深入理解Java虚拟机— jvm调优案例分析与实战
上一篇:深入理解Java虚拟机—垃圾收集器适用场景
下一篇:深入理解Java虚拟机—虚拟机类加载机制
jvm调优案例分析与实战
一. 高性能硬件上的调优:
1. 采用64位操作系统,并为JVM分配大内存
我们知道,如果JVM中堆内存太小,那么就会频繁地发生垃圾回收,而垃圾回收都会伴随不同程度的程序停顿,因此,如果扩大堆内存的话可以减少垃圾回收的频率,从而避免程序的停顿。
因此,人们自然而然想到扩大内存容量。而32位操作系统理论上最大只支持4G内存,64位操作系统最大能支持128G内存,因此我们可以使用64位操作系统,并使用64位JVM,并为JVM分配更大的堆内存。但问题也随之而来。
堆内存变大后,虽然垃圾收集的频率减少了,但每次垃圾回收的时间变长。如果堆内存为14G,那么每次Full GC将长达数十秒。如果Full GC频繁发生,那么对于一个网站来说是无法忍受的。
因此,对于使用大内存的程序来说,一定要减少Full GC的频率,如果每天只有一两次Full GC,而且发生在半夜, 那完全可以接受。
要减少Full GC的频率,就要尽量避免太多对象进入老年代,可以有以下做法:
- 确保对象都是“朝生夕死”的
一个对象使用完后应尽快让他失效,然后尽快在新生代中被Minor GC回收掉,尽量避免对象在新生代中停留太长时间。 - 提高大对象直接进入老年代的门槛
通过设置参数-XX:PretrnureSizeThreshold来提高大对象的门槛,尽量让对象都先进入新生代,然后尽快被Minor GC回收掉,而不要直接进入老年代。
注意:使用64位JDK的注意点
- 64位JDK支持更大的堆内存,但更大的堆内存会导致一次垃圾回收时间过长。
现阶段,64位JDK的性能普遍比32位JDK低。 - 堆内存过大无法在发生内存溢出时生成内存快照
- 若将堆内存设为10G,那么当堆内存溢出时就要生成10G的大文件,这基本上是不可能的。
- 相同程序,64位JDK要比32位JDK消耗更大的内存
2. 使用32位JVM集群
针对于64位JDK种种弊端,我们更多选择使用32位JDK集群来充分利用高性能机器的硬件资源。
如何实现?
在一台服务器上运行多个服务器程序,这些程序都运行在32位的JDK上。然后再运行个服务器作为反向代理服务器,由它来实现负载均衡。
由于32位JDK最多支持2G内存,因此每个虚拟结点的堆内存可以分配1.6G,一共运行10个虚拟结点的话,这台物理服务器可以拥有16G的堆内存。
有啥弊端?
- 多个虚拟节点竞争共享资源时容易出现问题
如多个虚拟节点共同竞争IO操作,很可能会引起IO异常。 - 很难高效地使用资源池,
如果每个虚拟节点使用各自的资源池,那么无法实现各个资源池的负载均衡。如果使用集中式资源池,那么又存在竞争的问题。 - 每个虚拟节点最大内存为2G
二. JVM性能调优方法和步骤
1. 监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化。
举一个例子: 系统崩溃前的一些现象:
每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值,这个时候就需要分析JVM内存快照dump。
2. 生成堆的dump文件
通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
3. 分析dump文件
打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux,几种工具打开该文件:
Visual VM
IBM HeapAnalyzer
JDK 自带的Hprof工具
Mat(Eclipse专门的静态内存分析工具)推荐使用
备注:文件太大,建议使用Eclipse专门的静态内存分析工具Mat打开分析。
4. 分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化,如果GC时间超过1-3秒,或者频繁GC,则必须优化。
注:如果满足下面的指标,则一般不需要进行GC:
Minor GC 执行时间不到50ms;
Minor GC 执行不频繁,约10秒一次;
Full GC 执行时间不到1s;
Full GC 执行频率不算频繁,不低于10分钟1次;
5. 调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择。
6. 不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数,如果找到了最合适的参数,则将这些参数应用到所有服务器
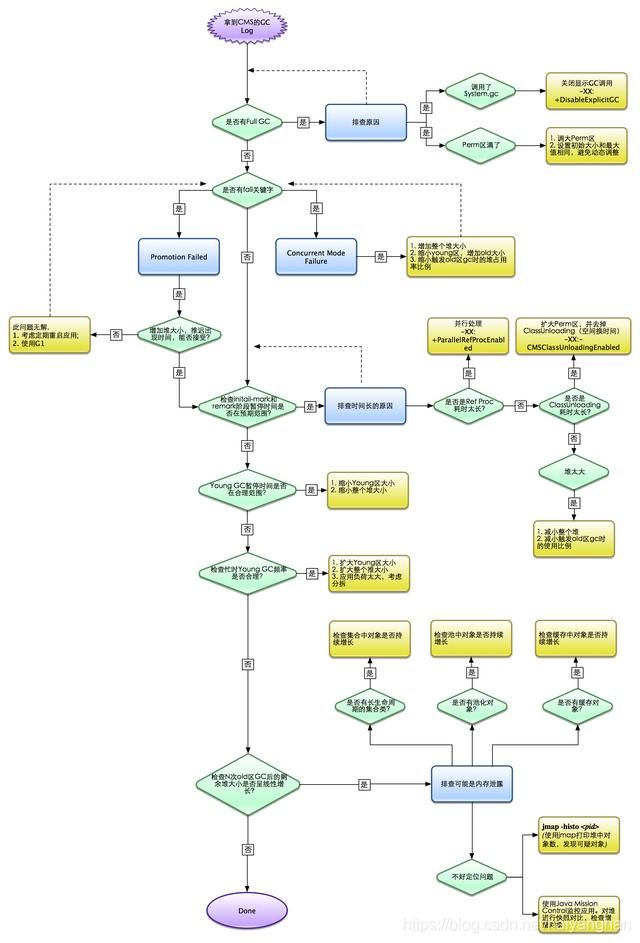
三. JVM内存泄漏
内存泄漏是比较常见的问题,而且解决方法也比较通用,这里可以重点说一下,而线程、热点方面的问题则是具体问题具体分析了。
内存泄漏一般可以理解为系统资源(各方面的资源,堆、栈、线程等)在错误使用的情况下,导致使用完毕的资源无法回收(或没有回收),从而导致新的资源分配请求无法完成,引起系统错误。
内存泄漏对系统危害比较大,因为他可以直接导致系统的崩溃。
需要区别一下,内存泄漏和系统超负荷两者是有区别的,虽然可能导致的最终结果是一样的。内存泄漏是用完的资源没有回收引起错误,而系统超负荷则是系统确实没有那么多资源可以分配了(其他的资源都在使用)
1. 年老代堆空间被占满
异常: java.lang.OutOfMemoryError: Java heap space
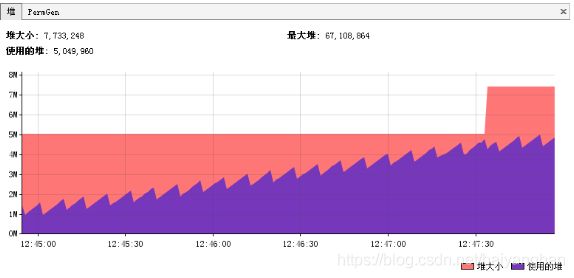
这是最典型的内存泄漏方式,简单说就是所有堆空间都被无法回收的垃圾对象占满,虚拟机无法再在分配新空间。
如上图所示,这是非常典型的内存泄漏的垃圾回收情况图。所有峰值部分都是一次垃圾回收点,所有谷底部分表示是一次垃圾回收后剩余的内存。连接所有谷底的点,可以发现一条由底到高的线,这说明,随时间的推移,系统的堆空间被不断占满,最终会占满整个堆空间。因此可以初步认为系统内部可能有内存泄漏。(上面的图仅供示例,在实际情况下收集数据的时间需要更长,比如几个小时或者几天)
解决:
- 这种方式解决起来也比较容易,一般就是根据垃圾回收前后情况对比,同时根据对象引用情况(常见的集合对象引用)分析,基本都可以找到泄漏点。
2.持久代被占满
异常:java.lang.OutOfMemoryError: PermGen space
说明:
Perm空间被占满。无法为新的class分配存储空间而引发的异常。这个异常以前是没有的,但是在Java反射大量使用的今天这个异常比较常见了。主要原因就是大量动态反射生成的类不断被加载,最终导致Perm区被占满。
更可怕的是,不同的classLoader即便使用了相同的类,但是都会对其进行加载,相当于同一个东西,如果有N个classLoader那么他将会被加载N次。因此,某些情况下,这个问题基本视为无解。当然,存在大量classLoader和大量反射类的情况其实也不多。
解决:
- -XX:MaxPermSize=16m
- 换用JDK。比如JRocket
3. 堆栈溢出
异常: java.lang.StackOverflowError
说明: 这个就不多说了,一般就是递归没返回,或者循环调用造成
4. 线程堆栈满
异常: Fatal: Stack size too small
说明: java中一个线程的空间大小是有限制的。JDK5.0以后这个值是1M。与这个线程相关的数据将会保存在其中。但是当线程空间满了以后,将会出现上面异常。
解决:
- 增加线程栈大小。-Xss2m。但这个配置无法解决根本问题,还要看代码部分是否有造成泄漏的部分
5. 系统内存被占满
异常: java.lang.OutOfMemoryError: unable to create new native thread
说明:
这个异常是由于操作系统没有足够的资源来产生这个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
分配给Java虚拟机的内存愈多,系统剩余的资源就越少,因此,当系统内存固定时,分配给Java虚拟机的内存越多,那么,系统总共能够产生的线程也就越少,两者成反比的关系。同时,可以通过修改-Xss来减少分配给单个线程的空间,也可以增加系统总共内生产的线程数。
解决:
- 重新设计系统减少线程数量。
- 线程数量不能减少的情况下,通过-Xss减小单个线程大小。以便能生产更多的线程。
四. JVM调优参数参考
-
针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,通常把最大、最小设置为相同的值;
-
年轻代和年老代将根据默认的比例(1:2)分配堆内存, 可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代。
比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小。 -
年轻代和年老代设置多大才算合理
- 更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
- 更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
如何选择应该依赖应用程序对象生命周期的分布情况: 如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性。
在抉择时应该根 据以下两点:
(1)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 。
(2)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间。 -
在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC 。
-
线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。
1. jvm参数
| 参数名称 | 含义 | 默认值 | |
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 |
|
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右 一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长) 和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"” -Xss is translated in a VM flag named ThreadStackSize” 一般设置这个值就可以了。 |
|
| -XX:ThreadStackSize | Thread Stack Size | (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 |
|
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大, 会影响Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | ||
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率 该参数只有在串行GC时才有效. |
|
| -XX:+AggressiveOpts | 加快编译 | ||
| -XX:+UseBiasedLocking | 锁机制的性能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1s | softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节 新生代采用Parallel Scavenge GC时无效 另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
2. 并行收集器相关参数
| -XX:+UseParallelGC | Full GC采用parallel MSC (此项待验证) |
选择垃圾收集器为并行收集器.此配置仅对年轻代有效.即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集.(此项待验证) |
|
| -XX:+UseParNewGC | 设置年轻代为并行收集 | 可与CMS收集同时使用 JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值 |
|
| -XX:ParallelGCThreads | 并行收集器的线程数 | 此值最好配置与处理器数目相等 同样适用于CMS | |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式为并行收集(Parallel Compacting) | 这个是JAVA 6出现的参数选项 | |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) | 如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值. | |
| -XX:+UseAdaptiveSizePolicy | 自动选择年轻代区大小和相应的Survivor区比例 | 设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开. | |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 | 公式为1/(1+n) | |
| -XX:+ScavengeBeforeFullGC | Full GC前调用YGC | true | Do young generation GC prior to a full GC. (Introduced in 1.4.1.) |
3. CMS相关参数
| -XX:+UseConcMarkSweepGC | 使用CMS内存收集 | 测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明.所以,此时年轻代大小最好用-Xmn设置.??? | |
| -XX:+AggressiveHeap | 试图是使用大量的物理内存 长时间大内存使用的优化,能检查计算资源(内存, 处理器数量) 至少需要256MB内存 大量的CPU/内存, (在1.4.1在4CPU的机器上已经显示有提升) |
||
| -XX:CMSFullGCsBeforeCompaction | 多少次后进行内存压缩 | 由于并发收集器不对内存空间进行压缩,整理,所以运行一段时间以后会产生"碎片",使得运行效率降低.此值设置运行多少次GC以后对内存空间进行压缩,整理. | |
| -XX:+CMSParallelRemarkEnabled | 降低标记停顿 | ||
| -XX+UseCMSCompactAtFullCollection | 在FULL GC的时候, 对年老代的压缩 | CMS是不会移动内存的, 因此, 这个非常容易产生碎片, 导致内存不够用, 因此, 内存的压缩这个时候就会被启用。 增加这个参数是个好习惯。 可能会影响性能,但是可以消除碎片 |
|
| -XX:+UseCMSInitiatingOccupancyOnly | 使用手动定义初始化定义开始CMS收集 | 禁止hostspot自行触发CMS GC | |
| -XX:CMSInitiatingOccupancyFraction=70 | 使用cms作为垃圾回收 使用70%后开始CMS收集 |
92 | 为了保证不出现promotion failed(见下面介绍)错误,该值的设置需要满足以下公式CMSInitiatingOccupancyFraction计算公式 |
| -XX:CMSInitiatingPermOccupancyFraction | 设置Perm Gen使用到达多少比率时触发 | 92 | |
| -XX:+CMSIncrementalMode | 设置为增量模式 | 用于单CPU情况 | |
| -XX:+CMSClassUnloadingEnabled |
4. 辅助信息
| -XX:+PrintGC | 输出形式: [GC 118250K->113543K(130112K), 0.0094143 secs] |
||
| -XX:+PrintGCDetails | 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] |
||
| -XX:+PrintGCTimeStamps | |||
| -XX:+PrintGC:PrintGCTimeStamps | 可与-XX:+PrintGC -XX:+PrintGCDetails混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] |
||
| -XX:+PrintGCApplicationStoppedTime | 打印垃圾回收期间程序暂停的时间.可与上面混合使用 | 输出形式:Total time for which application threads were stopped: 0.0468229 seconds | |
| -XX:+PrintGCApplicationConcurrentTime | 打印每次垃圾回收前,程序未中断的执行时间.可与上面混合使用 | 输出形式:Application time: 0.5291524 seconds | |
| -XX:+PrintHeapAtGC | 打印GC前后的详细堆栈信息 | ||
| -Xloggc:filename | 把相关日志信息记录到文件以便分析. 与上面几个配合使用 |
||
| -XX:+PrintClassHistogram |
garbage collects before printing the histogram. | ||
| -XX:+PrintTLAB | 查看TLAB空间的使用情况 | ||
| XX:+PrintTenuringDistribution | 查看每次minor GC后新的存活周期的阈值 | Desired survivor size 1048576 bytes, new threshold 7 (max 15) |
5. 重要参数
5.1 高内存高cpu
最近对JVM的参数重新看了下,把应用的JVM参数调整了下。 几个重要的参数
- -server -Xmx3g -Xms3g -XX:MaxPermSize=128m
- -XX:NewRatio=1 eden/old 的比例
- -XX:SurvivorRatio=8 s/e的比例
- -XX:+UseParallelGC
- -XX:ParallelGCThreads=8
- -XX:+UseParallelOldGC 这个是JAVA 6出现的参数选项
- -XX:LargePageSizeInBytes=128m 内存页的大小,不可设置过大,会影响Perm的大小。
- -XX:+UseFastAccessorMethods 原始类型的快速优化
- -XX:+DisableExplicitGC 关闭System.gc()
另外 -Xss 是线程栈的大小,这个参数需要严格的测试,一般小的应用,如果栈不是很深,应该是128k够用的,不过,我们的应用调用深度比较大,还需要做详细的测试。这个选项对性能的影响比较大。建议使用256K的大小
例子:
参数:
-server -Xmx3g -Xms3g -Xmn=1g -XX:MaxPermSize=128m -Xss256k -XX:MaxTenuringThreshold=10 -XX:+DisableExplicitGC -XX:+UseParallelGC -XX:+UseParallelOld GC -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+AggressiveOpts -XX:+UseBiasedLocking
-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCTimeStamps -XX:+PrintGCDetails 打印参数
另外对于大内存设置的要求:
Linux :
Large page support is included in 2.6 kernel. Some vendors have backported the code to their 2.4 based releases. To check if your system can support large page memory, try the following:
# cat /proc/meminfo | grep Huge
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
# If the output shows the three “Huge” variables then your system can support large page memory, but it needs to be configured. If the command doesn’t print out anything, then large page support is not available. To configure the system to use large page memory, one must log in as root, then:
- Increase SHMMAX value. It must be larger than the Java heap size. On a system with 4 GB of physical RAM (or less) the following will make all the memory sharable:
# echo 4294967295 > /proc/sys/kernel/shmmax
-
Specify the number of large pages. In the following example 3 GB of a 4 GB system are reserved for large pages (assuming a large page size of 2048k, then 3g = 3 x 1024m = 3072m = 3072 * 1024k = 3145728k, and 3145728k / 2048k = 1536):
# echo 1536 > /proc/sys/vm/nr_hugepages
Note the /proc values will reset after reboot so you may want to set them in an init script (e.g. rc.local or sysctl.conf)
这个设置,目前观察下来的结果是EDEN区域收集明显速度比较快,最多几个ms, 但是,对于FGC,大约需要0。9,但是发生时间非常的长,应该是影响不大。但是对于非web应用的中间件服务, 这个设置很要不得, 可能导致很严重延迟效果. 因此, CMS必然需要被使用, 下面是CMS的重要参数介绍:
使用CMS的前提条件是你有比较的长生命对象,比如有200M以上的OLD堆占用。那么这个威力非常猛,可以极大的提高的FGC的收集能力。如果你的OLD占用非常的少,别用了,绝对降低你性能,因为CMS收集有2个STOP WORLD的行为。 OLD少的清情况,根据我的测试,使用并行收集参数会比较好。
- -XX:+UseConcMarkSweepGC 使用CMS内存收集
- -XX:+AggressiveHeap 特别说明下:(我感觉对于做java cache应用有帮助)
- 试图是使用大量的物理内存
- 长时间大内存使用的优化,能检查计算资源(内存,处理器数量)
- 至少需要256MB内存
- 大量的CPU/内存,(在1.4.1在4CPU的机器上已经显示有提升)
- -XX:+UseParNewGC 允许多线程收集新生代
- -XX:+CMSParallelRemarkEnabled 降低标记停顿
- -XX+UseCMSCompactAtFullCollection 在FULL GC的时候,压缩内存, CMS是不会移动内存的,因此,这个非常容易产生碎片,导致内存不够用,因此,内存的压缩这个时候就会被启用。增加这个参数是个好习惯。
压力测试下合适结果:
参数:
-server -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xmx2g -Xms2g -Xmn256m -XX:PermSize=128m -Xss256k -XX:MaxTenuringThreshold=31 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods
由于Jdk1.5.09及之前的bug, 因此, CMS下的GC,在这些版本的表现是十分糟糕的。 需要另外2个参数来控制cms的启动时间:
-XX:+UseCMSInitiatingOccupancyOnly 仅仅使用手动定义初始化定义开始CMS收集
-XX:CMSInitiatingOccupancyFraction=70 CMS堆上,使用70%后开始CMS收集
使用CMS的好处是用尽量少的新生代、,我的经验值是128M-256M,然后老生代利用CMS并行收集,这样能保证系统低延迟的吞吐效率。实际上cms的收集停顿时间非常的短,2G的内存,大约20-80ms的应用程序停顿时间。
这个例子是测试系统12小时运行后的情况:
$uname -a
2.4.21-51.EL3.customsmp #1 SMP Fri Jun 27 10:44:12 CST 2008 i686 i686 i386 GNU/Linux
$ free -m
total used free shared buffers cached
Mem: 3995 3910 85 0 162 1267
-/+ buffers/cache: 2479 1515
Swap: 2047 0 2047
$ jstat -gcutil 23959 1000
S0 S1 E O P YGC YGCT FGC FGCT GCT
59.06 0.00 45.77 44.45 56.88 15204 324.023 66 1.668 325.691
0.00 39.66 27.53 44.73 56.88 15205 324.046 66 1.668 325.715
53.42 0.00 22.80 44.73 56.88 15206 324.073 66 1.668 325.741
0.00 44.90 13.73 44.76 56.88 15207 324.094 66 1.668 325.762
51.70 0.00 19.03 44.76 56.88 15208 324.118 66 1.668 325.786
0.00 61.62 19.44 44.98 56.88 15209 324.148 66 1.668 325.816
53.03 0.00 14.00 45.09 56.88 15210 324.172 66 1.668 325.840
53.03 0.00 87.87 45.09 56.88 15210 324.172 66 1.668 325.840
0.00 50.49 72.00 45.22 56.88 15211 324.198 66 1.668 325.866
GC参数配置:
JAVA_OPTS=" -server -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xmx2g -Xms2g -Xmn256m -XX:PermSize=128m -Xss256k -XX:MaxTenuringThreshold=31 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 "
实际上我们可以看到并行young gc执行时间是: 324.198s/15211=20ms, cms的执行时间是 1.668/66=25ms. 当然严格来说,这么算是不对的,世界停顿的时间要比这是数据稍微大5-10ms. 对我们来说如果不输出日志,对我们是有参考意义的。
32位系统下,设置成2G,非常危险,除非你确定你的应用占用的native内存很少,不然可能导致jvm直接crash。
-XX:+AggressiveOpts 加快编译
-XX:+UseBiasedLocking 锁机制的性能改善。
五. GC性能方面的考虑
对于GC的性能主要有2个方面的指标:吞吐量throughput(工作时间不算gc的时间占总的时间比)和暂停pause(gc发生时app对外显示的无法响应)
-
Total Heap
默认情况下,vm会增加/减少heap大小以维持free space在整个vm中占的比例,这个比例由MinHeapFreeRatio和MaxHeapFreeRatio指定。
一般而言,server端的app会有以下规则- 对vm分配尽可能多的memory;
- 将Xms和Xmx设为一样的值。如果虚拟机启动时设置使用的内存比较小,这个时候又需要初始化很多对象,虚拟机就必须重复地增加内存。
- 处理器核数增加,内存也跟着增大。
-
Young Generation
另外一个对于app流畅性运行影响的因素是young generation的大小。young generation越大,minor collection越少;但是在固定heap size情况下,更大的young generation就意味着小的tenured generation,就意味着更多的major collection(major collection会引发minor collection)
NewRatio反映的是young和tenured generation的大小比例。NewSize和MaxNewSize反映的是young generation大小的下限和上限,将这两个值设为一样就固定了young generation的大小(同Xms和Xmx设为一样)。
如果希望,SurvivorRatio也可以优化survivor的大小,不过这对于性能的影响不是很大。SurvivorRatio是eden和survior大小比例。
一般而言,server端的app会有以下规则:- 首先决定能分配给vm的最大的heap size,然后设定最佳的young generation的大小;
- 如果heap size固定后,增加young generation的大小意味着减小tenured generation大小。让tenured generation在任何时候够大,能够容纳所有live的data(留10%-20%的空余)
六. 经验&&规则
1. 年轻代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择).在此种情况下,年轻代收集发生的频率也是最小的.同时,减少到达年老代的对象.
- 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度.因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用.
- 避免设置过小.当新生代设置过小时会导致:1.YGC次数更加频繁 2.可能导致YGC对象直接进入旧生代,如果此时旧生代满了,会触发FGC
2. 年老代大小选择
- 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数.如果堆设置小了,可以会造成内存碎 片,高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间.最优化的方案,一般需要参考以下数据获得:
并发垃圾收集信息、持久代并发收集次数、传统GC信息、花在年轻代和年老代回收上的时间比例。 - 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代.原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象
3. 较小堆引起的碎片问题
因为年老代的并发收集器使用标记,清除算法,所以不会对堆进行压缩.当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象.但是,当堆空间较小时,运行一段时间以后,就会出现"碎片",如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记,清除方式进行回收.如果出现"碎片",可能需要进行如下配置:
-XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩.
-XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
4. promotion failed
垃圾回收时promotion failed是个很头痛的问题,一般可能是两种原因产生,第一个原因是救助空间不够,救助空间里的对象还不应该被移动到年老代,但年轻代又有很多对象需要放入救助空间;第二个原因是年老代没有足够的空间接纳来自年轻代的对象;这两种情况都会转向Full GC,网站停顿时间较长。
-
解决方方案一:
第一个原因我的最终解决办法是去掉救助空间,设置-XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0即可,第二个原因我的解决办法是设置CMSInitiatingOccupancyFraction为某个值(假设70),这样年老代空间到70%时就开始执行CMS,年老代有足够的空间接纳来自年轻代的对象。 -
解决方案一的改进方案:
又有改进了,上面方法不太好,因为没有用到救助空间,所以年老代容易满,CMS执行会比较频繁。我改善了一下,还是用救助空间,但是把救助空间加大,这样也不会有promotion failed。具体操作上,32位Linux和64位Linux好像不一样,64位系统似乎只要配置MaxTenuringThreshold参数,CMS还是有暂停。为了解决暂停问题和promotion failed问题,最后我设置-XX:SurvivorRatio=1 ,并把MaxTenuringThreshold去掉,这样即没有暂停又不会有promotoin failed,而且更重要的是,年老代和永久代上升非常慢(因为好多对象到不了年老代就被回收了),所以CMS执行频率非常低,好几个小时才执行一次,这样,服务器都不用重启了。
-Xmx4000M -Xms4000M -Xmn600M -XX:PermSize=500M -XX:MaxPermSize=500M -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=1 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log
5. 其他
- 使用CMS的好处是用尽量少的新生代,经验值是128M-256M, 然后老生代利用CMS并行收集, 这样能保证系统低延迟的吞吐效率。 实际上cms的收集停顿时间非常的短,2G的内存, 大约20-80ms的应用程序停顿时间
- 仔细了解自己的应用,如果用了缓存,那么年老代应该大一些,缓存的HashMap不应该无限制长,建议采用LRU算法的Map做缓存,LRUMap的最大长度也要根据实际情况设定
- 采用并发回收时,年轻代小一点,年老代要大,因为年老大用的是并发回收,即使时间长点也不会影响其他程序继续运行,网站不会停顿
- JVM参数的设置(特别是 –Xmx –Xms –Xmn -XX:SurvivorRatio -XX:MaxTenuringThreshold等参数的设置没有一个固定的公式,需要根据PV old区实际数据 YGC次数等多方面来衡量。为了避免promotion faild可能会导致xmn设置偏小,也意味着YGC的次数会增多,处理并发访问的能力下降等问题。每个参数的调整都需要经过详细的性能测试,才能找到特定应用的最佳配置
6. CMSInitiatingOccupancyFraction值与Xmn的关系公式
promontion faild产生的原因是EDEN空间不足的情况下将EDEN与From survivor中的存活对象存入To survivor区时,To survivor区的空间不足,再次晋升到old gen区,而old gen区内存也不够的情况下产生了promontion faild从而导致full gc.那可以推断出:eden+from survivor < old gen区剩余内存时,不会出现promontion faild的情况,即:
(Xmx-Xmn)*(1-CMSInitiatingOccupancyFraction/100)>=(Xmn-Xmn/(SurvivorRatior+2)) 进而推断出:
CMSInitiatingOccupancyFraction <=((Xmx-Xmn)-(Xmn-Xmn/(SurvivorRatior+2)))/(Xmx-Xmn)*100
例如:
当xmx=128 xmn=36 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((128.0-36)-(36-36/(1+2)))/(128-36)*100 =73.913
当xmx=128 xmn=24 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((128.0-24)-(24-24/(1+2)))/(128-24)*100=84.615…
当xmx=3000 xmn=600 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((3000.0-600)-(600-600/(1+2)))/(3000-600)*100=83.33
CMSInitiatingOccupancyFraction低于70% 需要调整xmn或SurvivorRatior值