机器学习-感知机perceptron
转载自 拾毅者
在机器学习中,感知机(perceptron)是二分类的线性分类模型,属于监督学习算法。输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法 对损失函数进行最优化(最优化)。感知机的学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。感知机预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型。感知机由Rosenblatt于1957年提出的,是神经网络和支持向量机的基础。
定义
假设输入空间(特征向量)为X⊆Rn表示实例的特征向量,对应于输入空间的点;输出y∈Y表示示例的类别。由输入空间到输出空间的函数为
称为感知机。其中,参数w叫做权值向量weight,b称为偏置bias。w⋅x {+1−1if x>=0else 表示w和x的点积
sign为符号函数,即
在二分类问题中,f(x)的w和b值,即分离超平面(separating hyperplane)。如下图,一个线性可分的感知机模型
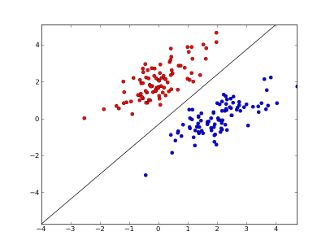
中间的直线即w⋅x+b=0这条直线。
线性分类器的几何表示有:直线、平面、超平面。
学习策略
核心:极小化损失函数。
如果训练集是可分的,感知机的学习目的是求得一个能将训练集正实例点和负实例点完全分开的分离超平面。为了找到这样一个平面(或超平面),即确定感知机模型参数w和b,我们采用的是损失函数,同时并将损失函数极小化。
对于损失函数的选择,我们采用的是误分类点到超平面的距离(可以自己推算一下,这里采用的是几何间距,就是点到直线的距离):
其中||w||范数。
对于误分类点(xi,yi)来说:
误分类点到超平面的距离为:
那么,所有点到超平面的总距离为:
不考虑1||w||,就得到感知机的损失函数了。
其中M为误分类的集合。这个损失函数就是感知机学习的经验风险函数。
可以看出,随时函数L(w,b)是连续可导函数。
学习算法
感知机学习转变成求解损失函数L(w,b)的最优化问题。最优化的方法是随机梯度下降法(stochastic gradient descent),这里采用的就是该方法。关于梯度下降的详细内容,参考wikipedia Gradient descent。下面给出一个简单的梯度下降的可视化图:
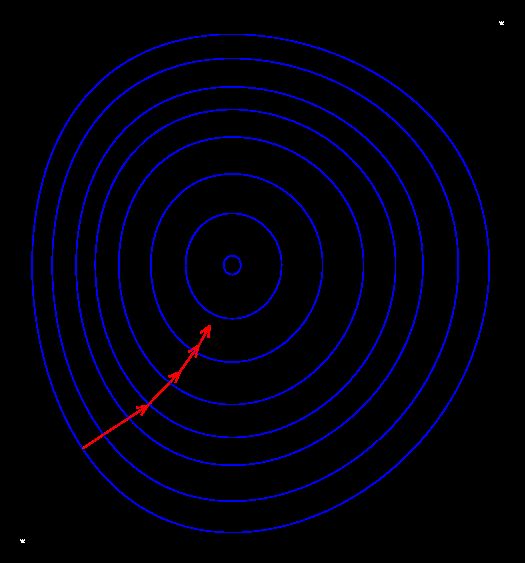
上图就是随机梯度下降法一步一步达到最优值的过程,说明一下,梯度下降其实是局部最优。感知机学习算法本身是误分类驱动的,因此我们采用随机梯度下降法。首先,任选一个超平面w0,然后使用梯度下降法不断地极小化目标函数
极小化过程不是一次使M中所有误分类点的梯度下降,而是一次随机的选取一个误分类点使其梯度下降。使用的规则为 θ:=θ−α∇θℓ(θ)的梯度通过偏导计算:
然后,随机选取一个误分类点,根据上面的规则,计算新的w,b,然后进行更新:
其中η不断减小,直至为0.
下面给出一个感知器学习的图,比较形象:

由于上图采取的损失函数不同,所以权值的变化式子有点区别,不过思想都是一样的。
算法描述如下:
算法:感知机学习算法原始形式
输入:T={(x1,y1),(x2,y2)...(xN,yN)}(其中xi∈X=Rn,yi∈Y={-1, +1},i=1,2...N,学习速率为η)
输出:w, b;感知机模型f(x)=sign(w·x+b)
(1) 初始化w0,b0,权值可以初始化为0或一个很小的随机数
(2) 在训练数据集中选取(x_i, y_i)
(3) 如果yi(w xi+b)≤0
w = w + ηy_ix_i
b = b + ηy_i
(4) 转至(2),直至训练集中没有误分类点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
解释:当一个实例点被误分类时,调整w,b,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超越该点被正确分类。
伪代码描述:

对于每个w⋅x其实是这样子的(假设x表示的是七维):
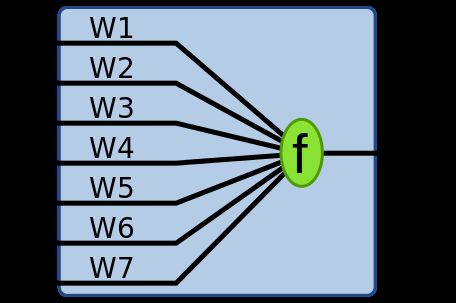
对于输入的每个特征都附加一个权值,然后将相加得到一个和函数f,最后该函数的输出即为输出的y值。
实例
正样本点:x1=(3,3)T
负样本点:x1=(1,1)T
求感知机模型f(x)=sign(w⋅x+b)
解答思路:根据上面讲解的,写初始化权值w和偏置b,然后一步一步的更新权值,直到所有的点都分正确为止。
解:
(1) 令w0=0,b0=0
(2) 随机的取一个点,如x1设置为1):
计算得到
得到一个模型
(3)接着继续,计算各个点是否分错,通过计算得到,x1和x2,误分了,所以修改权值:
得到线性模型:
一次下去,知道所有的点都有yi(w0⋅xi+b1)>0即可
……
……
……
最后求得
所以感知机模型为:
即我们所求的感知机模型。
小结
感知器Perceptron在机器学习当中是相当重要的基础,理解好感知器对后面的SVM和神经网络都有很大的帮助。事实上感知器学习就是一个损失函数的最优化问题,这里采用的是随机梯度下降法来优化。
好吧,对于感知机的介绍,就到此为止!在复习的过程中顺便做下笔记,搜搜资料,整理整理,也算是给自己一个交代吧。希望本文章能对大家能有点帮助。
References
[1] 统计学习方法, 李航 著
[2] Wikiwand之Perceptron http://www.wikiwand.com/en/Perceptron
[3] Wikipedia https://en.wikipedia.org/wiki/Machine_learning
新浪微博: @拾毅者