Inconsistency-aware Uncertainty Estimation for Semi-supervised Medical Image Segmentation
2021 IEEE Transactions on Medical Imaging(TMI)
语义分割、医学图像分割论文
目录
前言
一、主要亮点
二、理论方法
1. Problem Analysis
1.1 two cost-sensitive settings
1.2 Certain region and Uncertain region
2. 网络框架
2.1 main framework of CoraNet
2.2 Certainty-aware Prediction: CRM
2.3 Separate Self-training: C-SN and UC-SN
3. 算法流程
三、实验部分
1.CRM的有效性
2. Separate Self-training: Changing trend of Uncertainty
3. 对比实验
4. 消融实验
总结
前言
大多数之前的半监督分割模型由两个阶段组成:
- 伪标签初始化——仅在可用的标记训练样本上训练一个初始分割模型,然后使用得到的初始模型预测未标记样本的伪标签(即初始分割);
- 联合训练标记样本和未标记样本——在标记样本及其ground truth和未标记样本及其伪标签上联合训练最终的半监督分割模型。
softmax-based confidence:大多数遵循相同的方法来估计未标记样本的“不确定性”——像素/体素的熵值越高,不确定性就越高。这种不确定性的方法通过在softmax层设定一个阈值来给伪标签提供线索。
需要解决的两个问题:
- 如果第一步得到的伪标签不够准确,势必会使后续的分割较差。如果得到一个较好的伪标签呢?Can we investigate a novel method of estimating “uncertainty”?
- “并非所有区域都会受到平等对待”。在以前semi-supervised分割,对未标记样本,通常都是确定的区域(高置信度)和不确定的区域(低置信度)输入到相同的分割网络作为输入,这可能不仅呈现很难充分利用某些地区,也低估了不确定区域的复杂性。我们能否在一个统一的框架中单独对待它们的细分?
一、主要亮点
- 模型
- 保守-激进模块(CRM),它涉及并维护一个主分割模型,通过预测不同误分类成本之间的不一致性来表示确定和不确定区域掩码;
- 利用特定区域分割网络(C-SN)对预测的特定区域进行模型更新;
- 不确定区域分割网络(UC-SN)对预测的不确定区域进行分割并对模型进行更新。
- 创新点
- 半监督分割框架与一种估计像素不确定性的新方法;
- 基于不同误分类代价之间的不一致性预测,提出了一种新的保守根式模块来自动识别不确定区域;
- 一种训练策略,以不同的方式分别处理特定和不确定区域的分割。
Remark. 总之,我们提出的方法与之前的半监督分割方法有很大的不同。利用半监督学习,之前的这些方法通常是基于EM或基于CR的方法,所以基于EM或CR架构,它们通常会引入额外的基于一致性的约束,例如基于输出的一致性[18][42][44][56]或基于任务的一致性[37][59]。相比之下,我们的方法在以下方面非常新颖:1)提供区域级掩码,以表明我们提出的CRM中的某些/不确定区域;2)通过结合基于CR(consistency regularization )和基于EM(entropy minimization)架构的优点来训练后续的分割模块。据我们所知,上述两个方面在以往的著作中都没有被研究过。
二、理论方法
1. Problem Analysis

1.1 two cost-sensitive settings
- Object conservative setting (e.g., 5:1):将一个背景像素错分割为对象类的代价与将五个对象像素错分割为背景类的代价相等。显然,它以对象谨慎的方式执行分割,因为在大多数情况下,只分割对象最可靠的中心部分。在此设置中,对象保守设置下的预测对象类是高度自信的。很直观的理解就是保守网络得到的预测图区域基本都在ground truth区域内部,一般小于ground truth,可从fig1观察到。
- Object radical setting (e.g., 1:5):我们在目标保守的情况下逆转误分类代价。错误分割一个对象像素到背景类的代价相当于错误分割五个背景像素到对象类的代价。这是一个背景警告设置,表示预测的背景是高度自信的。很直观的理解就是激进网络得到的预测图区域基本大于ground truth区域,一般要超出ground truth。
1.2 Certain region and Uncertain region
通过保守网络和激进网络可以得到相应的保守分割掩码和激进分割掩码。我们计算这两个分段掩码的差值来定义Certain region and Uncertain region:
- 特定区域:在保守和激进设置下具有相同预测的像素,因为它们对不同的成本具有鲁棒性。
- 不确定区域:保守和激进设置下预测不同的像素,表示当前预测不确定。
2. 网络框架
2.1 main framework of CoraNet
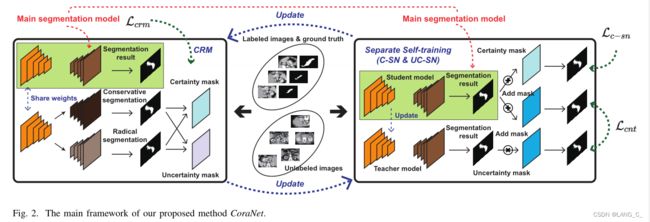
整体网络框架分为两部分,左边是两个共享的编码器和三个相互独立的解码器,右边是一对常用的半监督网络teacher student network,依次更新。
2.2 Certainty-aware Prediction: CRM
该模块最终的目的就是通过三个解码器D得到保守型和激进型预测掩码E,以及基础预测Y。
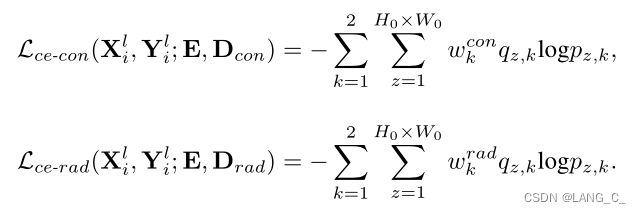
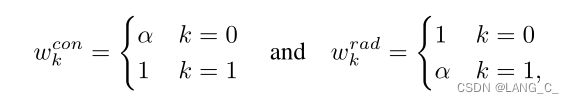
 设置为5,
设置为5,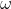 是交叉熵的权重,当计算ce-con,如果预测时k=0,代表是背景的预测,此时为5,预测时k=1,代表是前景的预测,此时为1,对背景的预测损失相对就大很多(eg:不考虑时,因为k=0时,q越接近1,ce loss越小,反之越大,k=1时同理。所以5倍的loss会更大)
是交叉熵的权重,当计算ce-con,如果预测时k=0,代表是背景的预测,此时为5,预测时k=1,代表是前景的预测,此时为1,对背景的预测损失相对就大很多(eg:不考虑时,因为k=0时,q越接近1,ce loss越小,反之越大,k=1时同理。所以5倍的loss会更大)
文章中将其表示为high misclassification cost高误分类成本

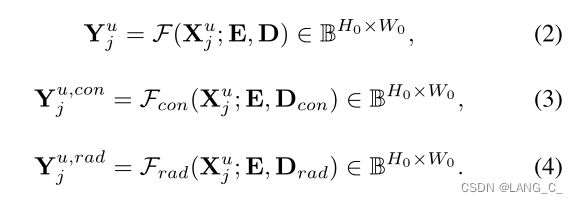
根据得到的保守性和激进性预测,可以将第j个未标记图像![]() 和
和![]() 的确定掩码和不确定掩码定义为
的确定掩码和不确定掩码定义为

其中⊕为像素异或算子 ,得到的是不确定的掩码,取反则是确定掩码
2.3 Separate Self-training: C-SN and UC-SN
C-SN for certain region segmentation :
联合伪标签和确定区域的掩码来求交叉熵损失来训练调整E和D的参数,增强其鲁棒性。

UC-SN for uncertain region segmentation:
由于不确定区域预测的置信度较低,不能直接将其作为伪标签,因此我们引入了之前提出的深度半监督学习框架来实现可靠的伪标签分配,获得一致性损失。![]() 和
和![]() 分别是学生网络和教师网络。教师网络随学生网络移动指数加权平均更新参数。
分别是学生网络和教师网络。教师网络随学生网络移动指数加权平均更新参数。
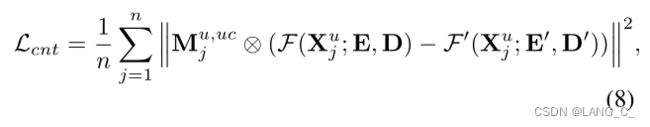
3. 算法流程

我的理解是先用有标签的图片训练好网络![]() ,
, ,
,![]() ,
,![]() ,再用无标签图片生成伪标签和确定区域和不确定区域掩码图,利用这些再去训练
,再用无标签图片生成伪标签和确定区域和不确定区域掩码图,利用这些再去训练![]() ,。其中不确定区域的掩码图只在求正则化损失时 解释的比较笼统,细节还是要看论文。
,。其中不确定区域的掩码图只在求正则化损失时 解释的比较笼统,细节还是要看论文。![]()
![]() 只在有标签图片上更新。
只在有标签图片上更新。
三、实验部分
在三个不同的医学图像分割任务上评估我们的方法,即CT胰腺分割、MR心内膜分割和ACDC分割。
1.CRM的有效性
将softmax后的概率与0.5,0.7,0.9相比。大于阈值的作为高置信度。


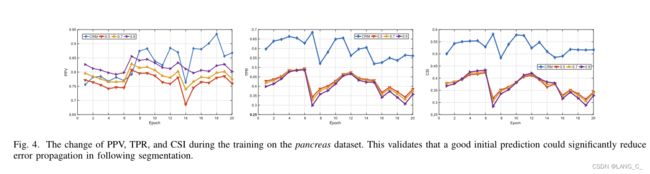
将不同方法生成的伪标签加入到胰腺分割的训练中(即自我训练)。我们在图4中报告了所有这些设置的不同曲线变化,这表明尽管我们方法的PPV在第一个周期低于这些基线,但当训练周期增加时,PPV会提高。此外,我们还可以看到,0.5、0.7和0.9的设置具有相似的趋势,0.5的设置在TPR中表现更好,0.9的设置在PPV中表现更好。
2. Separate Self-training: Changing trend of Uncertainty
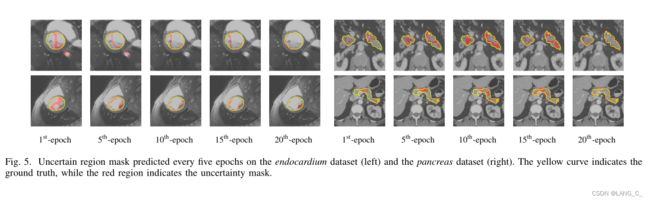
黄色曲线表示ground truth,红色区域表示不确定性掩码。可以观察到不确定性掩模在训练过程中发生变化。一开始,不确定度掩模通常位于前景中部的硬区域,CRM预测结果不一致。随着训练epoch的增加,当模型对前一个不确定区域的置信度增加时,不确定掩模就会位于某个边界区域。这一经验观察表明,不确定区域可能会随着分割模型的演变而变化。由于不确定性可能会改变,这也提醒我们不能总是盲目地将边界区域视为不确定区域。
3. 对比实验


4. 消融实验

- seg:仅在公式(1)中使用主要损失Lcrm的模型。
- seg+st:主要分割损失和自我训练损失。这意味着我们在CRM中不使用不确定性掩模,而是直接对未标记样本进行自我训练。
- seg+st (mask):主分割损耗和自训练损耗。需要注意的是,这种自我训练损失是根据CRM中的掩码只在特定区域上计算的,这说明不确定区域没有参与到训练过程中。
- seg+mt:主要分割损失和平均教师损失。这里,我们在CRM中不使用不确定掩码,这意味着该设置直接在未标记的样本上使用mean teacher。
- seg+mt (mask):主要分割损失和平均教师损失。需要注意的是,不确定区域并不参与训练过程。
- 我们的整体方法,包括提出的CRM和单独的自我训练损失。
实验部分太多了,是真的多,就不一一放上去了。。。
总结
-
实验证明CRM能得到一个较好的初始预测,这对后续的分割都很有帮助,因为良好的初始预测有助于减少误差传播,保证学习过程的相对稳定性
。 -
作者提出一种新的方法,通过捕获多个成本敏感设置之间的不一致预测来估计不确定性。我们对不确定性的定义直接依赖于分类输出,而不需要任何预定义的边界感知假设。在此基础上,我们提出了一种单独的自我训练策略,以区别对待特定区域和不确定区域。为了实现端到端训练,我们开发了三个组件,即CRM, C-SN和UCSN来训练我们的半监督分割模型。