FCN:使用端到端CNN进行语义分割的开山之作
今天和大家分享一篇发表在CVPR2015上的文章:

代码地址:https://github.com/shelhamer/fcn.berkeleyvision.org
FCN可以说是使用CNN进行语义分割的一篇里程碑式的文章,作者通过对当时几种比较流行的分类网络(AlexNet、VGG、GoogLeNet)做一些结构调整,将其应用到了语义分割任务中。
0.动机
语义分割任务是对输入图片中的每个像素进行分类,将组成同一类物体的像素分为同一类别,输入图像和语义分割结果如下图所示,下图第二列中相同颜色的像素属于同一类别。

使用CNN完成语义分割任务,要求网络的输出feature map尺寸要与输入图片分辨率一致,这样才能在输出feature map中找到输入图片中每个像素所属的类别。
CNN在分类任务上有很好的性能,作者想以用于分类的CNN为基础,构建一个端到端的语义分割网络。
在分类任务中,网络最后一层的输出往往与任务的类别数量紧密相关,与输入图片分辨率无关,因为全连接层有着固定的维度,全连接层丢弃了空间坐标信息。
可以将全连接层看作卷积层,该卷积层的卷积核尺寸与该层输入feature map尺寸一致,因此带有全连接层的分类网络可以很容易地转换为全卷积网络。如下图所示:

上图中上半部分为用于分类的CNN,它的输出为用于表示分类结果的向量;下半部分为将全连接层转换为卷积层后网络,可以看到网络的输出是带有空间属性的,并没有舍弃空间坐标信息。
作者希望在已经训练好的分类网络基础上,进行结构上的调整,使得网络输出feature map的尺寸与输入图片尺寸相同,这样网络就能得到输入图片中每个像素的类别,从而完成语义分割任务。
1.全卷积网络
作者以在ImageNet数据集上训练好的AlexNet、VGG16、GoogLeNet这3个分类网络为基础,砍掉GoogLeNet中最后面的average pooling层和这3个网络最后面的分类层;将原网络中所有的全连接层转换为卷积层,并加入 1 × 1 1 \times 1 1×1卷积层,输出21个通道的特征,每个通道的特征对应于PASCAL数据集中的1个类别,然后使用反卷积层(deconvolution layer)将这21个通道的特征进行上采样,使得最终输出的feature map与输入图像分辨率一致。
一个简洁的网络结构示意图如下图所示:

在PASCAL数据集上微调网络权重,进行语义分割任务,在训练时使用了逐像素的多类别逻辑回归损失。在PASCAL验证集上测试这3个网络的性能,结果如下表所示:
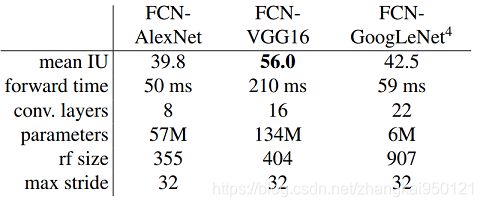
上表中的“rf size”表示一个输出元素对应于输入图像的感受野尺寸,“max stride”表示网络内部累积最大的步长值。
从上表中可以看出,FCN-VGG16在语义分割任务中达到了比较好的性能。由于在修改后的网络结构中不包含全连接层,因此它们属于全卷积网络(FCN,Fully Convolutional Network)。
2.跳接
使用上文中设计的网络进行语义分割,得到的结果比较粗糙。因为在网络中存在着多个下采样操作,使得网络中间特征尺寸远小于输入图像分辨率,虽然最后有Deconv层将特征上采样至与输入图像相同的尺寸,仍会导致输出结果中细节不够丰富。
为了解决这个问题,作者在上文中所述的FCN基础上加入了跳接(skip),最终网络结构如下图所示:

上图中使用网格表示某个步骤会使得feature map尺寸变小,网格的数量表示feature map尺寸,其他中间特征使用竖线简略表示。
在第1小节中所述的最基础的FCN即为上图中第一行的结构,即“一卷到底+实现32x上采样的Deconv”,这种网络结构会使得输出结果比较粗糙。作者将该结构称作FCN-32s。
作者尝试在pool4层后面加入 1 × 1 1 \times 1 1×1卷积操作,输出像素的预测类别,然后与conv7进行2x上采样后的结果相加,最后进行16x的上采样操作得到最终分割结果。作者将这个网络称作FCN-16s,该网络中完成2x上采样操作的Deconv权重由双线性插值初始化,其余权重以FCN-32s的参数进行初始化,进行端到端训练。
作者又尝试将pool3的特征与pool4进行2x上采样的结果、conv7进行4x上采样的结果进行融合,最后进行8x上采样,得到最终结果。作者将这个网络称作FCN-8s。
FCN-32s、FCN-16s、FCN-8s这3种网络结构的输出结果如下图所示:

从上图中可以看出,融合浅层的特征,能够得到更细腻的分割结果。因为相比于网络深层,网络浅层存在更多细粒度的、底层的特征。
在实现过程中,上采样操作均由Deconv层实现。网络中最后一个Deoncv层固定为双线性插值操作,其余Deconv层使用双线性插值参数进行初始化,以此为基础进行训练得到最终参数。
3.实验结果
上文中提到的性能最好的FCN-8s在PASCAL数据集上的性能如下表所示:
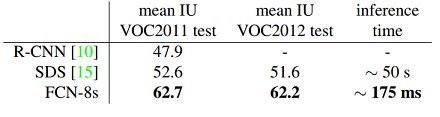
从上表中可以看到,FCN-8s有更高的性能,且耗时远小于其他方法。
下图比较了FCN-8s和SDS方法的语义分割可视化结果:

从上图中可以看出,对于不同场景,FCN-8s的结果都优于SDS方法。
4.总结
作者以分类网络为基础,通过将全连接层转换为卷积层、增加跳接(skip)的方式,构建了用于语义分割任务的、端到端训练的卷积神经网络FCN。
FCN提高了语义分割的性能,它的出现为语义分割任务的实现开辟了新思路,推动了使用CNN解决语义分割任务的进程。
推荐阅读
ResNet从理论到实践(一)ResNet原理
ResNet从理论到实践(二)使用ResNet18进行猫狗分类
ResNet变体:ResNeXt