(翻译)Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector具有注意力RPN和多关系检测器的小样本目标检测
文章目录
- 前言
- 一、背景
- 二、相关工作——Related Works
-
- 2.1 通用目标检测
- 2.2 小样本学习
- 三、 FSOD数据集——A Highly-Diverse Few-Shot Object Detection Dataset
-
- 3.1 FSOD数据集构建
- 3.2 数据集分析
- 3.3 类别高度多样性
- 3.4 具有挑战性的设置
- 四、方法
-
- 4.1 问题定义
- 4.2 深度注意力小样本检测——Deep Attentioned Few-Shot Detection
- 4.3 方法概述
-
- 4.3.1 基于注意力的区域生成网络
- 4.3.2多关系检测器——Multi-Relation Detector
- 4.3.3 双向对比训练策略——Two-way Contrastive Training Strategy
- 五、实验
-
- 5.1 训练细节
- 5.2 与最新方法的比较
-
- 5.2.1 ImageNet检测数据集
- 5.2.2 MS COCO数据集
- 5.3 现实应用
- 5.4 其他分类与更多的样本?
- 六、结论
前言
带有注意力RPN和多关系检测器的小样本目标检测网络并开源FSOD数据集(含1000个类别)
小样本学习即少样本学习,小样本就是数据集样本数量比通用标准要少很多,甚至每个类别下只有几个的意思。小样本学习由于数据不足往往要借助于更多的先验知识。
小样本不是小目标。
提示:以下是本篇文章正文内容,可供参考
一、背景
目标检测的惯用方法通常严重依赖于大量带注释的数据,并且需要较长的训练时间。这激发了小样本目标检测的最新发展。考虑到现实世界中物体的光照,形状,纹理等方面的巨大差异,小样本 learning会遇到挑战。尽管已经取得了重要的研究和进展,但是所有这些方法都将重点放在图像分类上,而很少涉及到很少检测到物体的问题,这很可能是因为从小样本分类转移到小样本目标检测是一项艰巨的任务。
仅有小样本的目标检测的中心是如何在杂乱的背景中定位看不见的对象,从长远来看,这是新颖类别中一些带注释的示例中对象定位的一个普遍问题。潜在的边界框很容易错过看不见的物体,否则可能在背景中产生许多错误的检测结果。我们认为,这是由于区域生成网络(RPN)输出的良好边界框得分过低而导致难以检测到新物体。这使得小样本目标检测本质上不同于小样本分类。另一方面,最近用于小样本物体检测的工作都需要微调,因此不能直接应用于新颖类别。
本文中,提出一种新的少点目标检测网络,只用几个带注释的示例的看不见的类来检测目标。集中到新方法的核心是,注意力RPN,多相关检测器,以及对比训练策略,探索少点support集和query集之间的相似性,检测新目标同时抑制背景中的错误检测。训练网络,提供新数据集,它包含1000类不同的目标,附加高质量的注释信息。众所周知,这是为少点目标检测最好的特定数据集之一。当少点网络训练后,不需要进一步训练和优化,就可以检测看不接见的类。这种方法是通用的,具有广泛的应用潜力。提供少点数据集中新的不同数据集上艺术状态性能。
解决什么问题:
少量support的情况,检测全部的属于target目标范畴的前景
本文IDEA来源:
问题在于新的类别不错的框的分数低
在今天分享的文章中,作者解决了小样本目标检测的问题:给定一些新颖目标对象的support图像,我们的目标是检测测试集中属于目标对象类别的所有前景对象,如图1所示。

图1.给定不同的对象作为支撑(在上方),我们的方法可以检测给定query图像中相同类别中的所有对象。
本文创新点\贡献:
- 没有反复训练和fine-tune的情况检测新物体,探索物体对的联系。可以在线检测,在proposal前面使用attention模块很有用,联系模块能过滤
- 大量的数据集,1000个类,每个类只有少量样本,实验表明用这个数据集能达到的效果更好。
首先,我们提出了一种通用的小样本物体检测模型,该模型可用于检测新颖物体而无需重新训练和微调。借助我们精心设计的对比训练策略,RPN上的注意力模块和检测器,我们的方法在多个网络阶段利用权重共享网络中的对象对之间的匹配关系。这使我们的模型可以对不需要精细训练或无需进一步网络适应的新颖类别的对象执行在线检测。实验表明,我们的模型可以在建议质量得到显着提高的早期阶段中从关注模块以及多重关系检测器模块中受益,该模型可以抑制并在令人迷惑的背景中滤除错误检测。我们的模型在小样本设置下就在ImageNet Detection数据集和MS COCO数据集上实现了最新的性能。
第二个贡献是一个大型的带注释的数据集,该数据集包含1000个类别,每个类只有少量样本,实验表明用这个数据集能达到的效果更好。总体而言,与现有的大规模数据集(例如,coco[13]。据我们所知,这是具有空前数量的对象类别(1000)的小样本目标检测数据集之一。使用该数据集,即使没有任何微调,我们的模型也可以在不同的数据集上实现更好的性能。
二、相关工作——Related Works
2.1 通用目标检测
对象检测是计算机视觉中的经典问题。在早期,通常使用手工特征将对象检测公式化为滑动窗口分类问题[14] – [15] [16]。随着深度学习的兴起[17],基于CNN的方法已成为占主导地位的对象检测解决方案。大多数方法可以进一步分为两种通用方法:无提议检测器和基于提议的检测器。第一线工作遵循一个阶段的培训策略,没有明确生成建议框[18] – [19] [20] [21] [22]。另一方面,第二条线由R-CNN率先提出[23],首先从给定图像中提取潜在对象的类别不可知区域建议。然后,通过特定的模块[24] – [25] [26] [27]进一步完善这些框并将其分类为不同的类别。该策略的优势在于,它可以通过RPN模块过滤掉许多负面位置,从而简化检测器的工作。为此,基于RPN的方法通常比无提议的方法具有更好的检测结果,该方法具有最新的结果[27]。然而,上述方法以密集的监督方式工作,并且仅通过几个示例就很难将其扩展到新颖的类别。
2.2 小样本学习
对于传统的机器学习算法而言,仅从几个训练示例中进行学习,在经典环境中很少有学习机会[28]面临挑战。较早的作品尝试学习一般的先验[29] – [30] [31] [32] [33],例如手工设计的笔触或可以在各个类别之间共享的部分。一些作品[1],[34] – [35] [36]在手动设计不同类别之间的距离公式时,重点关注度量学习。最近的趋势是设计一种通用代理/策略,以指导每个任务中的监督学习。通过积累知识,网络可以捕获跨不同任务的结构变化。该研究方向一般称为元学习[2],[5],[37] – [38] [39]。在这一领域,[37]提出了一个暹罗网络。该网络由共享权重的两个网络组成,其中每个网络分别提供support图片和query。query及其support之间的距离自然是通过逻辑回归来了解的。这种匹配策略可以捕获support和query之间的固有差异,而不管它们的类别如何。在匹配框架领域,后续工作[3],[4],[6],[8],[10],[40]专注于增强特征嵌入,其中一个方向是构建存储模块以捕获全局support中的上下文。一些作品[41],[42]利用本地描述符从有限的数据中获取更多的知识。在[43],[44]中,作者引入了图神经网络(GNN)来建模不同类别之间的关系。在[45]中,遍历给定的整个support集以识别与任务相关的功能,并使高维空间中的度量学习更加有效。其他工作,例如[2],[46],旨在学习通用代理以指导参数优化。
到目前为止,很少有的学习没有取得突破性的进展,该学习主要集中在分类任务上,而很少关注其他重要的计算机视觉任务,例如语义分割[47] – [48] [49],人体运动预测[ 50]和物体检测[9]。在[51]中,使用了未标记的数据,并且在没有框的图像上交替优化了多个模块。但是,该方法可能会因监督不力而被错误检测误导,并需要对新类别进行重新培训。在LSTD中[9]这组作者提出了一种新颖的小样本目标检测框架,该框架可以通过最小化源域和目标域之间的后验概率分类差距,将知识从一个大型数据集转移到另一个较小的数据集。但是,此方法在很大程度上取决于源域,并且很难扩展到非常不同的方案。最近,提出了一些其他用于小样本检测的著作[9],[10] – [11] [12],但是他们学习特定于类别的嵌入并且需要针对新颖的类别进行微调
我们的工作是由匹配网络开创的研究线所激发的[37]。我们提出了一个通用的几次拍摄目标检测网络,该网络基于Faster R-CNN框架来学习图像对之间的匹配度量,该框架配备了我们新颖的注意力RPN和使用我们的对比训练策略训练的多关系检测器。
`
三、 FSOD数据集——A Highly-Diverse Few-Shot Object Detection Dataset
进行小样本学习的关键在于当新的类别出现时相关模型的泛化能力。因此,具有大量对象类别的高多样性数据集对于训练可以检测到看不见的对象的通用模型以及执行令人信服的评估是必要的。但是,现有的数据集包含的类别非常有限,并且不是在一次性评估设置中设计的。因此,我们建立了一个新的小样本物体检测数据集。
3.1 FSOD数据集构建
我们从现有的大规模对象检测数据集构建数据集以进行监督学习,即[56,54]。但是,由于以下原因,这些数据集无法直接使用:
1)不同数据集的标签系统是在某些具有相同语义的对象用不同的词注释的地方不一致;
2)由于标签不正确和缺失,重复的框,对象太大,现有注释的很大一部分是嘈杂的;
3)他们的训练/测试组包含相同的类别,而对于小样本设置,我们希望训练/测试组包含不同的类别,以评估其在看不见的类别上的普遍性
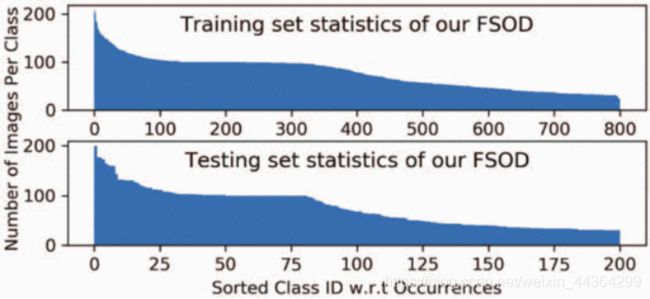
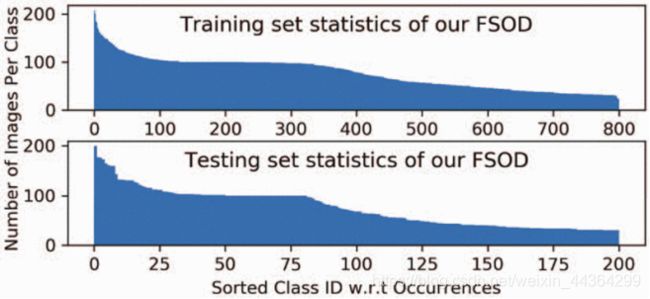
图3 FSOD的数据集统计。类别图像编号几乎是平均分布的。大多数班级(超过90%)具有小样本或中等数量的图像(在[22,108]中),而最频繁的班级仍具有不超过208张图像。
{为了开始构建数据集,我们首先从中总结标签系统。我们将叶子标签合并到其原始标签树中,方法是将具有相同语义(例如,冰熊和北极熊)的叶子标签归为一类,并删除不属于任何叶子类别的语义。然后,我们将删除标签质量较差的图像以及带有不合适尺寸的盒子的图像。具体而言,删删除的图像的框小于图像尺寸的0.05%,通常框的视觉质量较差,不适合用作support示例。接下来,我们按照几次学习设置将数据分为训练集和测试集,而没有重叠的类别。如果研究人员更喜欢预训练阶段,我们将在MS COCO数据集中按类别构建训练集。然后,我们通过选择现有训练类别中距离最大的类别来划分包含200个类别的测试集,其中距离是连接is-a分类法中两个短语的含义的最短路径。其余类别将合并到总共包含800个类别的训练集中。总而言之,我们构建了一个包含1000个类别的数据集,其中明确地划分了类别用于训练和测试,其中531个类别来自ImageNet数据集,而469来自开放图像数据集。}
3.2 数据集分析
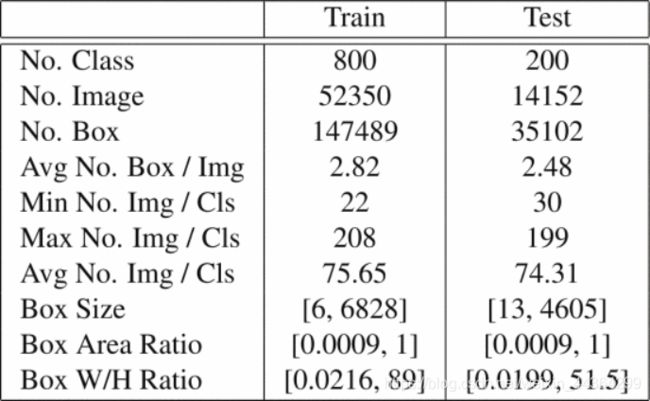
本数据集是专为小样本学习和评估泛化性能而设计的。该数据集包含1000个类别,分别用于训练和测试800,200。总共有66000张图片与182000边界框。表1和图3显示了详细的统计信息,我们的数据集具有以下属性:
表1.数据集摘要。我们的数据集是多样化的,并且框的大小和纵横比有很大的差异。
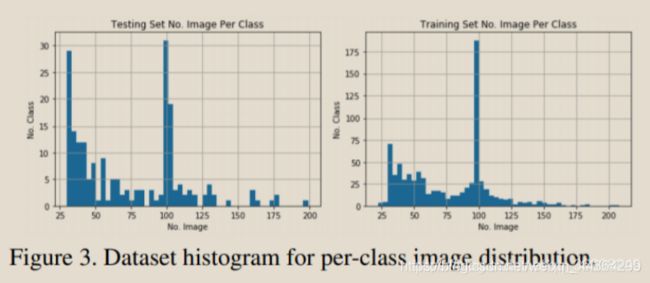
3.3 类别高度多样性
我们的数据集包含83种父级语义,例如哺乳动物,衣服,武器等,这些语义进一步细分为1000个叶子类别。我们的标签树如图2所示。由于严格的数据集划分,我们的训练/测试集包含了非常不同的语义类别的图像,因此给要评估的模型提出了挑战。

图2.数据集标签树。ImageNet类别(红色圆圈)与采用超类的开放图像类别(绿色圆圈)合并
3.4 具有挑战性的设置
我们的数据集包含对象大小和纵横比差异很大的对象,由26.5%的图像组成,其中测试集中的对象不少于3个。我们的测试集包含大量未包含在标签系统中的类别的框,因此对于小样本的模型提出了巨大挑战。
尽管我们的数据集具有大量类别,但是训练图像和框的数量远少于其他大规模基准数据集(例如MS COCO数据集),该数据集包含123,287张图像和约886,000个边界框。我们的数据集设计简练,同时对小样本学习有效。
四、方法
在本节中,我们首先定义我们的小样本检测任务,然后详细描述我们新颖的小样本目标检测网络。
4.1 问题定义
support image :给定的不同的对象(头盔+自行车)
query image:任务是在query中找到属于support类别的所有目标对象,并用紧密的边界框标记它们。
给定一个带有目标对象特写的support图像sc,包含support类别c的对象的query图像qc,任务是在query图像中查找属于该support类别的所有目标对象,并用紧密的边界框将他们标记出来。如果support集包含K个类别,每个类别包含N个示例,这个问题就被称为K-way N-shot detection
4.2 深度注意力小样本检测——Deep Attentioned Few-Shot Detection
【我们提出了一种新颖的注意力网络,该网络学习了support集与RPN模块和检测器上的query之间的一般匹配关系。图4显示了我们网络的整体架构。】
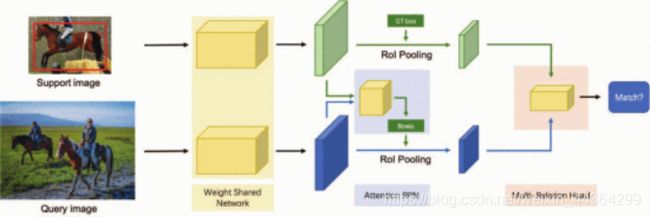
图4 网络架构。
query与support图像由权重共享网络进行处理。注意力区域生成网络模块通过关注给定的support类别来过滤其他类别中的生成对象。然后由多关系检测器来匹配query生成和support对象。对于k-way训练,通过添加k-1support分支来扩展网络,其中每个分支都有自己的注意力RPN和带有query图像的多关系检测器。对于N-shot训练,通过权重共享网络获得所有support特征,并使用属于同一类别的所有support特征的平均特征。
4.3 方法概述
在RPN前加一个attention,在检测器之前加了3个attention,然后还是用到了负support训练。具体来说,我们构建了一个由多个分支组成的权重共享框架,其中一个分支用于query集,另一个分支用于support集(support根据输入有多个分支,图片只显示了一个。为简单起见,我们在图中仅显示了一个support分支)。query分支是一个FasterRCNN网络,包含RPN和检测器。利用此框架来训练support和query功能之间的匹配关系,以使网络学习相同类别之间的常识。在该框架的基础上,我们引入了一种新颖的注意力RPN和具有多关系模块的检测器,用于在support框和query框之间产生准确的query解析。
4.3.1 基于注意力的区域生成网络
在小样本检测中,区域生成网络产生可能相关的框,用于之后的检测任务。特别是,区域生成网络不仅应区分对象还是非对象,还应过滤掉不属于support类别的其他对象。
【但是,如果没有任何support图像信息,即使它们不属于support类别,RPN在具有高客观分数的每个潜在对象中也将毫无目标地运作,从而给检测器的后续分类任务增加了许多不相关的对象。为了解决这个问题,我们提出注意力RPN(图5),它使用support信息来过滤掉大多数背景框和不匹配类别的背景框。因此,生成了一个较小且更精确的候选提案集,其中包含潜在的目标对象。】
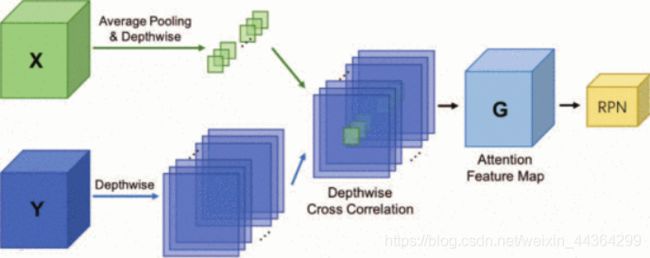
图5 注意力区域生成网络如上图所示,support特征被平均池化合并到1x1xc向量。然后计算与query特征的深度互相关,其输出用作关注特征并feed到区域生成网络。
通过关注机制向区域生成网络引入support信息,并指导区域生成网络生成相关proposal,同时禁止其他proposal。具体来说,以深度方式计算support特征图与query特征图之间的相似度,然后利用相似度图来构建生成的proposal。
特别的,将support特征表示为X=> t(SxSxC), 将query特征图表示为Y=>(HxWxC)。相似性定义为:
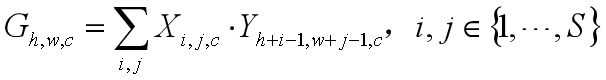
其中G是attention特征图,X作为一个卷积核在query的特征图上滑动,以一种逐深度(取平均)的方式。
【使用的是RPN的底部特征,ResNet50的res4-6,发现设置S=1表现很好,这说明全局特征能提供一个好的先验。在我们的案例中,内核是通过对support特征图进行平均来计算的。G用3×3的卷积处理,然后接分类和回归层。。损失为Lrpn的注意力RPN与网络[25]一起训练。】
4.3.2多关系检测器——Multi-Relation Detector
多关系检测器:全局关系模块使用全局表示来匹配图像;局部关系模块捕获像素级别的匹配关系;patch关系模块对一对多像素关系进行建模。
在R-CNN框架中,区域生成网络模块后面是一个检测器,它的重要作用是重新对proposal进行评分和类识别。因此,我们希望检测器具有很强的区分不同类别的能力。为此,我们提出了一种新的多关系检测器,可以有效的测量来自query和support对象的生成框之间的相似性。见图6。
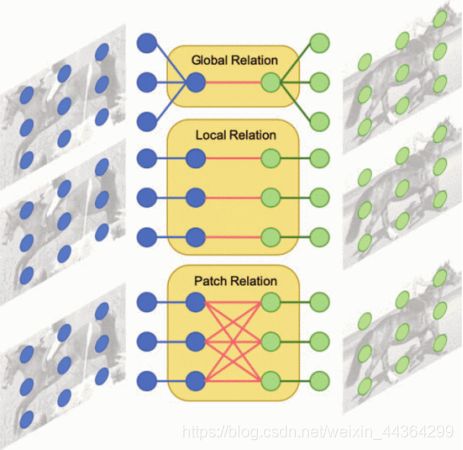
图6 多关系检测器。不同的关系模块建模query和support图像之间的不同关系。全局关系模块使用全局表示来匹配图像;局部关系模块捕获像素到像素的匹配关系;补丁关系模块对一对多像素关系进行建模。
该检测器包括三个注意力模块,分别是全局关系头(为全局匹配学习深度嵌入)、局部匹配头(学习support与query提议中的像素与深度级别相关性)和patch关系头(学习patch匹配的深度非线性度量)。
三个head的分析:
第三个patch 并不理想,这个头的模型更复杂,但作者也觉得复杂的联系是难学习的
但是三个一起用效果最好,说明之间还是能相互补充的。
我们需要哪些关系模块?
我们遵循RepMet [59]中提出的Kway N-shot评估协议来评估我们的关系模块和其他组件。表2显示了我们在FSOD数据集的简单1-way 1-shot训练策略和5-way 5-shot评估下对我们提出的多关系检测器的模型简化测试【ablation:切除,ablation study 模型简化测试,即去掉一些模块后性能有没有影响,为了研究模型中所提出的一些结构是否有效而设计的实验】。
表2. 1-way 1-shot训练策略中不同关系模块儿的实验结果。
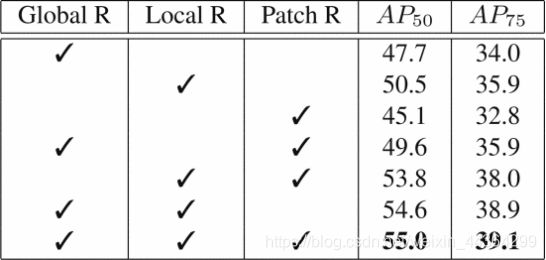
此后,我们对FSOD数据集上的所有模型简化测试使用相同的评估设置。对于单个模块,本地关系模块在AP50和AP75评估中均表现最佳。出人意料的是,尽管补丁关系模块对图像之间更复杂的关系进行建模,但其性能比其他关系模块差。我们认为,复杂的关系模块使模型难以学习。当组合任何两种类型的关系模块时,我们获得的性能要优于单个关系模块。通过组合所有的关系模块,我们获得了完整的多重关系检测器,并获得了最佳性能,表明三个提出的关系模块相互补充,可以更好地区分目标与不匹配的对象。因此,以下所有实验均采用完整的多关系检测器
4.3.3 双向对比训练策略——Two-way Contrastive Training Strategy
【最简单【naive】的训练策略是通过构造训练对(qc,sc)来匹配相同类别的对象,其中query图像qc和support图像sc都在同一第c个类别对象中。但是,好的模型不仅应匹配相同的类别对象,还应区分不同的类别。因此,我们提出了一种新颖的双向对比训练策略。】
不仅匹配而且区分
根据图7中不同的匹配结果,我们提出了2次对比训练,在区分不同类别的同时匹配相同类别。
 图7:2次对比训练三联体和不同的匹配结果。在query图像中,只有正support与目标基本事实具有相同的类别。匹配对包括正面support和前景建议,非匹配对具有三类:(1)正面support和背景建议;(2)负面support和前景建议;(3)负面support和负面建议。
图7:2次对比训练三联体和不同的匹配结果。在query图像中,只有正support与目标基本事实具有相同的类别。匹配对包括正面support和前景建议,非匹配对具有三类:(1)正面support和背景建议;(2)负面support和前景建议;(3)负面support和负面建议。
我们随机选择一个query图像qc,一个包含相同第c个类别对象的support图像sc和另一个包含不同第n个类别对象的support图像sn来构建训练组(qc,sc,sn),其中c不等于n。
在训练组中,仅将query图像中的第c个类别对象标记为前景,而将所有其他对象视为背景。
在训练期间,模型学习将query图像中的注意力RPN生成的每个建议与support图像中的对象进行匹配。因此,该模型不仅学习匹配(qc,sn)之间的相同类别对象,而且还可以区分(qc,sn)之间的不同类别的对象。但是,大量的背景建议通常会主导培训,尤其是带有负面support图片时。因此,我们在query提议和support之间平衡了三个不同匹配对的比率。对于前景提案和正support对(pf,sp),背景提案和正support对(pb,sp),提案(前景或背景)和否定support对(p,sn)。我们选择所有N(pf,sp)对,并根据它们的匹配分数分别选择前2N(pb,sp)对和前N(p,sn)对。我们计算所选对的匹配损耗。在训练过程中,我们在每个抽样建议上使用多任务损失,如L = Lmatching + Lbox,边界框损失Lbox如[24]中所定义,匹配损失为二进制交叉熵。
哪种训练策略更好?请参阅表3。
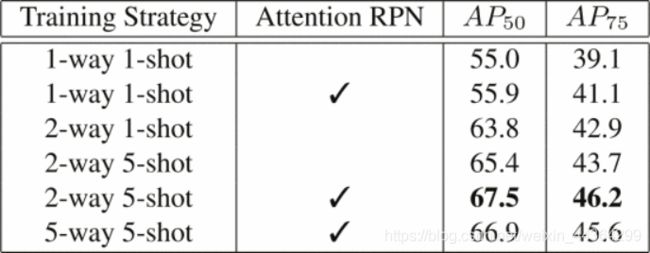
我们使用2-way 1-shot对比训练策略训练模型,与1-way 1-shot单纯训练策略相比,AP50改善了7.9%,这表明在训练中学习如何区分不同类别方面的重要性。通过5-shot训练,我们实现了进一步的改进,这在[1]中也得到了验证,小样本训练对小样本测试很有帮助。将我们的双向训练策略扩展到多向训练策略很简单。但是,从表3中可以看出,五次训练策略的效果并不比二次训练策略更好。我们认为,只有一个否定support类别足以训练用于区分不同类别的模型。因此,我们的完整模型采用了2-way 5-shot对比训练策略。
哪个RPN更好?
我们根据不同的评估指标评估注意力RPN。为了评估提案质量,我们首先评估常规RPN和建议的RPN超过0.5 IoU阈值的前100个提案的召回率。我们关注的RPN具有比常规RPN更好的召回性能(0.9130对0.8804)。然后,我们针对这两个RPN评估整个ground truth框的平均最佳重叠率(ABO)。注意力RPN的ABO为0.7282,而常规RPN的相同度量为0.7127。这些结果表明,注意力RPN可以生成更多高质量的建议。
表3进一步比较了在不同训练策略下具有注意力RPN的模型和具有常规RPN的模型。在AP50和AP75评估中,注意力RPN的模型始终表现出比常规RPN更好的性能。在AP50 / AP75评估中,注意力RPN在1-way 1-shot训练策略中产生0.9%/ 2.0%的收益,在2-way 5-shot训练策略中产生2.0%/ 2.1%的收益。这些结果证实,我们注意力的RPN会产生更好的建议并有益于最终的检测预测。因此,在我们的完整模型中采用了注意力RPN。
五、实验
在实验中,我们将我们的方法与不同数据集上的最新技术(SOTA)方法进行了比较。我们通常在FSOD训练集上训练我们的完整模型,并直接在这些数据集上进行评估。为了与其他方法公平比较,我们可能会放弃对FSOD的培训,并采用与这些方法相同的培训/测试设置。在这些情况下,我们将在微调阶段使用多路1次小样本训练,并进行更多描述。
5.1 训练细节
我们的模型在4个Tesla P40 GPU上使用SGD进行了端到端训练,批处理大小为4(用于query图像)。对于前56000次迭代,学习率为0.002;对于随后的4000次迭代,学习率为0.0002。我们观察到,在ImageNet [56]和MS COCO [13]上的预训练可以提供稳定的低级功能,并导致更好的收敛点。鉴于此,我们默认在[13],[56]上从预先训练的ResNet50训练模型除非另有说明。在训练过程中,我们发现更多的训练迭代可能会损害性能,而太多的训练迭代会使模型过度适合训练集。我们固定Res1-3块的权重,仅训练高层以利用底层的基本功能并避免过度拟合。query图像的短边被调整为600像素;较长的一侧上限为1000。将support图像裁剪为带有16像素图像上下文的目标对象,并进行零填充,然后将其调整为正方形图像。320 × 320。对于小样本训练和测试,我们通过平均相同类别的对象特征来融合特征,然后将其馈送到关注的RPN和多关系检测器。我们采用典型指标[21],即一个P,一P50 和 一种P75 进行评估.
5.2 与最新方法的比较
5.2.1 ImageNet检测数据集
在表4中,我们将我们的结果与LSTD [9]和RepMet [61]的结果在具有挑战性的基于ImageNet的50路5镜头检测场景下进行了比较。为了公平比较,我们使用他们的评估协议和测试数据集,并且使用相同的MS COCO训练集来训练我们的模型。在评估过程中,我们还使用soft-NMS [63]作为RepMet。与最新技术(SOTA)相比,我们的方法可产生1.7%的性能提升。一种P50 评估。
为了展示我们方法的泛化能力,我们将在FSOD数据集上训练的模型直接应用于测试集,并在测试集上获得41.7%。 一种P50评估令人惊讶地好于我们的微调模型(表4)。应该注意的是,我们在FSOD数据集上训练的模型可以直接应用于测试集,而无需进行微调以实现SOTA性能。此外,尽管我们在FSOD数据集上训练的模型略胜一筹一种P50 性能优于我们在MS COCO数据集上经过微调的模型,我们的模型在模型上比经微调的模型超出了6.4% 一种P75评估,这表明我们提出的FSOD数据集显着受益于小样本目标检测。通过在测试集上进一步微调经过FSOD训练的模型,我们的模型可以达到最佳性能,同时请注意,与SOTA相比,不进行微调的方法已经达到最佳效果。
表4 在5种support下的50种新颖类别的ImageNet检测数据集上的实验结果。†表示测试类别已从FSOD训练数据集中删除。表示该模型已在imagenet检测数据集上进行了微调。
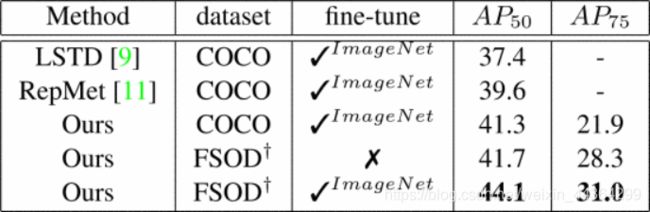
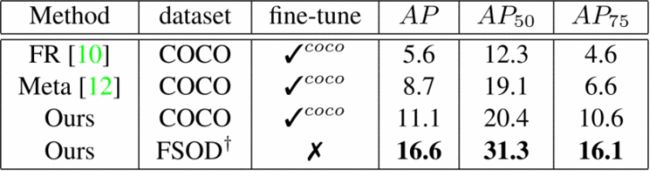
表5. MS COCO最小集的实验结果,包含20种新颖类别和10种support物。†表示从FSOD训练数据集中删除了测试类别。表示该模型已在MS COCO数据集上进行了微调。
5.2.2 MS COCO数据集
在表5中,我们将我们的方法1与MS COCO minival集上的特征权重[10]和Meta R-CNN [12]进行了比较。我们遵循他们的数据划分并使用相同的评估协议:我们将PASCAL VOC中包含的20个类别设置为评估的新类别,并将MS COCO中的其余60个类别用作培训类别。在相同的MS COCO训练数据集下,我们经过微调的模型在性能上比Meta R-CNN高出2.4%/ 1.3%/ 4.0%一个P/一P50/一P75指标。这证明了我们的模型具有强大的学习和泛化能力,并且在少数情况下,学习一般匹配关系比学习特定类别嵌入的尝试更有希望[10],[12]。我们针对FSOD进行训练的模型在7.9%/ 12.2%/ 9.5%的基础上实现了更显着的改进一个P/一P50/一P75指标。请注意,我们在FSOD数据集上训练的模型无需进一步微调即可直接应用于新颖类别,而所有其他方法均使用10种support进行微调以适应新颖类别。同样,在不进行微调的情况下,我们的FSOD训练模型已经在SOTA中发挥了最佳作用。
表6 在200种新颖类别的FSOD测试集上的实验结果,在新颖类别检测中评估了5种support,表示该模型已在FSOD数据集上进行了微调

5.3 现实应用
我们将我们的方法应用于不同的实际应用场景中,以证明其泛化能力。图8显示了我们测试集中新类别上定性的1发物体检测结果。我们进一步将我们的方法应用于野生企鹅检测[64],并在图9中显示样本定性5针目标检测结果。
新颖的类别检测
考虑一下这种常见的现实世界应用场景:给定相册或电视连续剧中的大量图像而没有任何标签,任务是在给定的大量集合中注释一个新颖的目标对象(例如,火箭),而不知道其中包含哪些图像目标对象(如果存在)可以具有不同的大小和位置。为了减少体力劳动,一种解决方案是手动查找小样本包含目标对象的图像,为它们添加注释,然后应用我们的方法来自动注释图像集合中的其余对象。按照此设置,我们执行以下评估:我们混合FSOD数据集的所有测试图像,对于每个对象类别,我们选择5个包含目标对象的图像,以在整个测试集中执行这种新颖的类别对象检测。
我们将LSTD与[9]进行比较,后者需要通过将知识从源域转移到目标域来进行新颖类别的培训。但是,我们的方法可用于检测新颖类别的对象,而无需任何进一步的重新训练或微调,这与LSTD根本不同。为了进行经验比较,我们将LSTD调整为基于Faster R-CNN,并以公平配置分别针对每个测试类别在5个固定支撑上对其进行重新训练。结果示于表6。在200个测试类别中,我们的方法比LSTD的性能高3.3%/ 5.9%,其骨干Faster R-CNN的性能高4.5%/ 6.5%。一种P50/一P75指标。更具体地说,如果没有对我们的数据集进行预训练,Faster R-CNN的性能将大大下降。请注意,由于模型仅知道support类别,因此基于微调的模型需要分别训练每个类别,这非常耗时。
野车检测
我们将方法2应用于KITTI [52]和Cityscapes [65]数据集上的野车检测,这些数据集是用于驾驶应用的城市场景数据集,其中图像由车载摄像机捕获。我们使用7481张图像和500张图像的Cityscapes验证集评估了汽车类别在KITTI训练集上的表现。DA Faster R-CNN [66]使用来自源域(KITTI / Cityscapes)的大量注释数据和来自目标域(Cityscapes / KITTI)的未标记数据来训练域自适应Faster R-CNN,并评估目标域的性能。无需任何进一步的重新训练或微调,我们的带有10发支撑的模型可获得可比甚至更好的模型一种P50在野外车辆检测任务中的性能(在Cityscapes上分别为37.0%和38.5%,在KITTI上分别为67.4%和64.1%)。请注意,DA Faster R-CNN是专为野车检测任务而设计的,并且它们在相似领域中使用更多的训练数据。
图8. 我们在FSOD测试仪上的方法的定性1次检测结果。放大附图以获取更多视觉细节。

图9. 我们的应用结果在企鹅数据集上[64]。给定5个企鹅图像作为support,我们的方法可以检测给定query图像中所有野生企鹅
5.4 其他分类与更多的样本?
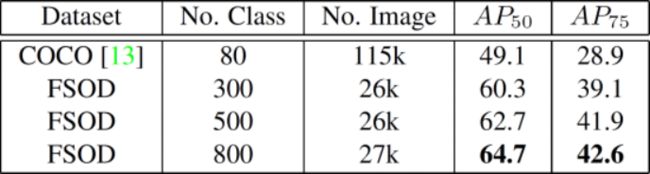
我们提出的数据集具有大量的对象类别,但每个类别中的图像样本都很少,因此我们认为这有利于小样本拍摄对象的检测。为了确认这种好处,我们在MS COCO数据集上训练了模型,该数据集包含115,000张图像和仅80个类别。然后,我们在具有不同类别编号的FSOD数据集上训练模型,同时保持相似数量的训练图像。表7总结实验结果,我们发现尽管MS COCO的训练图像最多,但其模型性能却最差,而在FSOD数据集上训练的模型随着类别数量的增加而保持较好的训练性能,但具有更好的性能。图像,这表明有限数量的类别具有太多图像实际上会阻碍小样本拍摄对象的检测,而大量类别则可以始终使任务受益。因此,我们得出结论,类别多样性对于小样本目标检测至关重要。
表7 我们在5种5次评估中使用不同数量的训练类别和图像的FSOD测试集模型的实验结果。
六、结论
我们介绍了一种具有注意力-RPN,多关系检测器和对比训练策略的新型小样本目标检测网络。我们贡献了一个新的FSOD,其中包含1000个类别的各种对象以及高质量的注释。我们在FSOD上训练的模型可以检测不需要预先训练或进一步进行网络适应的新颖类别的对象。我们的模型已通过对不同数据集的大量定量和定性结果验证。本文为小样本物体检测做出了贡献,并且我们相信,具有上述技术贡献的大规模FSOD数据集和检测网络可以产生有价值和相关的未来工作。