深度学习笔记------循环神经网络RNN
深度学习笔记------循环神经网络RNN
-
- 抽象模型
-
- 马尔可夫性
- 马尔可夫链
- 循环神经网络
-
- 模型
- 核心
- 共享
- 训练
- 衰减与爆炸
- 结构
- 缺点
抽象模型
马尔可夫性
这是一个概率论的概念,即:
P ( x t + 1 ∣ . . . , x t − 1 , x t ) = P ( x t + 1 ∣ x t ) P(x_{t+1}|...,x_{t-1},x_{t})=P(x_{t+1}|x_{t}) P(xt+1∣...,xt−1,xt)=P(xt+1∣xt)
通俗的解释就是关于时间的事件序列x,其发生的状态的情况仅仅与当前时刻的事件有关与更早的事件是无关的。这一性质描述了一个随机过程无记忆的特性。
马尔可夫链
上面定义无记忆的过程也定义了马尔可夫链,也就是对应的 x t x_t xt为离散时间马尔可夫链,对应的下一时间的状态仅仅与当前的状态相关,相关量的数量为1,如果推广一下到2,3,4,5…于是有当下一时间的状态与过去发生过的两个时间序列相关为:
P ( x 3 ∣ x 0 , x 1 , x 2 ) = P ( x 3 ∣ x 1 , x 2 ) P(x_3|x_0,x_1,x_2)=P(x_3|x_1,x_2) P(x3∣x0,x1,x2)=P(x3∣x1,x2)
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 4 ∣ x 2 , x 3 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)P(x_4|x_2,x_3) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x1,x2)P(x4∣x2,x3)
其对应为二阶的马尔可夫链,同样更大阶数的马尔可夫链也是相同的方法推导。
最终我们获得了一个通过之前多个时间序列来推导下一时间序列的抽象模型。
循环神经网络
与全连接神经网络不同,RNN体现了一种时间相关性,而其时间相关性的实现便是通过隐藏状态体现,隐藏状态记录了之前时间步的信息,之后传递到下一时间步参与运算,如此往后,循环进行,以此实现一个时序相关的计算过程。
模型
循环神经网络的结构具有很高的重复性,相比于卷积与全连接其显得比较规整,也正因为规整与重复的结构才对应了相应的循环运算。

图中的x为输入,h为产生的隐藏状态,每个单元之间的箭头都是上一单元的隐藏状态,注意 x t x_t xt是某一时间的状态序列,可能是单变量的一个值,也可能是多变量的数据,描述时间点的相关信息。
核心
其中核心的计算就是关于隐藏变量的计算过程,这里与一般的神经网络进行类比:
全连接中的运算是一个线性运算之后进行一个激活函数
H = ϕ ( X W i + b i ) H=\phi(XW_i+b_i) H=ϕ(XWi+bi), W W W为对应层的参数, b b b为对应的偏置量, ϕ \phi ϕ为相应的激活函数。
RNN中的计算过程多了一个隐藏状态的权重计算:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) H_t=\phi(X_tW_{xh}+H_{t-1}W_{hh}+b_h) Ht=ϕ(XtWxh+Ht−1Whh+bh),对应的x是一个时间点的信息, H t − 1 H_{t-1} Ht−1为上一时间点的状态信息, b h b_h bh为对应的偏置量, ϕ \phi ϕ为相应的激活函数, W x h , W h h W_{xh},W_{hh} Wxh,Whh为隐藏层的参数, b h b_h bh为偏置。
特殊的当为0时,也就是初始时,上一时间点不存在,于是有
H 0 = ϕ ( X 0 W x h + b h ) H_0=\phi(X_0W_{xh}+b_h) H0=ϕ(X0Wxh+bh)
类比输出层的处理为:
O = H W h q + b q O=HW_{hq}+b_q O=HWhq+bq(全连接)
O t = H t W h q + b q O_t=H_tW_{hq}+b_q Ot=HtWhq+bq(RNN)
共享
最终得到一个循环计算:
{ H 0 = ϕ ( X 0 W x h + b h ) H t = ϕ ( X t W x h + H t − 1 W h h + b h ) \left\{\begin{array}{lr} H_0=\phi(X_0W_{xh}+b_h)\\H_t=\phi(X_tW_{xh}+H_{t-1}W_{hh}+b_h)\end{array} \right. {H0=ϕ(X0Wxh+bh)Ht=ϕ(XtWxh+Ht−1Whh+bh)
O t = H t W h q + b q O_t=H_tW_{hq}+b_q Ot=HtWhq+bq
这里的参数 W , b W,b W,b等在不同的时间点都是使用相同的参数,所以其参数的量不会随时间变化增大。这个可以类比在全连接中的参数共享,RNN中的参数共享就是在各个时间点都使用相同的参数,这样对于不同长度的序列其都可以表现出较好的特征提取。
训练
代价函数与全连接相似可以定义为: L = 1 T ∑ t = 1 T l ( o t , y t ) L=\frac{1}{T}\sum_{t=1}^{T}l(o_t,y_t) L=T1∑t=1Tl(ot,yt)
l l l可以简单的取一下欧式距离或者其他的计算。
之后就是"喜闻乐见"的反向传播,这里叫通过时间反向传播(BPTT)
我们的目标是 W h q , W x h , W h h , b h , b q W_{hq},W_{xh},W_{hh},b_h,b_q Whq,Wxh,Whh,bh,bq
链式法则可以得到对应的偏导路径
∂ L ∂ W h q = ∑ t = 1 T ∂ L ∂ o t ∂ o t ∂ W h q = ∑ t = 1 T ∂ L ∂ o t H t T \frac{\partial L}{\partial W_{hq}}=\sum_{t=1}^{T}\frac{\partial L}{\partial o_{t}}\frac{\partial o_{t}}{\partial W_{hq}}=\sum_{t=1}^{T}\frac{\partial L}{\partial o_{t}}H_t^T ∂Whq∂L=∑t=1T∂ot∂L∂Whq∂ot=∑t=1T∂ot∂LHtT
∂ L ∂ b q = ∑ t = 1 T ∂ L ∂ o t \frac{\partial L}{\partial b_q}=\sum_{t=1}^{T}\frac{\partial L}{\partial o_{t}} ∂bq∂L=∑t=1T∂ot∂L
∂ L ∂ W h x = ∑ t = 1 T ∂ L ∂ h t ∂ h t ∂ W h x = ∑ t = 1 T ∂ L ∂ h t x t T \frac{\partial L}{\partial W_{hx}}=\sum_{t=1}^{T}\frac{\partial L}{\partial h_{t}}\frac{\partial h_{t}}{\partial W_{hx}}=\sum_{t=1}^{T}\frac{\partial L}{\partial h_{t}}x_t^T ∂Whx∂L=∑t=1T∂ht∂L∂Whx∂ht=∑t=1T∂ht∂LxtT
∂ L ∂ W h h = ∑ t = 1 T ∂ L ∂ h t ∂ h t ∂ W h h = ∑ t = 1 T ∂ L ∂ h t H t − 1 T \frac{\partial L}{\partial W_{hh}}=\sum_{t=1}^{T}\frac{\partial L}{\partial h_{t}}\frac{\partial h_{t}}{\partial W_{hh}}=\sum_{t=1}^{T}\frac{\partial L}{\partial h_{t}}H_{t-1}^T ∂Whh∂L=∑t=1T∂ht∂L∂Whh∂ht=∑t=1T∂ht∂LHt−1T
∂ L ∂ b h = ∑ t = 1 T ∂ L ∂ h t \frac{\partial L}{\partial b_h}=\sum_{t=1}^{T}\frac{\partial L}{\partial h_{t}} ∂bh∂L=∑t=1T∂ht∂L
衰减与爆炸
上面的偏导中重复的出现了 ∂ L ∂ h t \frac{\partial L}{\partial h_{t}} ∂ht∂L,由于循环运算,其偏导的路径不只是 ∂ L ∂ o t ∂ o t ∂ h t \frac{\partial L}{\partial o_{t}}\frac{\partial o_{t}}{\partial h_{t}} ∂ot∂L∂ht∂ot,而是:
∂ L ∂ h t = ∂ L ∂ h t + 1 ∂ h t + 1 ∂ h t + ∂ L ∂ o t ∂ o t ∂ h t = W h h T ∂ L ∂ h t + 1 + W q h T ∂ L ∂ o t \frac{\partial L}{\partial h_{t}}=\frac{\partial L}{\partial h_{t+1}}\frac{\partial h_{t+1}}{\partial h_{t}}+\frac{\partial L}{\partial o_{t}}\frac{\partial o_{t}}{\partial h_{t}}=W_{hh}^T\frac{\partial L}{\partial h_{t+1}}+W_{qh}^T\frac{\partial L}{\partial o_{t}} ∂ht∂L=∂ht+1∂L∂ht∂ht+1+∂ot∂L∂ht∂ot=WhhT∂ht+1∂L+WqhT∂ot∂L
这是一个递归式,进一步展开有:
∂ L ∂ h t = W h h T ( W h h T ∂ L ∂ h t + 2 + W q h T ∂ L ∂ o t + 1 ) + W q h T ∂ L ∂ o t \frac{\partial L}{\partial h_{t}}=W_{hh}^T(W_{hh}^T\frac{\partial L}{\partial h_{t+2}}+W_{qh}^T\frac{\partial L}{\partial o_{t+1}})+W_{qh}^T\frac{\partial L}{\partial o_{t}} ∂ht∂L=WhhT(WhhT∂ht+2∂L+WqhT∂ot+1∂L)+WqhT∂ot∂L
∂ L ∂ h t = W h h T ( W h h T ( W h h T ∂ L ∂ h t + 3 + W q h T ∂ L ∂ o t + 2 ) + W q h T ∂ L ∂ o t + 1 ) + W q h T ∂ L ∂ o t \frac{\partial L}{\partial h_{t}}=W_{hh}^T(W_{hh}^T(W_{hh}^T\frac{\partial L}{\partial h_{t+3}}+W_{qh}^T\frac{\partial L}{\partial o_{t+2}})+W_{qh}^T\frac{\partial L}{\partial o_{t+1}})+W_{qh}^T\frac{\partial L}{\partial o_{t}} ∂ht∂L=WhhT(WhhT(WhhT∂ht+3∂L+WqhT∂ot+2∂L)+WqhT∂ot+1∂L)+WqhT∂ot∂L…
最终得到通式为: ∂ L ∂ h t = ∑ i = t T ( W h h T ) T − i W q h T ∂ L ∂ o T + t − i \frac{\partial L}{\partial h_{t}}=\sum_{i=t}^{T}(W_{hh}^T)^{T-i}W_{qh}^T\frac{\partial L}{\partial o_{T+t-i}} ∂ht∂L=∑i=tT(WhhT)T−iWqhT∂oT+t−i∂L
当时间步数T较大或者t较小时,多个梯度的乘法很容易产生梯度的爆炸或者消失,对应对 ∂ L ∂ h t \frac{\partial L}{\partial h_{t}} ∂ht∂L的影响会传播到其他的梯度计算中。
结构
上面的循环神经网络是最常用的,其相应的还有一些其他的结构:
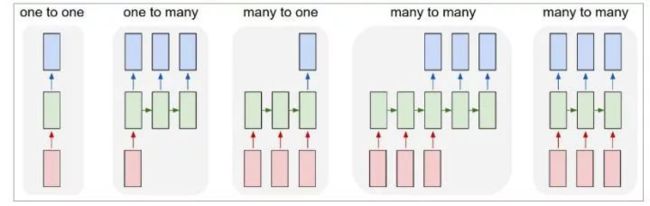
大致的可以了解一下,第一个就是普通的神经网络,第二个是将单一输入来预测输出,也可以拓展到三个时间点都有相同的输入,第三个有点神似于单个的三阶马尔可夫链,对应是一个序列输入到单个输出,第四个是一个有时差的序列转化,第五个就是一个无时差的序列转化。
缺点
从上面的结构中我们可以发现,RNN在理论上是可以存储较长时间前的相关特征,但是在实践实现中,模型中当前时间计算很难获得许久之前时间点的特征,或者说简单的RNN无法获得整个时间区域中有用的上下文信息,太久之前与当前时间点之后的信息都无法学习,虽然可以进行人为参数的挑选,但是在复杂问题上这一处理远远不够,这是简单的RNN在长期记忆中的缺陷。