YOLOv5白皮书-第Y2周:训练自己的数据集
目录
- 一、课题背景和开发环境
-
- 开发环境
- 二、准备好数据
- 三、划分数据集
-
- 1.运行`split_train_val.py`
- 2.运行`voc_label.py`
- 四、编辑`.yaml`配置文件
- 五、开始训练
一、课题背景和开发环境
第Y2周:训练自己的数据集
- 语言:Python3、Pytorch
开发环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.2
- 编译器:无(直接在cmd.exe内运行)
- 深度学习环境:Pytorch 1.8.1+cu111
- 显卡及显存:NVIDIA GeForce GTX 1660 Ti 12G
- CUDA版本:Release 10.2, V10.2.89(
cmd输入nvcc -V或nvcc --version指令可查看) - YOLOv5开源地址:YOLOv5开源地址
- 数据:水果检测
二、准备好数据
image文件夹下存放所有的图片文件
annotation文件夹下存放所有的label文件
两个文件夹内的图片文件名和label文件名一一对应

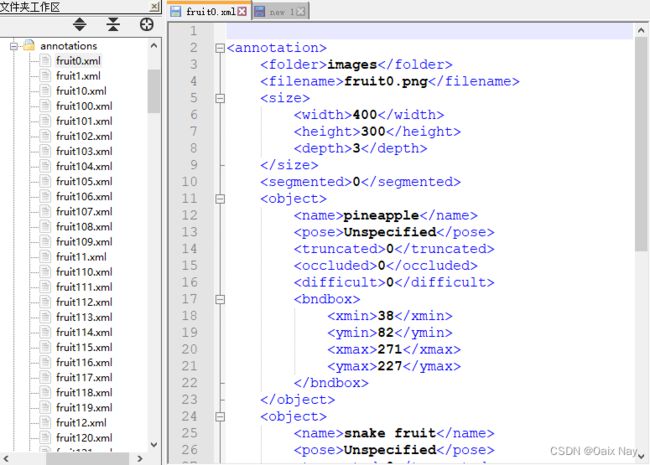
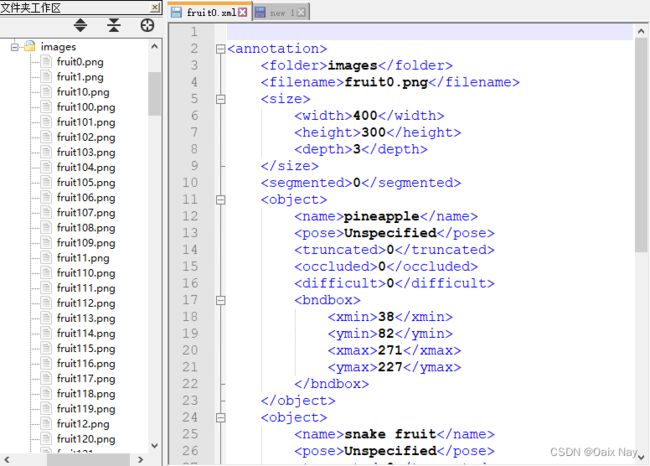
三、划分数据集
1.运行split_train_val.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 1.0
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
该脚本文件的功能是划分训练集/测试集/验证集的数据比例。
通过调整参数trainval_percent和train_percent 的数值可以调整各数据集的比例。
脚本执行完毕后,会在当前目录下生产ImageSets/Main/子文件夹,内有包含划分好的数据集信息的四个txt文件。

2.运行voc_label.py
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["banana", "snake fruit", "dragon fruit", "pineapple"]
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('./annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('./%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.png\n' % (image_id)) # 注意你的图片格式,如果是.jpg记得修改
convert_annotation(image_id)
list_file.close()
该脚本文件的主要功能是生成训练集/测试集/验证集的数据索引文件train.txt/test.txt/val.txt,并归一化标注信息(labels文件夹下)。
根据images文件夹下的图片的后缀格式调整脚本中的图片文件后缀。
脚本执行完毕后,还会在当前目录下生产labels子文件夹,内有归一化后的标注文件(txt文件)。

一开始生成的train.txt/test.txt/val.txt文件内的所有路径都是绝对路径,我的本地路径下包含有中文字符,在后面的训练读取图片数据时会报错,所以手动把路径改为了相对路径(无中文字符)。
四、编辑.yaml配置文件
fruits.yaml
类别数和类别名要和数据集以及voc_label.py脚本内的参数一致。
#path: ../datasets/coco # dataset root dir
train: ./paper_data/train.txt # train images (relative to 'path') 118287 images
val: ./paper_data/val.txt # train images (relative to 'path') 5000 images
#test: test-dev2017.txt
nc: 4 # number of classes
names: ["banana", "snake fruit", "dragon fruit", "pineapple"]
五、开始训练
训练指令的参数参考train.py脚本文件内的parse_opt()函数内关于入参的定义。
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()
我这里用的训练指令如下:
python train.py --img 640 --batch 8 --epoch 100 --data data/fruits.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device 0
第一次运行报错
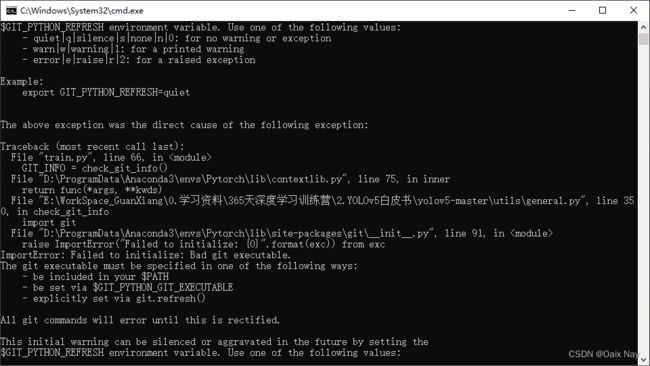
报错原因是我本地没有安装git库。由于该模块对训练过程没有影响,所以可以手动将该步骤跳过不执行,避免触发程序报错。
具体对utils/general.py脚本文件修正如下(在执行import git指令前让函数提前返回None):

修改后训练可正常开始:
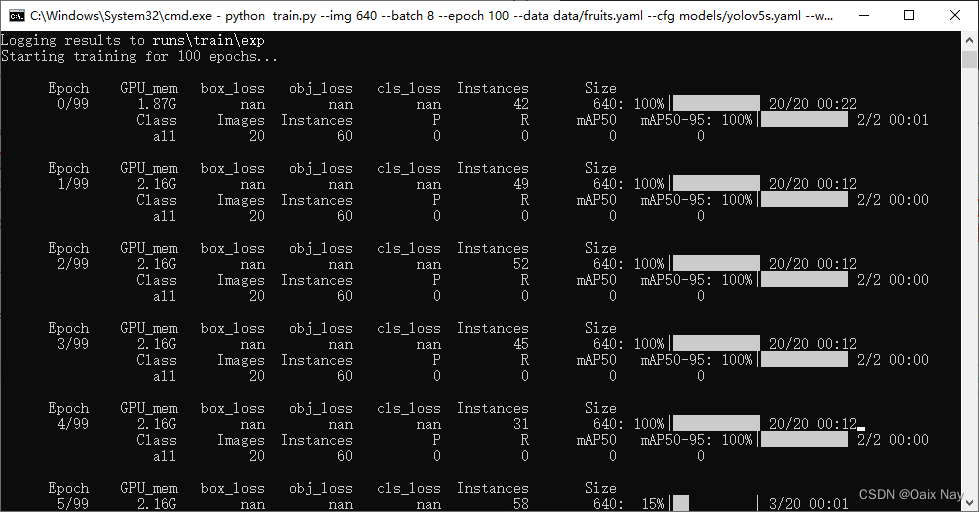
训练完成后,生成的模型文件在如下位置:
