Embeding技术:word2vec Parameter Learning Explained
参考链接
- 论文链接:https://arxiv.org/pdf/1411.2738v4.pdf
一、主要内容:
- word2vec模型:
- CBOW 模型:continuous bag-of-word
- SG模型:skip-gram
- 优化技术:
- 分层softmax:hierarchical softmax
- 负采样:negative sampling
二、CBOW 模型:
- 1、One-word context 模型:
- 模型图:

- 上图是一个全连接神经网络,在预测当前此时我们只使用前一个词作为上下文信息,就像一个二元模型(bigram model)一样。
- 输入层是一个单词的one-hot表示, V V V是词汇表的大小,隐藏层单元个数为 N N N
- 输入层到隐藏层:连接矩阵为 W V × N W_{V×N} WV×N,隐藏层与输入层的连接是简单的线性连接(即没有激活函数),两层的连接公式为:

- v w I T v_{wI}^T vwIT是 W T W^T WT的列(即 W W W的行), w I w_I wI是输入的词。
- 由于 X X X是单词的one-hot表示,若 X X X表示词汇表的第 k k k个单词,则 X X X列向量除了第 k k k个元素为1以外其他元素都是0,这样 h = W T X h=W^TX h=WTX,这相当于取出 W T W^T WT的第 k k k列(即 W W W的第 k k k行)作为 h h h,实质这就是第 k k k个单词的embeding表示.
- 隐藏到输出层:连接矩阵为 W N × V ′ W_{N × V}' WN×V′, 两层的连接公式为: U = W ′ T h U={W'}^T h U=W′Th U U U是一个大小为 V V V的列向量,每个元素对于词汇表的一个词,我把每个元素称为其对应词的分数 (score),第 j j j个词的分数就是公式如下:
u j u_j uj是词汇表中第 j j j个词的得分也是输出层每个单元的输入, v w j ′ T {{v_{wj}}'}^T vwj′T是 W ′ W' W′的第 j j j列。

- 然后将 U U U经过一softmax层(softmax:一个对数线性分类模型)得到每个单词的后验分布(即概率值),softmax层表达式(第 j j j个词的后验概率):
上式的含义是输入词汇表的第 I I I个单词输出第 j j j个词的概率,即第 j j j个词在第 I I I个词后面的概率,其中 y j y_j yj是输出层第 j j j个单元的输出,对应于词汇表的第 j j j个词。

- 注意: v w v_w vw和 v w ′ v_w' vw′是对应单词 w w w的两表示,我们将他们分别称为 w w w的输入向量与输出向量,输入向量 v w v_w vw是输入层到隐藏层连接矩阵 W W W的行,输出向量是隐藏层到输出层连接矩阵 W ′ W' W′的列
- 隐藏层到输出层参数 W ′ W' W′更新:
- 优化的目标函数如下
w I w_I wI是当前输入词, w o w_o wo是目标预测词(实际输出词), j ∗ j^* j∗是词 w o w_o wo在词汇表的下标。

- 损失函数为: E = − l o g p ( w o ∣ w I ) E=-logp(w_o |w_I) E=−logp(wo∣wI)目标函数就是最小化该损失函数
- 损失函数 E E E关于 u j u_j uj的导数:
u j u_j uj是输出层第 j j j个单元的输入, e j e_j ej是输出层的误差, t j t_j tj在 j = j ∗ j=j^* j=j∗时为1,其他情况为0,相当于 w o w_o wo的one-hot表示。

- 求 E E E对参数矩阵 W ∗ W^* W∗的导数:
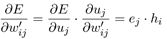
- 使用梯度下降算法我们得到 W ′ W' W′的更新公式
注意: 按照上面的式子更新 W ′ W' W′是我们要计算词汇表每个词的误差 e j e_j ej,所以计算量比较大.

- 优化的目标函数如下
- 输入层到隐藏层的参数 W W W更新:
-
求 E E E对隐藏层输出 h i h_i hi的导数:
令: e = [ e 1 , e 2 , … , e V ] T e=[e_1,e_2,…,e_V ]^T e=[e1,e2,…,eV]T W ′ = [ v w 1 ′ , v w 2 ′ , … , v w V ′ ] W'=[v_{w1}',v_{w2}',…,v_{wV}'] W′=[vw1′,vw2′,…,vwV′]矩阵形式为: E H = e T W ′ = ∑ j = 1 V e j v w j ′ EH=e^T W'=∑_{j=1}^V e_j v_{wj}' EH=eTW′=j=1∑Vejvwj′即 E H EH EH是输出向量 v w j ′ v_{wj}' vwj′的加权和权重就是其对应词的预测误差 e e e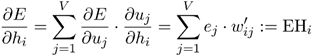
-
求 E E E对 W W W的导数:
- 首先我们上面说过,输入层到隐藏层是简单的线性链接:

- 这样 E E E关于 W W W的导数为:

- 矩阵形式为:
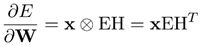
- 上式的结果是一个与 W W W大小一样的矩阵,由于 x x x是one-hot编码,所以中间只有一个1其余都是0,所以结求导矩阵中只有一行是非零的其余行都是0,非零行就是 E H T EH^T EHT.所以最后跟新的只是W中的一行,即输入词 W I W_I WI对应的行,所有更新公式为:
E H EH EH是词汇表每个词的输出向量的误差加权和,所以上式可以理解为:将词汇表的每个词的输出向量按照一定比例加入到词 w I w_I wI的输入向量中去。

- 首先我们上面说过,输入层到隐藏层是简单的线性链接:
-
- 模型图:
- 2、Multi-word context 模型:
- 模型图:
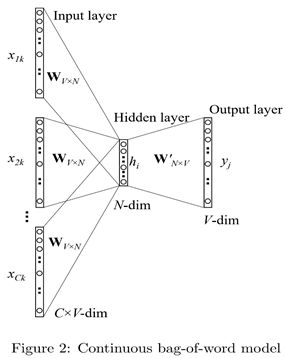
- 该模型是用多个上下词的信息来预测当前词,用上下文词的one-hot编码的平均值作为输入产生隐藏层的输出,公式如下:
C是上下文词的数量。

- 模型的损失函数是:
该公式除了 h h h与one-word-context model公式不同以外其他都是相同的。

- 隐藏层到输出层权重 W ′ W' W′更新公式为:
与one-word-context model是一样
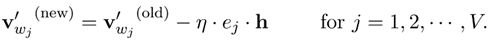
- 输出层到隐藏层权重 W W W更新公式为
v w I , c v_{w_{I,c}} vwI,c是输入的上下文中第 c c c个词的的输入向量。
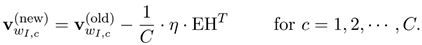
- 模型图:
三、skip-gram 模型:
- 模型图:

- 目标词在输入层,上下文词在输出层。那么输入层到隐藏层的含义与One-word context模型是一样的,如下公式:

- 在输出层上,我们将输出 C C C个多项式分布,而不是输出一个多项式分布。 每个输出都是使用相同的隐藏层到输出层的矩阵 W ′ W' W′进行计算:
由于 W ′ W' W′是共享的,所以虽然模型图上画了 C C C个是输出向量,但他们都是相等的即:


- 损失函数为:
j c ∗ j_c^* jc∗是是第 C C C个输出词在词汇表的索引号, E E E是是C个上下文输出词的概率的乘积。

- 计算E对 u c j u_{cj} ucj的导数为:
令: E I = [ E I 1 , E I 2 , … , E I V ] T EI=[EI_1,EI_2,…,EI_V ]^T EI=[EI1,EI2,…,EIV]T E I j = ∑ c = 1 C e c , j EI_j=∑_{c=1}^Ce_{c,j} EIj=c=1∑Cec,j即 E I EI EI是 C C C个误差向量( [ e 1 , e 2 , . . . , e C ] [e_1,e_2,...,e_C] [e1,e2,...,eC])之和

- 计算E对 W ′ W' W′的导数为:
是C个导数的累加,则更新公式为:


- W W W的更新公式为:
其中 E H EH EH是 N N N维向量,公式如下:


- 注意: 上面的推到公式与One-word context模型是非常相似的,不同的是误差: E I j EI_j EIj与 e j e_j ej。 E I j EI_j EIj是 C C C个输出误差的累加
四、优化技术:
- 对于词汇表的每个词 w w w都有一个对应的输入向量 v w v_w vw和一个输出向量 v w ′ v_w' vw′,他们分别是输出层到隐藏层连接矩阵 W W W的行与隐藏层到输出层链接矩阵 W ′ W' W′的列。由上面的更新公式可知,更新 v w v_w vw计算量是比较小的,更新 v w ′ v_w' vw′计算量是比较大的。因为我们更新 v w ′ v_w' vw′需要计算整个词汇表的全部词的误差 E I j EI_j EIj或 e j e_j ej,这样在模型训练时对于每个样本我们都必须计算每个词的误差,这个计算量是非常大的。
- 为了解决这个问题,我们可以每次必须更新的输出向量 v w ′ v_w' vw′的数量,具体的方法是:分层softmax(hierarchical softmax)和采样法(sampling)。
1、Hierarchical Softmax 技术:
- 该模型使用一颗二叉树来表示整个词汇表的所有词,词汇表的所有词都在二叉树的叶节点,如下图所示:

- 根节点到每个词的路径用于估计单词的概率。用 n ( w , j ) n(w,j) n(w,j)表示更节点到词 w w w路径上的第 j j j个节点。
- 在分层softmax模型中,每个单词的输出向量 v w ′ v_w' vw′。树中的V − 1个中间节点都有一个输出向量 v n ( w , j ) ′ v_{n(w,j)}' vn(w,j)′,输出某个词的概率定义如下:
c h ( n ) ch(n) ch(n)表示节点 n n n的左子树; v n ( w , j ) ′ v_{n(w,j)}' vn(w,j)′表示叶节点 w w w路径上第 j j j个内部节点的向量表示; h h h是隐藏层的输出向量, [ ] [] []函数定义如下:


- 现在假设我想计算输出页节点 w 2 w_2 w2的概率,我们将这个概率定义为从根节点随机走到叶节点 w 2 w_2 w2的概率,为此我们为每个内部节点定义一个向左和向右走的概率,下面是内部节点向左走的概率:
其中 σ σ σ是sigmoid函数定义如下:
 则向右走的概率为:
则向右走的概率为:

- 于是我们得到输出词 w 2 w_2 w2的概率:
形式化的定义就是上面上式子:
 并且有下面式子成立:
并且有下面式子成立:
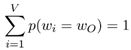
- 下面推导树内部节点向量的更新公式:
- 首先令(为了简化公式):
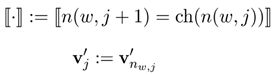
- 损失函数为:
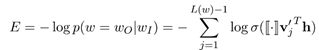
- E对 v j ′ h v_j' h vj′h的导数为:
当 [ . ] = 1 [.]=1 [.]=1是 t j = 1 t_j=1 tj=1其他情况都为0,可以理解为当前词的表示为其对应节点的哈夫曼编码。

- E对 v j ′ v_j' vj′的导数为:

- v j ′ v_j' vj′的更新等式为:

- 每个样本只需要更新其目标词路径上的内部节点的向量就可以了,这就大大减少更新向量的数目;我们可以将 σ ( v j ′ T h ) − t j σ(v_j'^T h)-t_j σ(vj′Th)−tj视作内部节点 n ( w , j ) n(w,j) n(w,j)的误差。
- 对于CBOW可以直接使用该更新方程,对于skip-gram模型我们需要使用该方程到C个预测上下文词上。
- E对隐藏层输出h的导数:
EH可以视作是当前样本预测词路径上每个内部节点对应向量 v j v_j vj的误差加权和。对于CBOW模型直接使用上面等式求出EH向量,对于skip-gram模型我们需要计算每个上下文输出词的EI向量再相加的得到最终的EI向量。

- 输入层到隐藏层链接矩阵 W W W更新公式为:
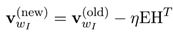
- 由上面的更新公式可以看出,我们预测每个词的更新参数复杂的由 O ( V ) O(V) O(V)降低到 O ( l o g V ) O(logV) O(logV)这是一个巨大的提升。并且隐藏层到输出层的参数个数只减少了一个,从V(输出向量)个变成V-1(内部节点向量)个
- 首先令(为了简化公式):
2、 Negative Sampling 技术:
- Negative Sampling比Hierarchical Softmax直接很多,它直接对词汇表中的词进行采样,得到一个采样集合,集合中的词是需要更新的词,显然,预测的目标词必须在该集合中,因此我们需要采样的是非目标词,因此叫做负采样法(负样本采样)。
- 采样过程需要一个概率分布,我们称该分布为噪声分布,记为 p n ( w ) p_n (w) pn(w),该分布的依靠个人的经验进行设置。
- 定义损失函数为:
其中 w 0 w_0 w0是目标输出词, v w o ′ v_{w_o}' vwo′是目标输出词对于的输出向量; h h h是隐藏层输出向量; W n e g = { w j ∣ j = 1 , 2 , … , K } W_{neg}=\{w_j |j=1,2,…,K\} Wneg={wj∣j=1,2,…,K}是根据分布 p n ( w ) p_n (w) pn(w)采样的集合。我们每次迭代都只更新与目标词和负采样集合中词对应的输出向量 v w j ′ v_{w_j}' vwj′。

- 求E对采样集合中词对应的输出层单元的输入 v w j ′ T h v_{wj}'^T h vwj′Th的导数:
t j t_j tj相当于目标词在采样集合内的one-hot编码值。

- 输出向量 v w j ′ v_{wj}' vwj′的更新等式:
其中 w j w_j wj是负采样集合中的词,即 { w j │ j = 0 , 1 , 2 , … , K } = { w 0 } ∪ { W n e g } \{w_j│j=0,1,2,…,K\}=\{w_0 \}∪\{W_{neg} \} {wj│j=0,1,2,…,K}={w0}∪{Wneg},即我们每次迭代只需更新负采样集合对应的部分的参数向量。该更新公式能够直接应用到CBOW模型中去,对于skip-gram模型中需要将上面过程应用到C输出的上下文词上去。

- 求E对隐藏层输出向量 h h h的导数:
对于CBOW模型我们直接使用上式计算EI向量,对于skip-gram模型我们需要对每个输出词计算一个EI向量再相加得到总的EI。

- 输出层到隐藏层链接矩阵 W W W的更新公式:

- 这样更新的复杂度由原来的O(V)变为O(K),K是负采样集合的大小。