支持向量机(SVM)
文章目录
- SVM的分类
-
- 线性可分SVM
- 线性SVM
- 非线性SVM
- SVM原理
-
- 超平面
- 支持向量
- 构造分割面
- 目标函数
- 松弛因子
- 损失函数
- 核函数
- Iris数据分类代码
- 总结
支持向量机(Support Vector Machine)是一种十分常见的分类器,曾经火爆十余年,分类能力强于NN,整体实力比肩LR与RF。核心思路是通过构造分割面将数据进行分离。本文主要阐述SVM的基本工作原理和简单应用。
SVM的分类
线性可分SVM
线性可分SVM的原理是要达到硬边界最大化。这里的线性可分是指,当我们想用一个分割平面,将两个数据分割开时,存在至少一个分割面,使两个数据可以完全分离,则我们认为这个SVM是线性可分SVM。
线性SVM
线性SVM是指,分割面虽然不能完全分割所有数据,但是该线性分割方式可以使绝大多数数据正确的被分类。那么这样的SVM也可以被称为线性SVM。线性SVM要达到的是软边界最大化。这里的“软”对应线性可分SVM的“硬”。硬边界指的是支持向量到分割面的距离,因为支持向量距离分割面最近,该距离也是过渡带宽度(的一半)。而软边界指的是,当SVM不是线性可分的情况时,此时支持向量并不一定是距离分割面最近的向量。因此SVM此时并不能一味地边界最大化,而是使过渡带足够宽。此时的边界最大化并不是真正意义上的,严格的边界最大化。所以用软进行区分。
非线性SVM
对于前两种SVM,对其加入一个核函数就可以构造出非线性SVM。
SVM原理
超平面
在二维空间里,对于一条直线: w 1 x 1 + w 2 x 2 + b = 0 w_1x_1+w_2x_2+b=0 w1x1+w2x2+b=0, ( w 1 , w 2 ) (w_1, w_2) (w1,w2)实际上就是直线的法线方向。如果我们代入 ( x 1 , x 2 ) (x_1, x_2) (x1,x2)到等式左边,则当该式大于0时,点 X X X在法线正方向上,小于0时则在法线负方向上,等于0则在法线上。将这一性质应用于更高维度的话,此时点 X X X就是一个 n n n维向量,而这条直线也就变为超平面了。
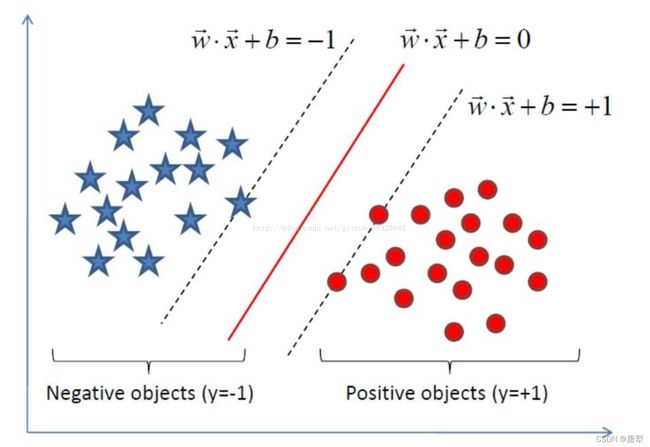
支持向量
支持向量怎么选择?以线性可分SVM为例,我们将 w w w认为是若干样本线性组合得到的,第 1 1 1个样本为 x 1 x_1 x1,第 i i i个为 x i x_i xi。对于每个 x x x,给予其系数 α \alpha α,此时存在: w ⃗ = ∑ i n α i x ( i ) \vec w=\sum^n_i\alpha_ix^{(i)} w=∑inαix(i),选取部分 α \alpha α,使它们的值不为 0 0 0,其余值都设为 0 0 0。则对 w w w真正起作用的就是值不为 0 0 0的这些 x x x向量。这些向量,支持了法线向量,因此就是支持向量。
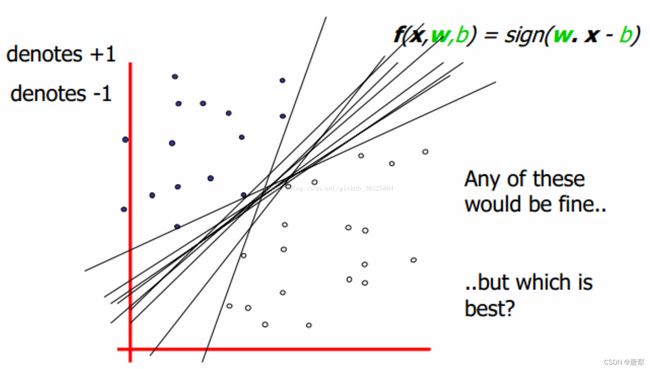
若直线 l l l有参数 w w w和 b b b,通过计算每个样本到直线 l l l距离,衡量哪条直线是最为合适的分割线。距离 d d d可以表示为: d = w x ( i ) + b ∥ w ∥ d=\frac {wx^{(i)}+b}{\Vert w\Vert} d=∥w∥wx(i)+b,若每个数据集中样本的形式为 T = { ( x 1 , y 1 ) ( x 2 , y 2 ) … ( x n , y n ) } T=\{(x_1, y_1)(x_2, y_2)…(x_n, y_n)\} T={(x1,y1)(x2,y2)…(xn,yn)},而每个样本的 y y y值,就是这个样本的label。正例为 1 1 1,负例为 − 1 -1 −1。这里的正负值其实反映的就是样本位于分割线的方向。位于法线正方向即为正。将 y y y值一起乘入等式右边: d = w x ( i ) + b ∥ w ∥ y ( i ) d=\frac {wx^{(i)}+b}{\Vert w\Vert}y^{(i)} d=∥w∥wx(i)+by(i),这里的 y y y值是样本的实际正负值,如果估计值与实际值符号相同,即分类正确,此时的结果为正值。如果分类错误,则结果为负值。
构造分割面
在所有样本中,距离该直线最近的样本应被选为支持向量。支持向量与直线间的距离即为过渡带。因为SVM期望过渡带尽可能大,因此最终参数 w w w与 b b b的选择可以表示为:
w ∗ , b ∗ = arg max ( min i = 1 , 2 , . . . , n w x ( i ) + b ∥ w ∥ y ( i ) ) w^*,b^*=\argmax (\min_{i=1,2,...,n}\frac{wx^{(i)}+b}{\Vert w\Vert}y^{(i)}) w∗,b∗=argmax(i=1,2,...,nmin∥w∥wx(i)+by(i))
因此,给定线性可分训练数据集,通过间隔最大化得到的分割超平面为: y ( x ) = w T Φ ( x ) + b y(x)=w^T\Phi(x)+b y(x)=wTΦ(x)+b,相应的分类决策函数为: f ( x ) = s i g n ( w T Φ ( x ) + b ) f(x)=sign(w^T\Phi(x)+b) f(x)=sign(wTΦ(x)+b)。
目标函数
对于线性可分SVM而言,目标函数实际上就是分割平面的选取,因此目标函数实际上就是:
w ∗ , b ∗ = arg max w , b ( 1 ∥ w ∥ min i = 1 , 2 , . . . , n ( y ( i ) w x ( i ) + b ) ) w^*,b^*=\argmax_{w,b} (\frac{1}{\Vert w\Vert}\min_{i=1,2,...,n}(y^{(i)}wx^{(i)}+b)) w∗,b∗=w,bargmax(∥w∥1i=1,2,...,nmin(y(i)wx(i)+b))
对于上式,在不改变分割面位置的情况下,总存在一个 w w w值,使距离该直线最近的向量到直线距离为 1 1 1。因此上式中,最小值部分可以始终取 1 1 1。此时的 W W W值,实际上才是目标函数本身,此时存在约束条件: y ( i ) ( W T Φ ( x ( i ) ) + b ) ≥ 1 y^{(i)}(W^T\Phi(x^{(i)})+b)\ge1 y(i)(WTΦ(x(i))+b)≥1。因此,通过拉格朗日乘子法可以对目标函数求极值:
max w , b 1 ∥ w ∥ , s . t . y ( i ) ( W T Φ ( x ( i ) ) + b ) ≥ 1 , i = 1 , 2 , . . . , n \max_{w,b}\frac{1}{\Vert w\Vert}, \\s.t. \ y^{(i)}(W^T\Phi(x^{(i)})+b)\ge1, \ i=1, 2, ..., n w,bmax∥w∥1,s.t. y(i)(WTΦ(x(i))+b)≥1, i=1,2,...,n
变形后可得:
min w , b 1 2 ∥ w ∥ 2 , s . t . y ( i ) ( W T Φ ( x ( i ) ) + b ) ≥ 1 , i = 1 , 2 , . . . , n \min_{w,b}\frac{1}{2}\Vert w\Vert^2, \\s.t. \ y^{(i)}(W^T\Phi(x^{(i)})+b)\ge1, \ i=1, 2, ..., n w,bmin21∥w∥2,s.t. y(i)(WTΦ(x(i))+b)≥1, i=1,2,...,n
对目标函数使用拉格朗日乘子法:
L ( w , b , a ) = min w , b 1 2 ∥ w ∥ 2 + ∑ i = 1 n a ( i ) ( 1 − y ( i ) ( w T Φ ( x ( i ) ) + b ) ) , s . t . 1 − y ( i ) ( W T Φ ( x ( i ) ) + b ) ≤ 0 , i = 1 , 2 , . . . , n L(w, b, a)=\min_{w,b}\frac{1}{2}\Vert w\Vert^2+\sum^n_{i=1}a^{(i)}(1-y^{(i)}(w^T\Phi(x^{(i)})+b)), \\ s.t. \ 1-y^{(i)}(W^T\Phi(x^{(i)})+b)\le0, \ i=1, 2, ..., n L(w,b,a)=w,bmin21∥w∥2+i=1∑na(i)(1−y(i)(wTΦ(x(i))+b)),s.t. 1−y(i)(WTΦ(x(i))+b)≤0, i=1,2,...,n
这里的 w w w和 b b b是原始的参数,而 a a a是引入的参数且大于等于 0 0 0。为了方便整理与化简,接下来对 L L L求偏导并使偏导为0:
∂ L ∂ w = w − ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) = 0 \frac{\partial L}{\partial w}=w-\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)})=0 ∂w∂L=w−i=1∑na(i)y(i)Φ(x(i))=0
解得:
w = ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) ∂ L ∂ b = − ∑ i = 1 n a ( i ) y ( i ) = 0 \begin{aligned} w&=\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)}) \\ \frac{\partial L}{\partial b}&=-\sum^n_{i=1}a^{(i)}y^{(i)}=0 \end{aligned} w∂b∂L=i=1∑na(i)y(i)Φ(x(i))=−i=1∑na(i)y(i)=0
根据上式, a a a等于 0 0 0的时候可知其对 w w w与 b b b无作用。因此,真正的支持向量,是那些不为 0 0 0的向量。
这里给出一个通过凸优化后最终得到的求的式子:
a ∗ = arg max a ( ∑ i = 1 n a ( i ) − 1 2 ∑ i , j = 1 n a ( i ) a ( j ) y ( i ) y ( j ) Φ T ( x ( i ) ) Φ T ( x ( j ) ) ) a^*=\argmax_a(\sum^n_{i=1}a^{(i)}-\frac{1}{2}\sum^n_{i, j=1}a^{(i)}a^{(j)}y^{(i)}y^{(j)}\Phi^T(x^{(i)})\Phi^T(x^{(j)})) a∗=aargmax(i=1∑na(i)−21i,j=1∑na(i)a(j)y(i)y(j)ΦT(x(i))ΦT(x(j)))
求出 a a a之后回代可得 w w w与 b b b:
w ∗ = ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) b ∗ = y ( i ) − ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) Φ ( x ( j ) ) \begin{aligned} w^*&=\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)}) \\ b^*&=y^{(i)}-\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)})\Phi(x^{(j)}) \end{aligned} w∗b∗=i=1∑na(i)y(i)Φ(x(i))=y(i)−i=1∑na(i)y(i)Φ(x(i))Φ(x(j))
松弛因子
对于线性SVM而言,因为不要求所有样本都被分对,因此其约束条件和线性可分SVM并不相同。给出一个大于等于 0 0 0的松弛因子 ξ \xi ξ,使函数间隔加上松弛因子后大于等于 1 1 1,此时有目标函数及约束条件:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ ( i ) , s . t . y ( i ) ( W T Φ ( x ( i ) ) + b ) ≥ 1 − ξ ( i ) , i = 1 , 2 , . . . , n \min_{w,b}\frac{1}{2}\Vert w\Vert^2+C\sum^n_{i=1}\xi^{(i)}, \\ s.t. \ y^{(i)}(W^T\Phi(x^{(i)})+b)\ge1-\xi^{(i)}, \ i=1, 2, ..., n w,bmin21∥w∥2+Ci=1∑nξ(i),s.t. y(i)(WTΦ(x(i))+b)≥1−ξ(i), i=1,2,...,n
上式中, C C C是一个控制松弛因子权重的参数。当 C C C足够大时, ξ \xi ξ只能趋近于0,变回线性可分SVM。因此上式也可以被看作是线性可分SVM的扩展。松弛项可以被理解为线性回归中的正则项, C C C的值越小,过渡带越宽, C C C的值越大,过渡带越窄。这也使得线性SVM具备更强的泛化性。
同样的,对于线性SVM的目标函数及其约束条件使用拉格朗日乘子法后,求偏导可得:
L ( w , b , ξ , a , μ ) = 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ ( i ) + ∑ i = 1 n a ( i ) ( 1 − y ( i ) ( w T Φ ( x ( i ) ) + b ) − ξ ( i ) ) − ∑ i = 1 n μ ( i ) ξ ( i ) L(w,b,\xi,a,\mu)=\frac{1}{2}\Vert w\Vert^2+C\sum^n_{i=1}\xi^{(i)}+\sum^n_{i=1}a^{(i)}(1-y^{(i)}(w^T\Phi(x^{(i)})+b)-\xi^{(i)})-\sum^n_{i=1}\mu^{(i)}\xi^{(i)} L(w,b,ξ,a,μ)=21∥w∥2+Ci=1∑nξ(i)+i=1∑na(i)(1−y(i)(wTΦ(x(i))+b)−ξ(i))−i=1∑nμ(i)ξ(i)
∂ L ∂ w = w − ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) = 0 w = ∑ i = 1 n a ( i ) y ( i ) Φ ( x ( i ) ) ∂ L ∂ b = − ∑ i = 1 n a ( i ) y ( i ) = 0 ∂ L ∂ ξ = C − a ( i ) − μ ( i ) \begin{aligned} \frac{\partial L}{\partial w}&=w-\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)})=0 \\ w&=\sum^n_{i=1}a^{(i)}y^{(i)}\Phi(x^{(i)}) \\ \frac{\partial L}{\partial b}&=-\sum^n_{i=1}a^{(i)}y^{(i)}=0 \\ \frac{\partial L}{\partial\xi}&=C-a^{(i)}-\mu^{(i)} \end{aligned} ∂w∂Lw∂b∂L∂ξ∂L=w−i=1∑na(i)y(i)Φ(x(i))=0=i=1∑na(i)y(i)Φ(x(i))=−i=1∑na(i)y(i)=0=C−a(i)−μ(i)
这里直接给出 a a a最后的求解形式:
a ∗ = arg min a ( ∑ i = 1 n a ( i ) − 1 2 ∑ i , j = 1 n a ( i ) a ( j ) y ( i ) y ( j ) Φ T ( x ( i ) ) Φ T ( x ( j ) ) ) s . t . ∑ i = 1 n a ( i ) y ( i ) = 0 0 ≤ a ( i ) ≤ C , i = 1 , 2 , . . . , n a^*=\argmin_a(\sum^n_{i=1}a^{(i)}-\frac{1}{2}\sum^n_{i,j=1}a^{(i)}a^{(j)}y^{(i)}y^{(j)}\Phi^T(x^{(i)})\Phi^T(x^{(j)})) \\ s.t. \ \sum^n_{i=1}a^{(i)}y^{(i)}=0 \\ 0\le a^{(i)}\le C, \ i=1,2,...,n a∗=aargmin(i=1∑na(i)−21i,j=1∑na(i)a(j)y(i)y(j)ΦT(x(i))ΦT(x(j)))s.t. i=1∑na(i)y(i)=00≤a(i)≤C, i=1,2,...,n
损失函数
SVM的损失,通常被定义为没有被正确分在过渡带外面的向量,到过渡带边界的距离。位于过渡带内的样本,损失为 1 − d 1-d 1−d。 d d d是该样本到分割面的距离。注意,如果是在“本方”过渡带,则 d d d为正值。如果已经越过分割面了,则 d d d值变为负值。这个损失也被称为Hinge损失。因此损失函数可以被写成:
L o s s ( w , b ) = ∑ i = 1 n ξ ( i ) Loss(w,b)=\sum^n_{i=1}\xi^{(i)} Loss(w,b)=i=1∑nξ(i)
换句话说,松弛因子本身可以被看作是损失的衡量。因为松弛因子本身也是包容分割面的分割错误。实际上,损失本身,就是由于线性SVM允许过渡带内存在向量,甚至向部分错误分类的向量妥协的结果。因此,原目标函数变为:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ ( i ) \min_{w,b}\frac{1}{2}\Vert w\Vert^2+C\sum^n_{i=1}\xi^{(i)} w,bmin21∥w∥2+Ci=1∑nξ(i)
某种意义上,可以认为是Hinge损失加上一个 l 2 l_2 l2正则。
核函数
核函数可以说是SVM的精髓所在,其目的在于,通过将原始输入空间映射到更高维度的特征空间这一操作,原本线性不可分的样本可以在新的核空间内变为线性可分。常见的核函数有:
- 多项式核函数: k ( x 1 , x 2 ) = ( x 1 T x 2 + c ) d k(x_1,x_2)=(x_1^Tx_2+c)^d k(x1,x2)=(x1Tx2+c)d
- RBF核函数: k ( x 1 , x 2 ) = e − ∥ x 1 − x 2 ∥ 2 2 σ 2 k(x_1,x_2)=e^{-\frac{\Vert x_1-x_2\Vert^2}{2\sigma^2}} k(x1,x2)=e−2σ2∥x1−x2∥2
- Sigmoid核函数: k ( x 1 , x 2 ) = tanh ( x 1 T x 2 + c ) k(x_1,x_2)=\tanh(x_1^Tx_2+c) k(x1,x2)=tanh(x1Tx2+c)
从多项式核函数讲起,最基本的, c c c等于 0 0 0, d d d等于 2 2 2的情况下,kernel使原有的两个变量两两相乘。这相当于将维度数量平方了。规模上,特征数目变为平方级,而计算复杂度并没有显著上升。
RBF则是固定每一个 x i x_i xi,对于变化的 x j x_j xj,以 x i x_i xi为中心做指数级衰减。相当于是以 x i x_i xi为中心,做高斯分布。因此被称作高斯核函数。对于每个样本的label而言,正例被核函数向上拉升,负例向下延伸。从而使数据分离。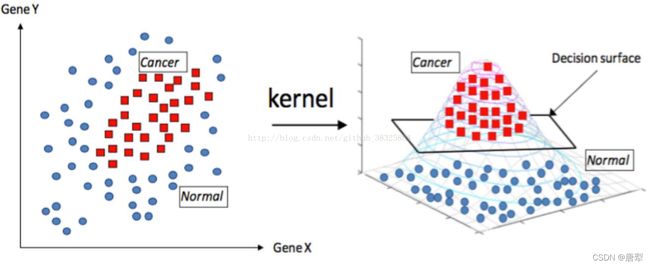
分离后的数据,可以被多个分割面分离,我们要选取的,实际上就是使距离分割面最近的样本距离尽可能大的分割方式。因此最终的超平面选取还是使用线性SVM的思路。RBF的维度映射可以被理解是无穷维的,因为在数学上,RBF的指数可以被泰勒展开。展式中的每一项,都可以被理解为该维度上的样本分离。因为其强力的高维映射能力,RBF往往是首选核函数。
Iris数据分类代码
数据选用的是Iris数据集,代码如下:
import sklearn.datasets
import numpy as np
import pandas as pd
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = sklearn.datasets.load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris['data'], iris['target'], random_state=1, train_size=0.8)
svm_model = svm.SVC(C=0.5, kernel='linear', decision_function_shape='ovr')
svm_model.fit(x_train, y_train.ravel())
print(accuracy_score(y_train, svm_model.predict(x_train)))
print('Accuracy:', accuracy_score(y_test, svm_model.predict(x_test)))
print(y_test.ravel())
print(svm_model.predict(x_test))
总结
SVM可以说是泛化能力很强的优质分类器,准确率也很高。相比于LR和RF,SVM难点在于调参。RF更多的注重效率,在模型训练以及特征选择上省下了大把时间。LR学习速率也快于SVM,比较通用,精确度和效率都不错。