Mysql知识网络(持续更新)
Mysql知识网络(持续更新)
前言
好记性不如烂笔头。最近学习了MYSQL的相关知识,方便以后复习以及知识点查询,记录一些知识点。本文通过基础知识+mysql优化+实战经验进行总结。也会分享一些自己在工作中遇到的一些mysql问题以及优化。本文大部分资料是参考极客时间丁奇老师的 《MYSQL实战45讲》、mysql官方文档、一代神书 《高性能mysql》(Baron Schwartz,Peter Zaitsev,Vadim Tkachenko 著,宁海元,周振兴,彭立勋 等 译)。若文中有疑问和知识点错误欢迎大佬们进行指正。
版本更新
第一版(2022.03.13)开始编辑整理MYSQL基础知识
第一节mysql基础架构
引用数据库大佬丁奇(网名)的一句话:看一个事儿千万不要直接陷入细节里,你应该先鸟瞰其全貌,这样能够帮助你从高维度理解问题。在学习mysql之前,我们一起看看mysql的基础架构示意图:
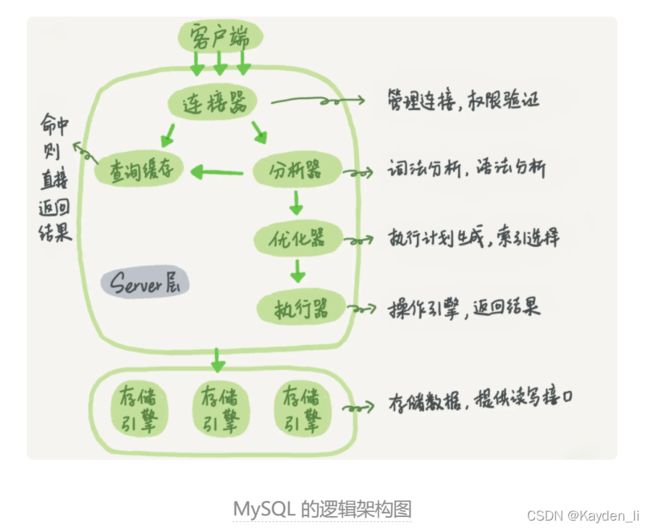
mysql大体上可以分为server层和存储引擎层。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
server层主要对sql语句进行预处理,sql语句经过预处理之后到达存储引擎。server会做那些预处理呢?
如mysql基础架构图所示,一条sql语句在到存储引擎执行前会在server层做一些预处理。现在我们一起看看会执行那些预处理。
一条sql的执行流程:
1、当客户端发送一条sql到server层,首先需要和数据库建立一个连接,这里就需要用到连接器。在连接器里会对请求的账号进行身份、权限校验,当身份和权限校验通过后,就会进行下一步;
2、通过了连接器校验,sql语句来到分析器,分析会对sql语句进行词法分析、语法分析。如果发现sql语句错误将会直接报错返回。
3、通过了分析器后,说明这个语句是一个正确且可执行的sql语句。在优化器里,会对sql进行优化处理,当在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。最终确定一个mysql自认最优的执行方案到执行器。
4、在执行器中,首先会对用户再做一次鉴权,确定这个用户是否对该表有没有执行查询的权限。如果有权限就会开始执行语句,取出满足sql的结果集返回给客户端。
大家可能会问架构图里面不是还有一个查询缓存么,为什么没有这一步骤呢?
这里单独谈谈查询缓存,实际上在mysql 8.0版本之前是会有查询缓存这一步的:
通过连接器后会来到查询缓存或者分析器。之前执行过的语句及其结果会通过key-value对的形式直接缓存在内存中。如果缓存中查询到这个语句就直接返回了。如果没有查询到缓存就会到分析器了。
查询缓存在mysql 8.0版本后就已经删除了这一功能(官方通告:MySQL 8.0: Retiring Support for the Query Cache)。
因此8.0版本之前都是可能会有这一流程,但是绝大部分DBA都会选择把他关掉:将参数query_cache_type 设置成 DEMAND。
知道了一条sql语句的执行流程,我们再来细看一下mysql的各个组件。
连接器
连接器负责和客户端建立连接、获取权限、维持和管理连接。
连接命令:
mysql -h$ip -P$port -u$user -p
在完成TCP握手后,连接器就会开始认证身份(输入的用户名和账号):
- 如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
- 如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
连接器建立连接的过程其实是比较复杂的,所以需要合理的控制连接时间。
长连接问题:
全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这个问题呢?
- 你可以考虑以下两种方案。定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。可以调整参数 wait_timeout,如果休闲太久自动断开连接。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
短连接风暴
正常的短连接模式就是连接到数据库后,执行很少的 SQL 语句就断开,下次需要的时候再重连。如果使用的是短连接,在业务高峰期的时候,就可能出现连接数突然暴涨的情况。
在数据库压力比较小的时候,这些额外的成本并不明显。但是当这些短连接的请求都是慢sql,连接数就会暴涨,并且系统的负载和消耗的cpu资源也会一下子就上来了。可能短时间内业务不可用。
遇到这种问题怎么处理呢?以下是参考丁奇老师的解决办法,但是注意都是有损的。
第一种方法:先处理掉那些占着连接但是不工作的线程。
max_connections 的计算,不是看谁在 running,是只要连着就占用一个计数位置。对于那些不需要保持的连接,我们可以通过 kill connection 主动踢掉。这个行为跟事先设置 wait_timeout 的效果是一样的。设置 wait_timeout 参数表示的是,一个线程空闲 wait_timeout 这么多秒之后,就会被 MySQL 直接断开连接。
如果是连接数过多,你可以优先断开事务外空闲太久的连接;如果这样还不够,再考虑断开事务内空闲太久的连接。第二种方法:减少连接过程的消耗。
有的业务代码会在短时间内先大量申请数据库连接做备用,如果现在数据库确认是被连接行为打挂了,那么一种可能的做法,是让数据库跳过权限验证阶段。
跳过权限验证的方法是:重启数据库,并使用–skip-grant-tables 参数启动。这样,整个 MySQL 会跳过所有的权限验证阶段,包括连接过程和语句执行过程在内。
在 MySQL 8.0 版本里,如果你启用–skip-grant-tables 参数,MySQL 会默认把 --skip-networking 参数打开,表示这时候数据库只能被本地的客户端连接。可见,MySQL 官方对 skip-grant-tables 这个参数的安全问题也很重视。
以上是丁奇老师从数据库层面上提出的解决办法,除了在数据库层面上,在进入数据库之前我们也可以做一些拦截。常见的:
1、对接口url进行限流。如果遇到恶意攻击,对某一个慢查询进行频繁请求,我之前遇到过一次,用户账号被盗,恶意攻击,1秒内请求了14000次。第一次攻击是在业务低峰区攻击了大概20分钟,当时是月初,很多报表做导出,以为是所有客户都在一起去了没有分析请求的详细信息,只是观察让数据库直接抗过去了,后面在业务高峰期,又出现了一次攻击,这次直接把服务器拉胯了。mysql 内存和cpu负载暴涨,导致mysql一直在重启。分析后发现是被恶意攻击,同一用户1秒内请求了14000次。这种情况对该请求接口进行url用户级限流,就是一个用户一次请求没有请求完不允许再次请求。这个限流策略后续再谈。
2、利用mybatis的二级缓存、redis缓存;将一些高频请求缓存下来降低‘’数据库的压力。本文主要讨论mysql相关,关于redis缓存方案后续再谈。
查询缓存
虽然在mysql 8.0版本之后取消了缓存。但是我们还是要谈谈缓存,因为很多公司目前使用的还是5.17-8.0之间的版本。
这里我直接引用丁奇老师的讲解解释一下:
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?
因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
好在 MySQL 也提供了这种“按需使用”的方式。你可以将参数 **query_cache_type 设置成 DEMAND,这样对于默认的 SQL 语句都不使用查询缓存。**而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:
mysql> select SQL_CACHE * from T where ID=10;
为什么不用缓存了呢?
总结就是五个字:基本用不到。
分析器
分析器还是比较单纯的,一条语句过来了先进行“词法分析”,把表名、字段、语法、关键词分析出来,然后进行mysql 语法分析,判断是否是mysql语法,表名、库名、字段是否存在。如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接“use near”的内容。目前我还没遇到过分析器出一些比较奇怪的幺蛾子的事情。
优化器
优化器是在优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
一般介绍的字越少,问题越大。看似很简单,但是优化器的作用是非常大的,一旦优化器选错了索引,查询效率马上就变了。
优化器是怎么选择索引的呢?
- 这一块篇幅比较多,后续补
执行器
执行器还是比较简单的,我们先看看执行器的流程:
例如执行下列语句:select * from T where ID=10; (T表示InnoDB引擎)
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
但是执行器真的就这么简单么?
来到执行器,就不得不谈一谈执行顺序和执行计划。
先说说mysql的执行顺序:
mysql执行sql的顺序从 From 开始,以下是执行的顺序流程
1、FROM table1 left join table2 on 将table1和table2中的数据产生笛卡尔积,生成Temp1
2、JOIN table2 所以先是确定表,再确定关联条件
3、ON table1.column = table2.column 确定表的绑定条件 由Temp1产生中间表Temp2
4、WHERE 对中间表Temp2产生的结果进行过滤 产生中间表Temp3
5、GROUP BY 对中间表Temp3进行分组,产生中间表Temp4
6、HAVING 对分组后的记录进行聚合 产生中间表Temp5
7、SELECT 对中间表Temp5进行列筛选,产生中间表 Temp6
8、DISTINCT 对中间表 Temp6进行去重,产生中间表 Temp7
9、ORDER BY 对Temp7中的数据进行排序,产生中间表Temp8
10、LIMIT 对中间表Temp8进行分页,产生中间表Temp9
看完执行顺序,我们再看看执行计划。
什么是执行计划?
执行计划就是提前看看执行过程中使用哪一个索引,mysql是怎么处理sql语句的,大概扫描命中(精度在80%-95%)的结果集。通常我们可以通过explain+ sql语句查看执行计划。
关于执行计划的详细内容可以查看官方文档。
这里我大概说下执行计划中包含的信息。
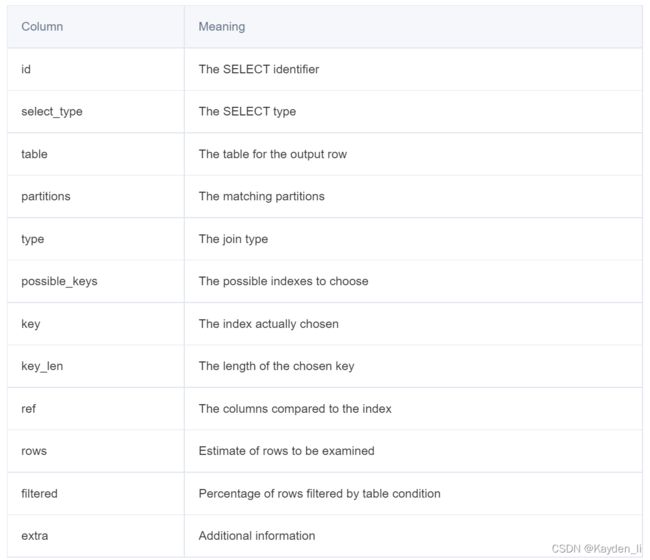
这里我大概挑几个比较工作中比较常用做解释。
- id:select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。关于id会遇到三种情况:
- 如果id相同,那么执行顺序从上到下;
- 如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行;
- id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行。
总结一句话就是id大的先执行,相同的从上往下执行。
- select_type:用来分辨查询的类型,是普通查询还是联合查询还是子查询。
- type:type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下,访问的类型有很多,效率从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
我们要尽量控制在rang往上的等级,最好能达到ref级。
4.possible_keys: 显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
5. key:实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠。
6.rows:根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好。精度大概在80%-95%。
7.extra:
–using filesort:说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置
explain select * from emp order by sal;
–using temporary:建立临时表来保存中间结果,查询完成之后把临时表删除
explain select ename,count() from emp where deptno = 10 group by ename;
–using index:这个表示当前的查询时覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表名索引被用来执行索引键值的查找,如果没有,表面索引被用来读取数据,而不是真的查找
explain select deptno,count() from emp group by deptno limit 10;
–using where:使用where进行条件过滤
explain select * from t_user where id = 1;
–using join buffer:使用连接缓存,情况没有模拟出来
–impossible where:where语句的结果总是false
explain select * from emp where empno = 7469;
大家可以看到执行顺序最开始是由from开始的,当from执行完之后才会执行剩下的语法。并且执行计划中id越大的会先执行。所以这里有一种mysql优化方法。
合理使用子查询
当开发中遇到一些慢sql,由于业务不是很熟悉,并且必须马上优化,可以考虑下优先使用子查询,可以考虑在from、join 或者 on 后面使用子查询。建议添加1到2个子查询就可以了。这样有什么好处呢?
合理添加子查询,提前缩小结果集。当后续再执行join的时候关联的数量提前就缩小了,特别是遇到有order by、group by和limit ,提前缩小结果集,这样在后续order by、group by和limit操作的时候就提高在内存处理的概率。
这个操作遇到紧急情况真是百试百爽。工作中之前遇到一个慢sql,某一天服务高峰期,这个sql跑起来直接导致整个服务很慢,当时就需要优化,但是业务又不熟悉。这时候咋办呢?
第一:分析这个sql是用来干嘛的,大概看了一下是一个报表服务正在被导出,因为使用到了很多基础数据,所以关联了很多基础资料表杂七杂八的一共关联了10张表。(不得不吐槽最开始的表设计一定要有前瞻性,根据业务做一些合理冗余,缓存查询)关联10张表并且基础资料都是大表(当时还没分库分表),这样的sql光执行就要2分钟。
第二:合理添加子查询:由于对业务不太熟悉,不敢改动代码,只能调整sql。根据分析,添加关联主要是有某几个高频字段需要用到高级查询所以多关联了几张表。并且有一些where条件是必传值。所以当时把where条件和高频join放到from后面做一次子查询提前缩小结果集。后面优化出来sql大概2s。
不过这个那些join需要放到子查询里面这里就需要不断的看执行计划,对子查询调优,并且不影响原业务。原则就是让这个sql尽量在内存中处理。
小节
本节主要介绍了mysql的基础逻辑架构,和一个sql语句的执行流程是怎么样的。同时分别介绍了连接器、查询缓存、分析器、优化器、执行器的作用。