黑马点评项目笔记(四)社交、附近人、数据统计功能实现
目录
-
- 达人探店
-
- 查看博文
- 点赞博文
- 点赞排行榜
- 好友关注
-
- 关注和取关
- 共同关注
- 关注推送(Feed流)
-
- Feed流的两种模式
-
- Timeline 三种实现模式
- 基于推模式实现消息推送
-
- 滚动分页
- 附近商户
-
- GEO数据结构
- 附近商家搜索
- 用户签到
-
- BitMap数据结构
- 实现签到功能
- 签到统计
- 布隆过滤器
- UV统计
-
- hyperLoglog 数据结构
达人探店
谁去哪个店铺发布了那些内容信息(图片、文字、标题)以及后台内容信息(点赞数、评论数、发布时间、修改时间)这里图片存入的是地址,在添加图片还未发布时,图片就已经上传并返回地址,发布时携带图片地址一起上传


查看博文
在查看笔记内容的同时,也要查看发布者的头像、昵称信息


点赞博文
一个用户同一个笔记只能点一个赞,再点一次则取消
因此需要判断当前博文有没有被该登录用户点过赞,给博文添加一个isLike字段,在查询博文时,也根据用户id,查询用户在查询时判断此用户是否给其点过赞,为其赋值
查询用户是否为其博文点赞方式:
- 使用数据库 创建一张表,单独存储哪个用户给哪个博文点过赞。(过于笨重)
- 使用redis 使用set集合(利用不可重复特性,与前面一人一单相似),根据博客编号作为key,value存放所有给此博文点赞的用户id
- 在刷新显示博文时,对所有博文进行遍历 在redis中判断此用户是否为其点过赞,并将结果赋值到isLiked字段

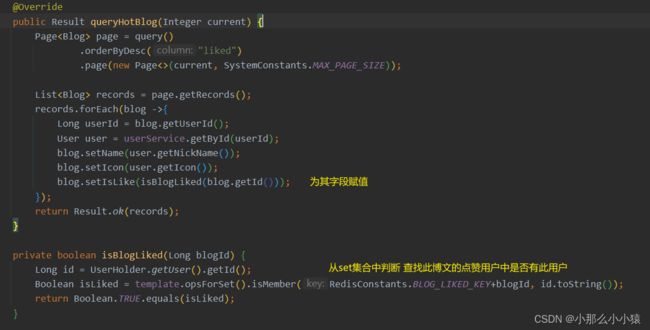
- 在用户点赞是,判断用户之前是否为其点赞过 同时更改redis中博文点赞用户集合和数据库中博文点赞数目

点赞排行榜
显示按时间点赞的前5名用户
涉及排行榜,要想到redis集合中 进行有序存储的SortedSet(list虽然也支持排序,但元素不唯一,且链表查找较慢),使用时间戳作为score,由于sortedSet是降序排列,时间戳小的就会靠前,正好符合题意。要将原来储存博文点赞信息的set集合改为sortedSet集合,由于储存的信息都是用户id,所以还有去数据库查询用户的基本信息(头像、昵称等)
但sortedSet 没有判断元素是否存在的命令,只能通过查询分数来判断是否为null zScore key element, zRange key 0 4按照分数(这里存入的是时间戳)查询前5名点赞用户的id
-
将点赞博文中的set全部替换成sortSet

-
根据查询出的用户id,转为对应的用户dto返回

问题:
虽然从redis中获取的是按照时间戳由小到大,但数据库查询结果是按照用户id由小到大 ,数据库将参数自动进行排序,不符合业务规则


好友关注
关注和取关
此用户可以关注很多其他用户,其他很多用户也可以关注此用户,因此是多对多关系。采用中间表进行连接

关注:将关注的用户和被关注的用户插入表中
取消关注:将对应数据删除

共同关注
利用set的交集功能 ,A关注的博主id存入A的set集合中,B关注的博主id存入B的set集合中,最后将A和B set中内容的求交集即为共同关注内容
- 改造以上关注功能,将关注的信息同时存入与用户id有关的key中

- 求两个set的交集,即共同关注用户的id,再去数据库中根据id 批量查询用户,转为DTO 返回前端

关注推送(Feed流)
用户发表博文时,将内容投送给粉丝

Feed流的两种模式
-
Timeline:不做内容筛选,简单的按照内容发布时间排序。例如朋友圈:只要有好友无论内容是否感兴趣,就会进行推送- 优点:信息全面,不会有缺失。每次都会将内容全部推送
- 缺点:用户对某些信息可能不感兴趣
-
智能排序: 通过智能算法屏蔽掉用户不感兴趣的内容,根据用户喜好进行推送- 优点:投喂式推送给用户,更吸引用户
- 缺点:依赖于算法,算法要精准,否则可能错过用户感兴趣的,推动不感兴趣的
项目中使用 Timeline
Timeline 三种实现模式
拉模式(读扩散):被关注的用户将博文id按时间顺序发送到自己的发件箱中(被动),粉丝们在读取所有关注者动态时,会从各个被关注者的发件箱中拉取到自己的收件箱,并按时间进行排序。就像点多家餐,自己要去挨家去取
- 优点:消息只保存一份,收件箱会拉取后会删除,节省内存
- 缺点:每一次读取都会将消息重新拉取,若关注用户多,耗时会变长
- 实现思路(猜测):被关注者将自己的博文id放入自己的SortedSet集合中,并使用时间戳作为score,粉丝查看动态时,获取自己set集合中遍历所有关注的用户id,根据id去查看他们对应的发件箱获取新的博文id,在根据id遍历数据库转换成博文
推模式(写扩散):被关注者发送博文时,将博文id推送到各个粉丝的收件箱中(主动),自己不做保留,没有发件箱。粉丝的收件箱将各个消息按时间进行排序,根据id去数据库中查找,转换成为对应博文。就像点多家餐,等待多个外卖送到家中
- 优点:粉丝只需要从自己的收件箱中获取即可,耗时少
- 缺点:消息重复推送给多个用户,造成内存占用高
推拉模式:将不同的用户采取不同的策略。例如粉丝较少,采用推模式可以较少耗时,又不会大量备份;粉丝数量较多,采用拉模式,可以避免大量消息重复,又可以防止僵尸粉耗费资源(因为虽然关注但不查看,就没必要放在他的收件箱,想要查看时进行拉取即可)
- 优点:资源合理利用
- 缺点:十分复杂
三者对比:

基于推模式实现消息推送
问题:
使用 list or SortedSet ?二者都可以进行排序,从而进行分页
传统分页
list只能根据角标进行查询,而数据可能不断变化,导致角标经常发生变化
例:插入 C,B,A(越新的数据越靠前) , 每次分页查询前两条数据即C,B ;查询下一页时,数据新增D ,查询出的数据变为 D,C。导致角标对应的数据发生变化,数据混乱

滚动分页
每次记录查询的最后一条,下次查询从最后一条往后去查询。这样查询需要获取值的内容,并使用值去排序
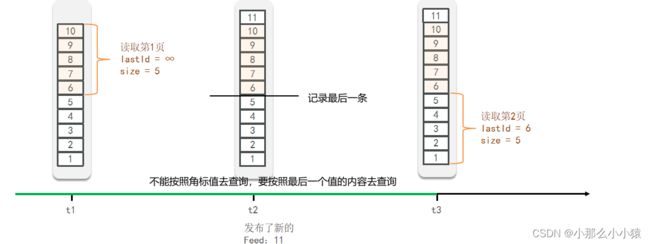 而
而SortedSet中,正好有一个 可以按照值的范围去查找 zrange min max count ,图中的值可为时间戳,不断增大
使用sortedSet
按照角标方式 如果按照升序排列,时间戳为score,每次读取从旧到新,就不会导致排名发生变化,但不符合业务要求从新到就旧

按照score排序

滚动分页规律

- 被关注端: 发布探店笔记时,数据库保存后记录博文的id,查询该用户的粉丝userId从而在redis找到粉丝的收件箱,将博文id推送到粉丝的收件箱中

- 粉丝端:查询所有关注者的动态 ,除了服务器自动获取的userId、关注者的博文信息 外,还需要传递从已接收数据的最小score,以及 offset。获若不传递则score使用最大时间,即当前时间戳,offset为0 (从第一开始获取)

进行滚动分页查询

附近商户
reids使用Geo进行地理位置处理
GEO数据结构
存储地理位置信息,进行地理位置计算
常用命令:
- GeoAdd 【key】【【经度】【维度】【点的名称】…】 添加多个位置 点(通过经纬度确定)


- GeoDist 【key】【点1的名称】【点2的名称】(【单位 km】默认为m):查询两点间的距离
- GeoHash 【key】【点的名称】: 将点的信息以hash字符串的形式,方便储存

- GeoPos 【key】【点的名字】:显示key中某个点的经纬度
- GeoSearch 【key】fromLonLat 【中心的经度】【中心的维度】ByRadius 【距离值】【单位 m/ km 】(withDist 带上距离) :查询距离中心【形状 如圆形,方形】距离小于多少【距离值】【单位】的所有点,默认升序
6.2版本出现
附近商家搜索
前端 传递 定位的经纬度(x,y),商家类型,距离范围
按距离范围搜索功能是由redis的GEO数据结构自动完成的,在注册商家时,要将商家编号对应的位置信息添加在redis中 。为了方便查询分组将他们按照类型分为一组,即同一个key

由于附近店铺搜索的 GeoSearch 命令出现在redis 6.2版本之后,redis场景启动器配置的版本过低,因此需要移除旧版本,换入新版本
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<exclusions>
<exclusion>
<artifactId>spring-data-redisartifactId>
<groupId>org.springframework.datagroupId>
exclusion>
<exclusion>
<artifactId>lettuce-coreartifactId>
<groupId>io.lettucegroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-redisartifactId>
<version>2.6.2version>
dependency>
<dependency>
<groupId>io.lettucegroupId>
<artifactId>lettuce-coreartifactId>
<version>6.1.6.RELEASEversion>
dependency>
按距离查询附近商家,并排序分页

用户签到
采用数据表形式太重
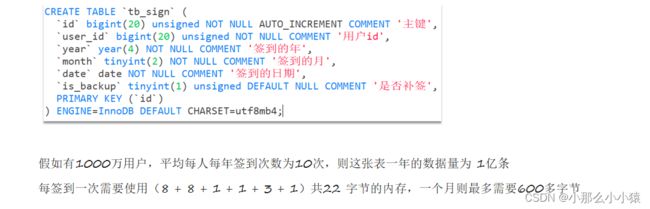
而采用位图思想,每一天有两种可能(签到或没有签到),所以使用二进制 0 1 表示。一个月最多有31天,每个人只需要31个bit,不到4B的数据就可以记录一个月的签到情况
redis使用BitMap来实现

BitMap数据结构
常用命令:
-
setBit 【key】【要设置第几位】【置为 1 or 0】 :将key的第几个位置存入一个 0 或 1 。默认为0 (
常用于签到)

-
getBit 【key】【要获取第几位】:获取key的第几位的bit值 (
判断哪天有没有签到) -
BitCount 【key】:统计key中1的个数 (
查看一个月签到了多少天) -
BitField 【key】【操作类型 GET】【是否有符号 i:有符号 u:无符号】【读取位数】【从哪里开始读取】:常用无符号的一次读取多个位数的bit位 (
常用获取具体的签到结果)

-
BitOp【key】:将bitMap的结果记性运算
-
bitOps【key】【0 or1】 :查找给定的bit值第一次出现的位置

实现签到功能
签到只是将代表当天的某个位置的bit设置为1

签到统计
统计连续签到的天数即 从当天数,连续为1的bit个数

布隆过滤器
一个很长的二进制向量和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。
根据 :两个哈希值相同但原始值不一定相同(哈希碰撞),但原始值相同哈希值一定相同 。将key转为哈希值,并将值对应bit的位置 置为1,即代表key存在。查询时,将key转为hash值,在去bitMap的对应位置比对,判断是否为1,若为0则代表数据中一定不存在,进行拦截 。 若hash数字过长,可除bitMap设定的最大值(会增大误差),确保所有hash结果都能找到对应的bitMap中bit位。
特点:
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。 (只要存在就一定会将对应bit位为1,但bit位 为1 ,可能是其他hash值相同的key)
- 布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。(因为一个bit位 可能代表多个key)
可用于拦截 如:缓存穿透;去重;,但存在小概率误差
相关链接
问题:
- 怎样获取本月的所有签到数据:
getBit只能获取某一天一个数据,要获取多个数据只能使用bitFIeld指定起始位置(本月第一天)与获取个数(即当日所在的位置),获取多个数据,但会把二进制转为十进制 - 如何从后往前查找连续为1的bit位?
- 最后一个值与1进行与运算,若仍为1 ,说明当前bit位为1 计数器+1
- 将最后一个值进行右移一位
>>>,使得下一位与1进行与运算,如此循环 - 直到与预算结果为0 ,查看计数器的值


UV统计
uv即 Unique Visitor 独立访客量。即每天每个人无论访问多少次该网站,都只会被记录一次
pv即 Page View 页面访问量:只要有一访问,无论是否是一个人多次访问,,只要访问一次就记录一次。用户衡量网站流量
uv统计要判断次数的同时,还要判定身份,确保是不同的人才会进行+1。如果直接写入,将会导致非常大的数据量
hyperLoglog 数据结构
一种概率统计算法,基于String数据结构实现 。用户确定数据量非常大的集合基数,而不需要存储其所有值。最大亮点无论多么大的数据量,内存占用永远小于16K,但是有小于0.81%误差
常用命令:
- PfAdd 【key】 【value…(大量)】
- PfCount 【key】统计key中的不重复的元素个数
- PfMerge 【【key1】【key2】…】:将其他hyperLogLog类型的key进行
合并。例如 每天统计访问用户数,最后合并可求出一个月的有多少个访问的用户数

向其添加1千万条数据测试

黑马点评项目结束