增。Relay 层主要有两种 Pass 添加方式:
通过 Python 装饰器
@relay.transform.function_pass(opt_level=1),只能添加 function level 的 Pass:python/tvm/relay/transform/transform.py,这种方式下代码仓库中只有一个 Pass ChangeBatch 使用了这种方式;通过 C++ 方式,TVM 中几乎所有 Pass 都是采用这种方式实现。
继承
ExprMutator类,定义一个新的 Pass 类,重写VisitExpr_(后序遍历AST, Post-DFS order) 和Rewriter_成员函数,最后将该 Pass 注册到 Pass 管理器中;继承
ExprRewriter类,定义一个新的 Pass 类,重写Rewriter_成员函数,最后将该 Pass 注册到 Pass 管理器中;当然,还有其他组合方式,但上面 2 个是最常见的方式。
笔者个人推荐用 C++ 方式实现 Pass,原因:
Python 装饰器方式可参考代码少,TVM 中只有一个 Pass ChangeBatch 使用了这种方式,且这个 Pass 不常用。
Python 装饰器方式功能单一,Pass 基础类底层都是 C++ 实现的,一些基础方法并没有全部映射到 Python 端。
Pass 底层实现:
tvm::relay::ExprFunctor类(核心基类),其有如下 2 个重要的派生类:ExprVisitor 类:通过
VisitExpr_成员函数递归地后序遍历 AST,不修改 node 的成员函数ExprMutator 类:通过
VisitExpr_成员函数递归地后序遍历 AST,通过Rewriter_成员函数修改 AST
tvm::relay::ExprRewriter也是十分重要的一个基类:只有Rewriter_成员函数,用来非递归地后续遍历并修改 AST。
Pass 底层执行的逻辑都是与如上几个类强相关,如果仅阅读代码,很容易一头雾水。下面具体以一个例子(功能为获取模型中的所有 op),单步调试进入代码,看看其调用逻辑。
3. Pass 底层调用逻辑
基类 ExprFunctor 和 派生类 ExprVisitor、ExprMutator 代码定义在 python/tvm/relay/expr_functor.py 中,我们通过一个端到端 demo,实现一个读取 ResNet18 模型并输出其所有 op 信息的功能。这里不涉及到计算图修改,因此可以继承 ExprVisitor 实现一个 OpLister 类,测试代码如下:
import tvm
from tvm import relay
from tvm.relay import testing
def list_ops(expr):
class OpLister(tvm.relay.ExprVisitor):
def visit_op(self, expr):
if expr not in self.node_memo_map:
self.node_list.append(expr)
return super().visit_op(expr)
def list_nodes(self, expr):
self.node_memo_map = {}
self.node_list = []
self.visit(expr)
return self.node_list
ins = OpLister()
return ins.list_nodes(expr)
mod, params = tvm.relay.testing.resnet.get_workload(
batch_size=1, num_classes=1000, num_layers=18)
op_names = list_ops(mod["main"])
print(op_names)
[Op(nn.softmax), Op(nn.bias_add), Op(nn.dense), Op(nn.batch_flatten), Op(nn.global_avg_pool2d), Op(nn.relu), Op(nn.batch_norm), Op(add), Op(nn.conv2d), Op(nn.max_pool2d)]首先,在第 23 行设置断点,Debug 模式运行如图 1,params 是一个 dict 类型的变量,存储有模型权重信息;mod 是一个 IRModule 类实例,IRModule 内的数据结构是 Map。
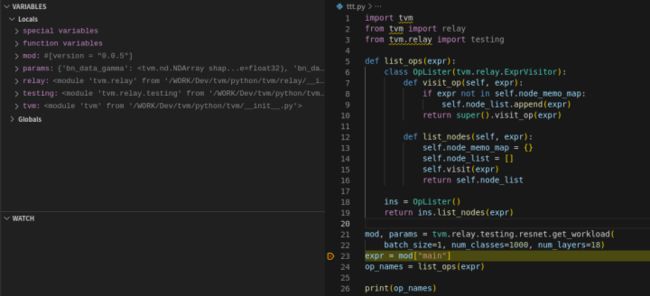
图 1

图2
继续单步执行 step,图 2 中可以看到执行 mod["main"] 时,实际在执行 IRModule 类的特殊方法 __getitem__,第 105 行会返回一个 Function 类型的变量 expr,图 3 中可以 expr 就是从 mod 中读取的,看到两个红框内的数据是一样的。

下面到了重点,要执行 list_ops 函数了。这里首先将相关类的继承关系再次列出来方便后续分析,ExprFunctor -> ExprVisitor ->OpLister。由于 list_ops 函数内有 OpLister 类定义,因此首先应该执行 OpLister 类的定义,而后执行第 18 行,调用 OpLister 的构造函数,由于 OpLister 没有显示定义构造函数,且继承了 ExprVisitor 类,因此这时会直接调用 ExprVisitor 类的构造函数。但是,ExprVisitor 类中也没有显示定义构造函数,因此会直接寻找其父类 ExprFunctor 中的构造函数并执行。我们 step 单步调试来验证下,如图 4,程序直接执行到 ExprFunctor 的构造函数,定义了一个 memo_map 成员变量,该变量的作用是存储已访问的 AST 信息,当遍历 AST 时,首先查找 expr 是否已经存在 memo_map 中,如果没有再根据 expr 的类型递归遍历。这样可以节省 AST 的遍历时间。

继续单步执行,图 5 中可以看到 ins 实例中只有一个成员变量 memo_map,当前该变量是一个空字典。
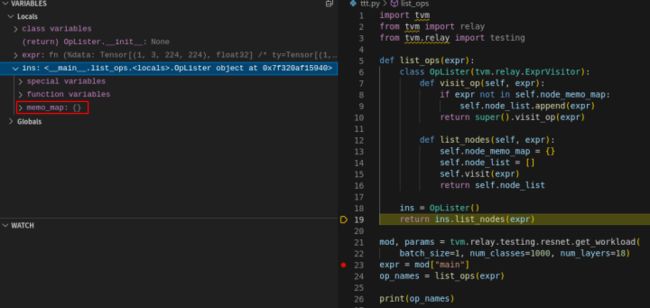
图5
继续单步执行,执行到 list_nodes 函数内部,新增了 OpLister 类的成员变量 node_memo_map 和 node_list,如图 6 所示。

下面又到了重点:执行 self.visit(expr),根据继承关系依次查找,OpLister 和 ExprVisitor 均没有该函数定义,在 ExprFunctor 类中有成员函数 visit,因此这里会执行到 ExprFunctor 类中的 visit 函数,如图 7 :

ExprFunctor 类中的 visit 函数功能为根据传入的 expr 具体类型,调用 ExprVisitor 类中的具体类型 visit 函数,实现类型函数派发。比如,前面由 mod["main"] 获取到 Function 类型的 expr,这时调用 ExprVisitor 类中的 visit_function 函数。visit_function 函数功能为循环遍历访问 Function 中的 params,存储到 memo_map 中。例如图 8 中将 Var(data, ty=TensorT... float32) 写入到 mem_map 中。
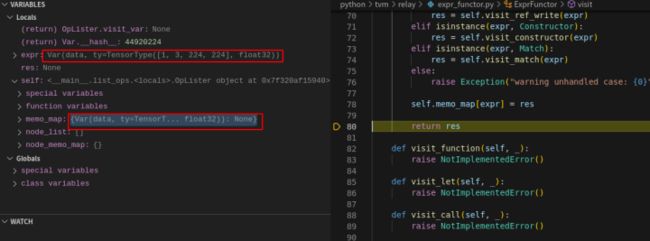
执行 visit_function 函数内的 for 循环会将所有的 params 存储到 memo_map。图 9 中展示了循环 3 次后获取到的三个 Var:

图9
ResNet18 中含有 100 个 Var,这里不展示中间过程了。我们直接在 line 158 设置断点并执行到该行,self.visit(fn.body) 为遍历 fn 的函数体,即 N 多个 CallNode,见图 10。这时执行 self.visit(fn.body) 时,根据类型派发,会调用到 visit_call 函数(图 11)。


CallNode 中含有丰富的信息(代码片段如下),如被调用的算子、调用时的输入参数等。图 11 中,expr.op 为 Op(nn.softmax),expr.args 为 [CallNode(Op(nn.bias_add), [...])],需要留意的是 expr.args 中包含有 expr.op 依赖的所有前驱 CallNode 信息。
// include/tvm/relay/expr.h
class CallNode : public ExprNode {
protected:
// CallNode uses own deleter to indirectly call non-recursive destructor
Object::FDeleter saved_deleter_;
static void Deleter_(Object* ptr);
public:
/*!
* \brief The operator(function) being invoked
*
* - It can be tvm::Op which corresponds to the primitive operators.
* - It can also be user defined functions (Function, GlobalVar, Var).
*/
Expr op;
/*! \brief The arguments(inputs) of the call */
tvm::Array args;
/*! \brief The additional attributes */
Attrs attrs;
/*!
* \brief The type arguments passed to polymorphic(template) function.
*
* This is the advance feature that is only used when the function is
* polymorphic. It is safe to be ignored in most cases. For example, in the
* following code, the type_args of addone call is [int].
*
* \code
*
* template
* T addone(T a) { return a + 1; }
*
* void main() {
* int x = addone(10);
* }
*
* \endcode
*/
tvm::Array type_args;
...
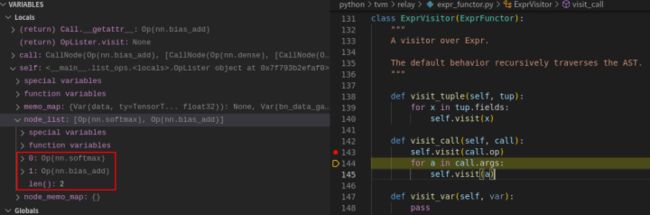
}; 继续单步调试,visit_call 函数功能为先访问 call.op,然后遍历访问所有的 call.args,见图 12。

当执行 self.visit(call.op) 时,根据类型派发,会执行到下图中的 visit_op(图 13)。这里需要注意了,visit_op 在 ExprFunctor、ExprVisitor 和 OpLister 中都有定义,self 是一个 OpLister 的实例,因此这里会实际跳转执行到 OpLister 类中的 visit_op 成员函数(图 14)。

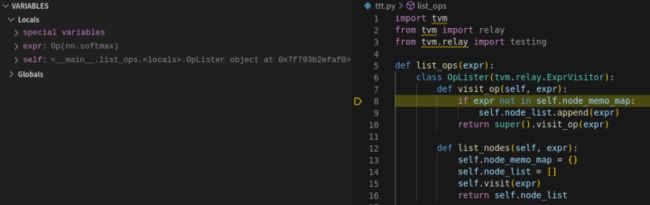
图14
OpLister 类中的 visit_op 成员函数功能为记录当前访问到的算子,记录到 op_list 中,然后执行父类 ExprVisitor 中的 visit_op(expr). ExprVisitor 中的 visit_op(expr) 函数内只有一个 Pass 语句,没有实际执行的内容,因此这里也可以删除 super().visit_op(expr),见图 14。这时,我们获取到了模型中的一个算子 Op(nn.softmax)。
循环执行如下 for 循环,会依次获取到其他算子信息,见图 15。最终,会获得所有的 op 信息。
ResNet18 IRModule 尾部结构可视化如下,可以对照着查看模型遍历执行逻辑。

4. 总结
针对从 torch 转入的模型,输入 mod 就已经包含有算子间的所有调用关系信息了,ExprVisitor 类只是递归遍历,依次递归遍历抽取出 Var、Call 等信息。通过单步调试,可以进一步加深对代码逻辑的理解。笔者个人知识水平有限,文中理解若有问题,欢迎各位大佬指点交流,一起学习提高。
最后给我们团队的开源项目打个广告,Adlik 是中兴通讯贡献的深度学习推理工具,已获得 Linux AI 基金会支持,目前仍在持续完善中,期待大家的支持和关注:Github Adlik;另外,我们也在做深度学习编译器方向的前沿技术研发工作,欢迎感兴趣的小伙伴加入我们 ~~
参考
https://tvm.apache.org/docs/arch/pass_infra.html
https://zhuanlan.zhihu.com/p/341334406
往期相关推荐:
面向ASIC设备的编译器框架:TVM or MLIR?
深度学习模型编译框架TVM概述