真香!Vision Transformer 快速实现 Mnist 识别

作者 | 李秋键
出品 | AI科技大本营(ID:rgznai100)
引言:基于深度学习的方法在计算机视觉领域中最典型的应用就是卷积神经网络CNN。CNN中的数据表示方式是分层的,高层特征表示依赖于底层特征,由浅入深抽象地提取高级特征。CNN的核心是卷积核,具有平移不变性和局部敏感性等特点,可以捕捉局部的空间信息。
在过去的10年间,CNN存在很大的优势,在计算机视觉领域被人们寄予厚望,引领了一个时代。但是卷积这种操作缺乏对图像本身的全局理解,无法建模特征之间的依赖关系,从而不能充分地利用上下文信息。此外,卷积的权重是固定的,并不能动态地适应输入的变化。因此,研究人员尝试将自然语言处理领域中的Transformer模型迁移到计算机视觉任务。
Vision Transformer也因此诞生,一种完全基于自注意力机制的图像分类方法。
相比CNN,Transformer的自注意力机制不受局部相互作用的限制,既能挖掘长距离的依赖关系又能并行计算,可以根据不同的任务目标学习最合适的归纳偏置,在诸多视觉任务中取得了良好的效果。
故今天我们将实现Pytorch搭建transformer模型实现Mnist手写字体识别,效果如下:


Transformer基本介绍
Transformer在计算机视觉领域能够迅速发展的原因:
(1)学习长距离依赖能力强。CNN是通过不断地堆叠卷积层来实现对图像从局部信息到全局信息的提取,这种计算机制显然会导致模型臃肿,计算量大幅增加,带来梯度消失问题,甚至使整个网络无法训练收敛。而Transformer自带的长依赖特性,利用注意力机制来捕获全局上下文信息,抽取更强有力的特征。
(2)多模态融合能力强。CNN使用卷积核来获取图像信息,但不擅长融合其他模态的信息(如声音、文字、时间等)。而Transformer的输入不需要保持二维图像,通常可以直接对像素进行操作得到初始嵌入向量,其他模态的信息转换为向量即可直接在输入端进行融合。
(3)模型更具可解释性。在Transformer的多头注意力结构中,每个头都应用独立的自注意力机制,这使得模型可以针对不同的任务在不同的表示子空间里学习相关的信息。
1.1 Transformer基本结构
(1)编码器-解码器
Transformer采用编码器-解码器架构,由分别堆叠了6层的编码器和解码器组成,是一种避免循环的模型结构。
编码器每个层结构包含两个子层,多头注意力层和前馈连接层。解码器有三个子层结构,mask多头注意力层,多头注意力层,前馈连接层。每个子层后面都加上残差连接和正则化层,结构如下图:
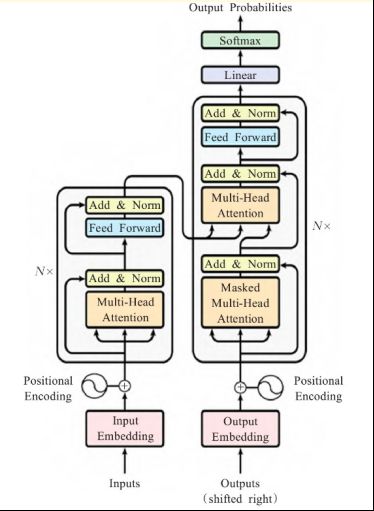
位置编码记录了序列数据之间顺序的相关性,相比较RNN顺序输入,Transformer方法可以直接将数据并行输入,并存储数据之间的位置关系,大大提高了计算速度,减少了存储空间。
(2)自注意力及多头注意力
注意力机制现在已成为神经网络领域的一个重要概念。其快速发展的原因主要有三个。首先,它是解决多任务较为先进的算法,其次被广泛用于提高神经网络的可解释性,第三有助于克服RNN中的一些挑战,如随着输入长度的增加导致性能下降,以及输入顺序不合理导致的计算效率低下。而自注意力机制是注意力机制的改进,其减少了网络对外部信息的依赖,更擅长捕捉数据或特征内部的相关性。
Transformer架构引入自注意力机制,避免在神经网络中使用递归,完全依赖自注意力机制来绘制输入与输出之间的全局依赖。通过使用缩放点积注意力(scaled dot-product attention),相比一般的注意力,缩放点积注意力使用点积进行相似度计算,在实际中会更快更节省空间。在计算时,需要将输入通过线性变换得到矩阵Q(查询)、K(键值)、V(值)。
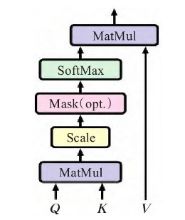
(3)位置特征编码模块
使用0到9表示分割后的小图像位置编号,并且每个位置设置一个可训练的随机变量,通过梯度下降法获得位置向量。包括以及模块代码可见。
1.2 Vision Transformer基本结构
为了将图像转化成Transformer结构可以处理的序列数据,Vision Transformer引入了图像块(patch)的概念。首先将二维图像做分块处理,每个图像块展平成一维向量,接着对每个向量进行线性投影变换,同时引入位置编码,加入序列的位置信息。此外在输入的序列数据之前添加了一个分类标志位,更好地表示全局信息。ViT模型通常在大型数据集上预训练,针对较小的下游任务进行微调。在ImageNet数据集上,VIT以88.55%的准确率超越了EfficientNet模型,成功打破了基于卷积主导的网络在分类任务上面的垄断,比传统的CNN网络更具效率和可扩展性。
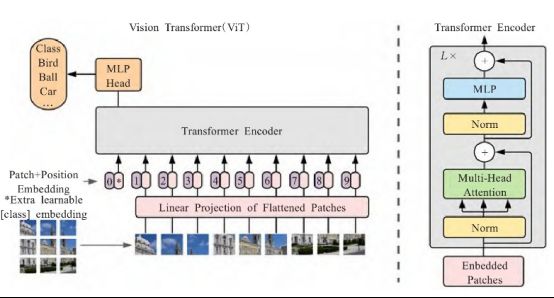

模型搭建
为了从代码层面理解模型,下面用pytorch简单搭建手写字体识别模型。
这里程序的设计分为以下几个步骤,分别为模块构建、模型搭建以及训练等几个步骤。
2.1 模块构建
这里使用到的模块包括:残差模块,放在每个前馈网络和注意力之后;layernorm归一化,放在多头注意力层和激活函数层,用绝对位置编码的BERT,layernorm用来自身通道归一化;FeedForward放置多头注意力后,因为在于多头注意力使用的矩阵乘法为线性变换,后面跟上由全连接网络构成的FeedForward增加非线性结构;多头注意力层,多个自注意力连起来。使用qkv计算。
代码如下:
#残差模块,放在每个前馈网络和注意力之后
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
#layernorm归一化,放在多头注意力层和激活函数层。用绝对位置编码的BERT,layernorm用来自身通道归一化
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
#放置多头注意力后,因为在于多头注意力使用的矩阵乘法为线性变换,后面跟上由全连接网络构成的FeedForward增加非线性结构
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, dim)
)
def forward(self, x):
return self.net(x)
#多头注意力层,多个自注意力连起来。使用qkv计算
class Attention(nn.Module):
def __init__(self, dim, heads=8):
super().__init__()
self.heads = heads
self.scale = dim ** -0.5
self.to_qkv = nn.Linear(dim, dim * 3, bias=False)
self.to_out = nn.Linear(dim, dim)
def forward(self, x, mask = None):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x)
q, k, v = rearrange(qkv, 'b n (qkv h d) -> qkv b h n d', qkv=3, h=h)
dots = torch.einsum('bhid,bhjd->bhij', q, k) * self.scale
if mask is not None:
mask = F.pad(mask.flatten(1), (1, 0), value = True)
assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'
mask = mask[:, None, :] * mask[:, :, None]
dots.masked_fill_(~mask, float('-inf'))
del mask
attn = dots.softmax(dim=-1)
out = torch.einsum('bhij,bhjd->bhid', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out2.2 模型搭建
构建原始Transformer代码,然后构建VIT将图像切割成一个个图像块,组成序列化的数据输入Transformer执行图像分类任务。
代码如下:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3):
super().__init__()
assert image_size % patch_size == 0, 'image dimensions must be divisible by the patch size'
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.transformer = Transformer(dim, depth, heads, mlp_dim)
self.to_cls_token = nn.Identity()
self.mlp_head = nn.Sequential(
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Linear(mlp_dim, num_classes)
)
def forward(self, img, mask=None):
p = self.patch_size
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p)
x = self.patch_to_embedding(x)
cls_tokens = self.cls_token.expand(img.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding
x = self.transformer(x, mask)
x = self.to_cls_token(x[:, 0])
return self.mlp_head(x)2.3 模型训练
patch大小为 7x7(对于 28x28 图像,这意味着每个图像 4 x 4 = 16 个patch)、10 个可能的目标类别(0 到 9)和 1 个颜色通道(因为图像是灰度)。
在网络参数方面,使用了 64 个单元的维度,6 个 Transformer 块的深度,8 个 Transformer 头,MLP 使用 128 维度。
代码如下:
model = ViT(image_size=28, patch_size=7, num_classes=10, channels=1,
dim=64, depth=6, heads=8, mlp_dim=128)
optimizer = optim.Adam(model.parameters(), lr=0.003)
train_loss_history, test_loss_history = [], []
for epoch in range(1, N_EPOCHS + 1):
print('Epoch:', epoch)
train_epoch(model, optimizer, train_loader, train_loss_history)
evaluate(model, test_loader, test_loss_history)
print('Execution time:', '{:5.2f}'.format(time.time() - start_time), 'seconds')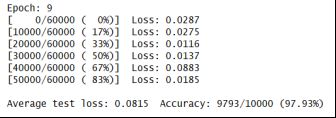
完整代码:
链接:
https://pan.baidu.com/s/1myFLjiTwgQe8z9WYVONntA
提取码:sbjm
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。

往
期
回
顾
技术
Pandas&SQL语法归纳总结
资讯
Nginx宣布在俄罗斯禁止贡献
资讯
2022人工智能开启未来新密码
技术
一行Python代码能干嘛?来看!

分享
![]()
点收藏

点点赞

点在看