三维点云语义分割的一些学习
文章目录
- 毕业设计三维点云的一些学习
- 补 *重新分析一下毕业设计的相关任务
- todo list
- 时间规划(待定,还没想好)
- 一些问题
- 实验内容
- 一些数据集
- 一些可能用到的网站
-
- 一些可能的工具
- 语义分割的资源+代码 主要是2D
- 自动驾驶点云处理文章(转自github)
- 卢策吾 PointSIFT
- pointnet作者讲解及相关资源
- 基于三维点云场景的语义及实例分割 牛津大学RandLA-Net作者杨波/胡庆拥
- 二维语义分割的一些学习
-
- 语义分割数据集
- 语义分割中的深度学习技术
- 三维(点云)语义分割概述以及方法总结11.8
- 这里是论文的详细学习 具体标注查看pdf
-
- GndNet: Fast Ground Plane Estimation and Point Cloud Segmentation for Autonomous Vehicles
- Deep Learning for 3D Point Clouds: A Survey.
-
- 5.1.1 基于投影的方法
- 5.1.2 基于离散化的方法
- 5.1.3 混合方法
- 5.1.4 Point-based Methods 基于点云的方法 重点来了
-
- Pointwise MLP Methods. 逐点 MLP 方法。
- Attention-based aggregation:基于注意力聚合的方法:
- 局部-全局信息共同处理Local-global concatenation:
- Point Convolution Methods点卷积法。
- RNN方法
- PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 这篇文章 三维视觉的深度学习的开山之作,之后所有的作品都是以pointnet 为基本https://github.com/anjinglala/ComprehensiveEvaluation1框架来进行搭建并提高的
-
- pointnet到pointnet++
- 回到pointnet 论文的学习
- RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) 以及-Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds (NeurIPS 2019) 牛津大学
- MLP多层感知机
毕业设计三维点云的一些学习
本文仅仅用于记录毕业设计三维点云语义分割的一些知识进度,如有侵权立删
补 *重新分析一下毕业设计的相关任务
任务基于朴素的想法,可以实现面对采集到的点云数据和图像数据,实现类别的划分
输入数据:
三维坐标x,y,z + 颜色 R,G,B (不知道这里理解的是否正确,能否通过联合标定矩阵实现RGB和3D点云的对齐?) 6维 数据 -------→ 输出一个类别 (grid-based representation )
或者 x,y,z 坐标 和照片 即输入 R,G,B,D -------→ 输出一个类别 (grid-based representation )
这里还需要考虑一个问题 ,数据维数过高会不会导致维数灾难问题
解决这个问题需要:
1 理解并操作数据点(1需要查找一些公开的数据集)
2 对数据点采用合适的语义分割方法,来实现M维输入,N维输出,目前看来主要是深度学习和几何方法(2需要学习基本的方法进行建模,读论文+创新 3 加强编程能力,重新学一遍数据结构和选定深度学习框架并学习)
11月11日:学习了pointnet后,感觉需要重点理解通pointnet,然后在pointnet的基础上调整。
3测试+ 实验(4确定选取哪些实验进行测试,目前看来有精确度,鲁棒性即点云缺失情况的实验效果,网络的量级。5选择baseline之类的 此为后话)
4创新点+可解释性(6这涉及到写论文部分,后话,主要是如何较好的表达使用的方法,学术英语写作得好好学习一下)
todo list
1.一周时间学习下数据结构与算法
2 一周时间学习下python + pytorch/TensorFlow fastAI
3 运行几个三维点云的demo
4.看论文+数学
5讲座
6 卷积神经网络在复习一遍 吴恩达在过一遍
7学习一下激光雷达的物理特性,看能不能从中发掘些什么
8 (不一定) 可以考虑接触一点三维激光slam,看看有没有帮助,现在的方法过分无视几何关系,看看能不能从这边搞一点东西出来。
9长期任务 李航统计学习方法过一遍
10 为了理解pointnet 得考虑把MLP的原理搞懂 以及卷积神经网络里面的一些操作比如maxpooling。
时间规划(待定,还没想好)
针对毕设:可能的情况是在point上对输入或输出做一些结构上的调整以解决我们的问题或是相近的目标(规划是两种方法结合然后voting)或是针对几何结构进行分析学习(需要结合视觉slam的一些知识来解决)
1看论文
2学代码
3写代码
一些问题
1 关于毕设中野外的定义,不是一个很明确的创新定义,如二维图像中野外可能环境比较复杂但好像对点云来说并不是一个创新点(不确定),再考虑一下。
可能的创新点是道路不平整,利用陀螺仪加雷达 联合消除影响
或者点云较稀疏 迷集中点云的一些特性来处理
2 (不一定)我想找做点云的学长聊一聊关于一些处理经验的问题(如果可能的话)(等我对整个点云领域再有了更多的理解),我想知道现在有经验的点云选手能够用什么方法完成一些什么工作或是大家都在用那些方法做了什么,(就比如物体检测方面现在成熟的算法如yolo可以实现当对一个物体拍摄一定的照片数据集后,可以实现实时的在每一帧的视频里识别出来这个物体)如果有不涉密的小demo写一下就更好了。因为单纯看代码没有讲一下的话确实理解起来比较困难。
3关于语义分割,现有的方法里面有没有针对稀疏矩阵或者不完整矩阵的语义分割方法?针对3D投影到2D生成不满的伪图像?
4关于毕设本身,如卢策吾老师所说,就工业角度(比赛角度),利用pointnet++及其衍生应该能够得到一定的不错的效果,但是甚至有可能比不上原来的二维图像转三维三维图像。(工业角度确实情况比较复杂,不好确定,更好的提升性能可能需要多写一些if/else)针对论文的话 可能的情况是pointnet+xxx 到具体领域的应用 或者观察目前的文章对点云的几何特性关注的比较少(有可能点云真的没有几何特性或是几何特性太复杂,不如直接利用数据挖掘等黑盒直接做出来)
5(不一定)考虑一些英语写作问题,该如何提高。
6(不一定)看了一些论文和综述,本来感觉想法还是挺多的,但是好像所有的想法都有人做过了,而理解通一个模型point并做调整难度确实太大了,而且不知道从何入手,比较迷茫。
实验内容
理论优异
实验分割效果
轻量级 快速 模型
missing data的分析 点丢失时精度的分析
消融实验 :消融实验(Ablation experiment)这个概念第一次出现是在论文《Faster R-CNN》中。
消融实验类似于“控制变量法”。
假设在某目标检测系统中,使用了A,B,C,取得了不错的效果,但是这个时候你并不知道这不错的效果是由于A,B,C中哪一个起的作用,于是你保留A,B,移除C进行实验来看一下C在整个系统中所起的作用。
————————————————
版权声明:本文为CSDN博主「房东丢的猫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gaolijing_/article/details/105626733
一些数据集
激光雷达
- SemanticKITTI J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A dataset for semantic scene
understanding of lidar sequences,” in ICCV, 2019 - A. Serna, B. Marcotegui, F. Goulette, and J.-E. Deschaud, “Parisrue-madame database: a 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification
methods,” in ICRA, 2014. - X. Roynard, J.-E. Deschaud, and F. Goulette, “Paris-lille-3d: A
large and high-quality ground-truth urban point cloud dataset
for automatic segmentation and classification,” IJRR, 2018.
RGB-D
- A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and
M. Nießner, “ScanNet: Richly-annotated 3D reconstructions of
indoor scenes,” in CVPR, 2017.
Modelnet40
shapenetpart dataset
stanford 2d-3d-s
一些可能用到的网站
一些可能的工具
SemanticKitti数据集 语义分割的数据集 直接从 官网下载
http://www.semantic-kitti.org/
- 可视化API
https://github.com/PRBonn/semantic-kitti-api
语义分割的资源+代码 主要是2D
https://github.com/mrgloom/awesome-semantic-segmentation
自动驾驶点云处理文章(转自github)
https://blog.csdn.net/m0_37870385/article/details/106182964
卢策吾 PointSIFT
您还可以考虑使用我们组(上海交大MVIG)刚刚推出的PointSIFT,代码开源。
MVIG-SJTU/pointSIFT
论文主页:http://www.mvig.org/publications/pointSIFT.html
在 Stanford Large-Scale 3D Indoor Spaces(S3DIS) 中可以达到 88.72 的 mAP(对比 PointNet 78.62, 相对提高 13%)。在另一个常用数据集Stanford ScanNet 上可以达到 86.0 的 mAP(对比 PointNet 73.23, 相对提高 17%)。
PointSIFT是一个通用的提高表征能力的算子模块,可以灵活地插入各种点云网络结构中
我们也超过了PointNet++和PointCNN,更多说明与比较在这里
pointnet作者讲解及相关资源
相关资源
1 将门创投 | 斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用 https://www.bilibili.com/video/BV1As411377S?spm_id_from=333.999.0.0 作者亲自讲解pointnet的设计思想
2 作者主页:https://stanford.edu/~rqi/
3相关ppt文字和文字记录
https://www.cnblogs.com/wangchangshuo/p/13884574.html 点云上的深度学习及其在三维场景理解中的应用(PPT内容整理PointNet)
点云深度学习的3D场景理解 https://www.cnblogs.com/Libo-Master/p/9759130.html
基于三维点云场景的语义及实例分割 牛津大学RandLA-Net作者杨波/胡庆拥
深蓝学院 基于三维点云场景的语义及实例分割 https://www.bilibili.com/video/BV1aE411T7Gf
-Introduction to point cloud segmentation
-RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020)
-Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds (NeurIPS 2019)
作者主页 https://yang7879.github.io/
https://qingyonghu.github.io/
二维语义分割的一些学习
引自 https://zhuanlan.zhihu.com/p/143261645
目前语义分割的应用领域主要有:
- 地理信息系统
- 无人车驾驶
- 医疗影像分析
- 机器人等领域
地理信息系统:可以通过训练神经网络让机器输入卫星遥感影像,自动识别道路,河流,庄稼,建筑物等,并且对图像中每个像素进行标注。(下图左边为卫星遥感影像,中间为真实的标签,右边为神经网络预测的标签结果,可以看到,随着训练加深,预测准确率不断提升。使用ResNet FCN网络进行训练)
**无人车驾驶:**语义分割也是无人车驾驶的核心算法技术,车载摄像头,或者激光雷达探查到图像后输入到神经网络中,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。

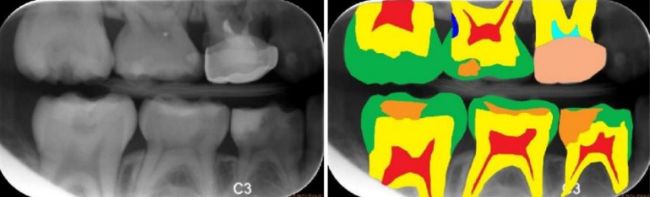
**医疗影像分析:**随着人工智能的崛起,将神经网络与医疗诊断结合也成为研究热点,智能医疗研究逐渐成熟。在智能医疗领域,语义分割主要应用有肿瘤图像分割,龋齿诊断等。(下图分别是龋齿诊断,头部CT扫描紧急护理诊断辅助和肺癌诊断辅助)

语义分割数据集
在“数据,算法,计算力”这AI发展的三大驱动力中,眼下最重要的就是数据,数据集在人工智能中有着举足轻重的地位,具体根据不同的应用领域,目前的数据集主要有:
- Pascal VOC系列: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/ 通常采用PASCAL VOC 2012,最开始有1464 张具有标注信息的训练图片,2014 年增加到10582张训练图片。主要涉及了日常生活中常见的物体,包括汽车,狗,船等20个分类。
- Microsoft COCO: http://link.zhihu.com/?target=http%3A//mscoco.org/explore/ 一共有80个类别。这个数据集主要用于实例级别的分割(Instance-level Segmentation)以及图片描述Image Caption)。
- Cityscapes: https://www.cityscapes-dataset.com/ 适用于汽车自动驾驶的训练数据集,包括19种都市街道场景:road、side-walk、building、wal、fence、pole、traficlight、trafic sign、vegetation、terain、sky、person、rider、car、truck、bus、train、motorcycle 和 bicycle。该数据库中用于训练和校验的精细标注的图片数量为3475,同时也包含了 2 万张粗糙的标记图片。
语义分割中的深度学习技术
- 全卷积神经网络 FCN(2015)
论文:Fully Convolutional Networks for Semantic Segmentation FCN 所追求的是,输入是一张图片是,输出也是一张图片,学习像素到像素的映射,端到端的映射,网络结构如下图所示:
全卷积神经网络主要使用了三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
卷积化(Convolutional)
卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。

上采样(Upsample)
有的说叫conv_transpose更为合适。因为普通的池化会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。为了得到和原图等大的分割图,我们需要上采样/反卷积。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。图解如下:
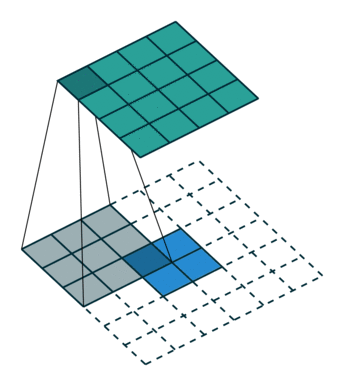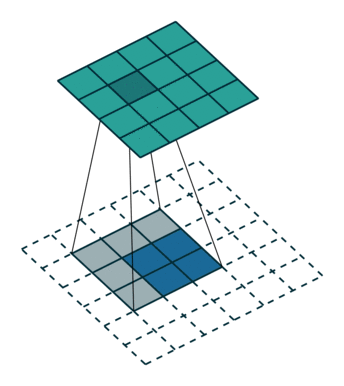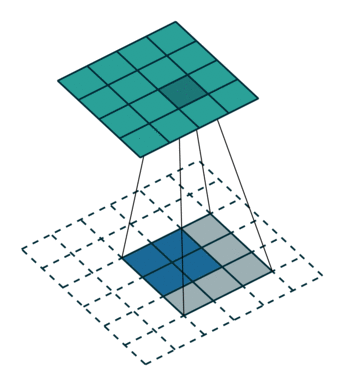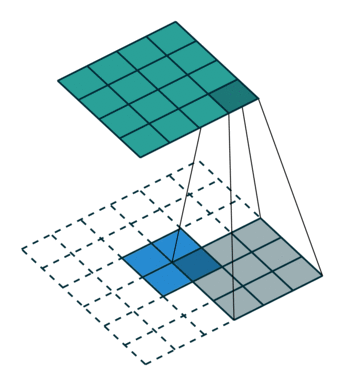
跳跃结构(Skip Layer)
这个结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。具体结构如下:

而不同上采样结构得到的结果对比如下:

这是第一种结构,也是深度学习应用于图像语义分割的开山之作,获得了CVPR2015的最佳论文。但还是无法避免有很多问题,比如,精度问题,对细节不敏感,以及像素与像素之间的关系,忽略空间的一致性等,后面的研究极大的改善了这些问题。
- SegNet(2015)
论文:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
主要贡献:将最大池化指数转移至解码器中,改善了分割分辨率。 - 空洞卷积(2015)
论文:Multi-Scale Context Aggregation by Dilated Convolutions
主要贡献:使用了空洞卷积,这是一种可用于密集预测的卷积层;提出在多尺度聚集条件下使用空洞卷积的“背景模块”。 - DeepLab(2016)
论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
主要贡献:使用了空洞卷积;提出了在空间维度上实现金字塔型的空洞池化atrous spatial pyramid pooling(ASPP);使用了全连接条件随机场。
三维(点云)语义分割概述以及方法总结11.8
-1. 语义分割
语义分割需要两部分
classification: 需要全局信息
segmentation:更加依赖全局信息和局部信息
一般的网络结构是:
提特征-特征映射-特征图压缩(降维)-全连接-分类,其实就是encoder-decoder的过程,
比如在二维的的pspnet,fcn等等, 可能还有CRF去调整
0. 三维表示的数据结构
PointSIFT中给了一些具体的论文
0.1. Point cloud
本质是对三维世界几何形状的低分辨率重采样,因此只能提供片面的几何信息
点云的一些feature:
-
- normal 法向量 - intensity 激光雷达的采样的时候一种特性 强度信息的获取是激光扫描仪接受装置采集到的回波强度,此强度信息与目标的表面材质、粗糙度、入射角方向,以及仪器的发射能量,激光波长有关 - local density 局部稠密度 - local curvature 局部曲率 - linearity, planarity and scattering propesed by [this paper]Dimension- ality based scale selection in 3D lidar point clouds - verticality feature proposed by Weakly supervised segmentation-aided classification of urban scenes from 3d LiDAR point clouds -
无序性
点云实际上是无序的,比如有8个点云,你放到矩阵里面,是有顺序的,但是实际上打乱顺序也都表示的是同样的一个点云。换句话说,不同的矩阵表示的是同一个点云,而你分割的结果肯定不可能对于不同的输入表示矩阵,结果不一样。
如果有N个点,就需要对N!permutations invariant
解决方法:
-
sorting
但是实际上不存在这样一个稳定的从高纬度到1维度的映射 -
RNN
-
数据的一些抖动也得到了增强
symmetric function -
几何旋转性:
相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化。
不论点云在怎样的坐标系下呈现,网络都能正确的识别出。这个问题可以通过STN(spatial transform network)来解决。二维的可以看一下这个,实际上就是一些放射变换之类的。
Point cloud rotations should not alter classification results -
抽密度不均匀
采样的时候,点云的稠密度,一般是不一样的,距离镜头近的物体点云稠密度比较大,距离远的比较稀疏。如下图:
也有一些方法去解决这种问题,比如
PU-Net: Point Cloud Upsampling Network
这几点就要求在点云的处理过程要非常的鲁棒。
- 不规则性
点云不像grid和pixel,有很规范的格式,所以并不能直接的采用CNN,这是一个很严重的问题。当然也有一些提出一些直接能够对点云做操作的网络,Pointwise Convolutional Neural Networks Binh-Son,但是从效果看起来,似乎比pointnet要差一些,但是不是差的特别大,有些地方有略超过pointnet的地方,但是我觉得计算量。。。。。。。会很大
还有一些方式比如就是将点云转换成其他方式,SegCloud uses 3D con- volutions on a regular voxel grid,但是点云转换成volme的方法效率很低,而且这个过程丢失掉一些细节
0.2 3D voxel grids
类似二维的三维卷积,是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了;
体素的方式呢,SPG的作者认为do not capture the inherent structure of 3D point clouds
Subvolume
voxelnet
0.3 collections of images/muti-view
这样的好处是可以直接采用一些二维的算子去处理,特征被view pooling procedure聚合起来形成三维物体;
MVCNN
0.4 polygon
可以运用一些mesh的表达和合适的算法,比如三角剖分等等。
Point cloud is close to raw sensor data, and is canonical
这三种数据结构是可以相互转换的,但是貌似三维结构的表示相互转换,时间复杂度比价高
export the point cloud to the 3D voxel
在地形图表示的时候的区别
Polygons, Points, or Voxels? Stimuli Selection for Crowdsourcing Aesthetics Preferences of 3D Shape Pairs
————————————————
版权声明:本文为CSDN博主「莫子风」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/renhaofan/article/details/84025603
- PointNet
还是需要去看一下symmetric function那里
主页 | 论文 | 补充材料 | Code | 会议报告讲解论文视频 | 作者答疑解惑 | 作者中文讲解视频 | Open3D-PointNet
time:Dec 2, 2016
Input: coordinates(x,y,z)
Output: labels. added by computing normals and other local or global features
在这个网络之前其他的方式都是对三维数据表达进行转换变成规则, 比如:
voxelization ----- 3D CNN
Projection/rendering — 2D CNN
1.1 提升准确度的关键步骤
1.1.1. 解决无序性
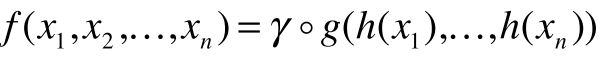
用来解决unorder set的问题。
所谓对称函数,比如f(x1,x2) = x1 + x2, 互换x1,x2不影响结果。就是unorder set问题的一个数学表述
开坑 :【论文阅读】【综述】Deep Learning for 3D Point Clouds: A Survey_麒麒哈尔的博客-CSDN博客
https://blog.csdn.net/wqwqqwqw1231/article/details/104206664
这里是论文的详细学习 具体标注查看pdf
GndNet: Fast Ground Plane Estimation and Point Cloud Segmentation for Autonomous Vehicles
作者Anshul Paigwar github https://github.com/anshulpaigwar 里面有一些点云处理的工作
主要工作 :地平面估计和地面的分割 在扩充的SemanticKITTI dataset上,是一种端到端的方法,同时在作者的介绍下是可以达到实时的的效果 runtime of 55HZ
网络结构 :输入为原始点云 输出为栅格化的高程估计及分割(利用高程数据)
利用这张图可以较好的解释[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7lrCIytx-1637327148549)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211110214529390.png)]
首先将区域划分为网格(论文里为100*100),对每个栅格里的点,考虑其相对于栅格中心点的距离xc,yc,zc及栅格的序号xp; yp,得到新的5个维度的特征(xc; yc; zc; xp; yp),结合原有的四个特征,我们可以把点云数据变为一个9维的特征4-dimension到9-dimension。
由于点云的稀疏性,一大组支柱大部分是空的,而非空支柱通常只有几个点。我们固定了每根柱子的点数N,以创建一个大小为(D;P;N)的稠密张量,其中P是非空柱子的数目。如果一根柱子上有N个以上的点,那么我们随机抽取这些点来拟合张量。相反,如果支柱的数据点太少,则应用零填充填充张量
支柱特征编码与伪图像
接下来,我们使用简化版的PointNet提取每个非空支柱的特征。我们的简化点网由一个线性层组成,该层应用于每个点,然后是Batchnorm和ReLU,以生成(C,P,N)大小的张量。
然后,通道上的最大池操作创建大小为(C,P)的输出张量。然后将这些编码的柱特征放置到栅格中的原始位置,以创建大小为(C、H、W)的伪图像,其中H和W表示栅格的高度和宽度。注:这一段有点没看懂,得看看代码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8RaoT6h-1637327148551)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211111094902313.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qon2taHb-1637327148552)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211111094944930.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lNnIbHOQ-1637327148554)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211111095227880.png)]
这一段来说看这张图,意思是如何利用所给的kitt数据集来构造出我们需要的数据集,即给数据集取出其中的道路点投影到100*100的网格里,然后为了使得图像更为光滑,作者给出了两种方法,一种是图像进行膨胀腐蚀等操作等图像方法实现平滑,另一种是利用CRF方法,最终得到了我们的训练集
随后作者定义了loss
Deep Learning for 3D Point Clouds: A Survey.
综述类文章,讲了讲deep learning 在3维点云中的应用 注 中国人写英语真的容易看懂!
3D数据的表达方式 depth images, point clouds, meshes, and
volumetric grids
datasets:ModelNet [6], ScanObjectNN [7], ShapeNet [8], PartNet [9],S3DIS [10], ScanNet [11], Semantic3D [12], ApolloCar3D[13], and the KITTI Vision Benchmark Suite
problems: 3D shape classification, 3D object detection and tracking, 3D point cloud segmentation,3D point cloud registration, 6-DOF pose estimation, and 3D reconstruction
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tYekA71r-1637327148556)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211111200250847.png)]
针对毕设任务的三维点云分割如图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RgPjf7dX-1637327148558)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211111200357424.png)]
针对3D point cloud segmentation
datasets: 不同的传感器:Mobile Laser Scanners (MLS) [15], [34], [36], Aerial Laser Scanners (ALS) [33], [38], static Terrestrial Laser Scanners (TLS) [12], RGBD cameras [11] and other 3D scanners
数据集合集:
激光雷达
- SemanticKITTI J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A dataset for semantic scene
understanding of lidar sequences,” in ICCV, 2019 - A. Serna, B. Marcotegui, F. Goulette, and J.-E. Deschaud, “Parisrue-madame database: a 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification
methods,” in ICRA, 2014. - X. Roynard, J.-E. Deschaud, and F. Goulette, “Paris-lille-3d: A
large and high-quality ground-truth urban point cloud dataset
for automatic segmentation and classification,” IJRR, 2018.
RGB-D
- A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and
M. Nießner, “ScanNet: Richly-annotated 3D reconstructions of
indoor scenes,” in CVPR, 2017.
challenges : distractors, shape incompleteness, and class imbalance.
Evaluation Metrics: Overall Accuracy (OA), mean Intersection over Union (mIoU) and mean class Accuracy (mAcc) mean Average Precision (mAP)
语义分割有四种模式: projection-based基于投影的, discretizationbased,基于离散化的 point-based给予点的, and hybrid methods混合的.
3D point cloud segmentation requires the understanding of both the global geometric structure and the fine-grained details of each point
问题的分类: semantic segmentation (scene level),instance segmentation (object level) and part segmentation (part level).
投影projection和离散化discretization-based methods 首先要做的是把输入的点云转化为正则表达( transform a point cloud to an intermediate regular representation,)
如multi-view [181],[182], spherical [183], [184], [185], volumetric [166], [186],[187], permutohedral lattice [188], [189], and hybrid representations [190], [191],
然后我们在正则化的形式上进行语义分割等操作,得到结果后我们在反推会原来的点云得到结果(The intermediate segmentation results are then projected back to the raw point cloud.)
与此不同的是,基于点的方法直接在无规则的点云上进行操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u7gugc3x-1637327148560)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211112093356432.png)]
这张图显示了各个方法的发展
5.1.1 基于投影的方法
Multi-view Representation 多视角方法 核心思想是将3D的点云投影到多个2D视角,然后利用multi-stream FCN结构来预测 pixel-wise scores像素级分数,最终通过融合各个不同视角上的分数(投票方法)来得出最终的结论。(单纯从点云投影到2维)
A. Boulch, B. Le Saux, and N. Audebert, “Unstructured point
cloud semantic labeling using deep segmentation networks.” in
3DOR, 2017.
首先使用多个相机位置生成点云的几个RGB和深度快照。 然后,他们使用 2D 分割网络对这些快照进行逐像素标记。 使用残差校正进一步融合从 RGB 和深度图像预测的分数。
将点云从三维投影到RGB-D图像上
基于点云是从局部欧几里得表面采样的假设,Tatarchenko 等人。 引入了用于密集点云分割的切线卷积。 该方法首先将每个点周围的局部表面几何投影到虚拟切平面。 然后直接在表面几何上操作切线卷积。 这种方法显示出很好的可扩展性,能够处理具有数百万个点的大规模点云。
局限性:多视图分割方法的性能对视点选择和遮挡很敏感。 此外,这些方法还没有充分利用底层的几何和结构信息,因为投影步骤不可避免地会引入信息丢失
Spherical Representation球面表示
To achieve fast and accurate segmentation of 3D point clouds, Wu et al. [183] proposed an end-to-end network based on SqueezeNet [194] and Conditional Random Field (CRF).
在其中准确性上的改进 SqueezeSegV2 address domain shift by utilizing an unsupervised domain adaptation pipeline. 利用无监督的域适应来解决域转移
RangeNet++ 用于 LiDAR 点云的实时语义分割。
2D 范围图像的语义标签首先转移到 3D 点云,进一步使用基于 GPU 的高效 KNN 后处理步骤来缓解离散化错误和模糊推理输出的问题。 与单视图投影相比,球面投影保留了更多的信息,适用于激光雷达点云的标注。
存在的问题:离散化错误及偶然误差较大
5.1.2 基于离散化的方法
这些方法通常将点云转换为密集/稀疏的离散表示,例如体积和稀疏排列的格子。(这种想法跟我的想法重复了)
密度离散化表示。 早期的方法通常将点云体素化为密度网格,然后利用标准的 3D 卷积。
首先将点云划分为一组占用体素,然后将这些中间数据馈送到全 3D CNN 以进行体素分割。 这一段理解一下 是将点云转化为体素,然后进行语义分割。最后,体素内的所有点都被分配与体素相同的语义标签。这种方法的性能受到体素粒度和点云分区引起的边界伪影的严重限制。
J. Huang and S. You, “Point cloud labeling using 3D convolutional neural network,” in ICPR, 2016.
SEGCloud 实现细粒度、全局一致的语义分割。 该方法引入了确定性三线性插值,将 3D-FCNN [197] 生成的粗体素预测映射回点云,然后使用全连接 CRF (FCCRF) 来强制这些推断的每点标签的空间一致性。
引入了一种基于内核的内插变分自编码器架构来对每个体素内的局部几何结构进行编码。 代替二进制占用表示,对每个体素采用 RBF 以获得连续表示并捕获每个体素中点的分布。 VAE 进一步用于将每个体素内的点分布映射到紧凑的潜在空间。 然后,对称群和等价 CNN 都用于实现稳健的特征学习。(基于核方法,我完全没看懂)
H.-Y. Meng, L. Gao, Y.-K. Lai, and D. Manocha, “VV-Net: Voxel
vae net with group convolutions for point cloud segmentation,”
in ICCV, 2019
由于 3D CNN 良好的可扩展性,基于体积的网络可以自由地在具有不同空间大小的点云上进行训练和测试。 在全卷积点网络 (FCPN) [187] 中,首先从点云中分层抽象出不同级别的几何关系,然后使用 3D 卷积和加权平均池化来提取特征并合并远程依赖关系。 该方法可以处理大规模点云,并且在推理过程中具有良好的可扩展性。
ScanComplete 实现 3D 扫描完成和每体素语义标记。 该方法利用了全卷积神经网络的可扩展性,可以在训练和测试期间适应不同的输入数据大小。 使用从粗到细的策略来分层提高预测结果的分辨率。
总体而言,体素(volumetric representation)表示自然地保留了 3D 点云的邻域结构。 其常规数据格式还允许直接应用标准 3D 卷积。 这些因素导致该领域的性能稳步提高。 然而,体素化步骤固有地引入了离散化伪影和信息丢失。 通常,高分辨率会导致高内存和计算成本,而低分辨率会导致细节丢失。 在实践中选择合适的网格分辨率并非易事。
Sparse Discretization Representation稀疏离散化表示
体积表示自然是稀疏的,因为非零值的数量只占很小的百分比。 因此,在空间稀疏的数据上应用密集卷积神经网络是低效的为此,提出了基于索引结构的子流形稀疏卷积网络。 该方法通过将卷积的输出限制为仅与占用的体素相关,从而显着降低了内存和计算成本。**(这就是我所想的稀疏矩阵的卷积神经网络)**这种子流形稀疏卷积适用于高维和空间稀疏数据的高效处理。
此外,Choy 等人提出了一种名为 MinkowskiNet 的 4D 时空卷积神经网络,用于 3D 视频感知。 提出了一种广义稀疏卷积来有效处理高维数据。 进一步应用三边平稳条件随机场以加强一致性。
另一方面,Su 等人。 [188] 提出了基于双边卷积层(BCL)的稀疏格网络(SPLATNet)。 该方法首先将原始点云内插到一个 permutohedral 稀疏点阵,然后应用 BCL 对稀疏填充点阵的占用部分进行卷积。 然后将过滤后的输出插回到原始点云。 此外,该方法允许多视图图像和点云的灵活联合处理。
此外,罗苏等人。 [189] 提出了 LatticeNet 来实现对大型点云的高效处理。 还引入了一个名为 DeformsSlice 的依赖于数据的插值模块,用于将点阵特征反投影到点云。(有时间看一看,完全没看懂)
5.1.3 混合方法
为了进一步利用所有可用信息,已经提出了几种方法来从 3D 扫描中学习多模态特征。 Dai 和 Nießner [190] 提出了一个联合 3D 多视图网络来结合 RGB 特征和几何特征。 一个 3D CNN 流和几个 2D 流用于提取特征,并提出了一个可微的反投影层来联合融合学习到的 2D 嵌入和 3D 几何特征。 此外,蒋等人。 [200] 提出了一个统一的基于点的框架来从点云中学习 2D 纹理外观、3D 结构和全局上下文特征。 该方法直接应用基于点的网络从稀疏采样的点集中提取局部几何特征和全局上下文,无需任何体素化。 贾里茨等人。 [191] 提出了多视图点网络(MVPNet)来聚合来自 2D 多视图图像的外观特征和规范点云空间中的空间几何特征。(这一段没有仔细看)
5.1.4 Point-based Methods 基于点云的方法 重点来了
基于点的网络直接作用于不规则的点云。 然而,点云是无序和非结构化的,直接应用标准 CNN 是不可行的。
为此,提出了开创性工作 PointNet 使用共享 MLP 学习每点特征,使用对称池化函数学习全局特征。 基于PointNet,最近提出了一系列基于点的网络。 总的来说,这些方法大致可以分为pointwise MLP方法、点卷积方法、RNNbased方法和graph-based方法。
Pointnet 开创性的工作
Pointwise MLP Methods. 逐点 MLP 方法。
通常使用共享 MLP 作为其网络中的基本单元,以提高效率。 然而,共享 MLP 提取的逐点特征无法捕获点云中的局部几何形状以及点之间的相互交互 。 为了捕捉每个点的更广泛的上下文并学习更丰富的局部结构,已经引入了几个专用网络,
包括基于相邻特征池、基于注意力的聚合和局部-全局特征连接的方法
neighboring feature pooling, attentionbased aggregation, and local-global feature concatenation.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nvv33LsT-1637327148562)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211116144601573.png)]
Neighboring feature pooling:
为了捕捉局部几何图案,这些方法通过聚合来自局部相邻点的信息来学习每个点的特征。 特别是,PointNet++ [54] 对点进行分层分组,并从较大的局部区域逐步学习,如图 12(a)所示。还提出了多尺度分组和多分辨率分组来克服点云不均匀和密度变化引起的问题。
后来,蒋等人。 [141] 提出了一个 PointSIFT 模块来实现方向编码和尺度感知。 该模块通过三级有序卷积堆叠和编码来自八个空间方向的信息。
串联多尺度特征以实现对不同尺度的适应性。 与 PointNet++ 中使用的分组技术(即球查询)不同,Engelmann 等人。 [204]利用K-means聚类和KNN分别定义世界空间和特征空间中的两个邻域。基于来自同一类的点预计在特征空间中更接近的假设,引入成对距离损失和质心损失以进一步规范特征学习。
考虑相互点之间的作用关系, PointWeb 通过密集构建局部全链接网络来探索局部区域中所有点对之间的关系。 点对的概念。提出了一种自适应特征调整Adaptive Feature Adjustment (AFA)模块来实现信息交换和特征细化。此聚合操作有助于网络学习区分性特征表示
Zhang等人[205]基于同心球壳(concentric spherical shells. )的统计数据,提出了一种称为Shellconv的置换不变卷积。该方法首先查询一组多尺度同心球体,然后在不同的壳内使用最大池运算来汇总统计信息,然后使用MLP和一维卷积来获得最终的卷积输出。
提出了一种称为 RandLA-Net 的高效轻量级网络,用于大规模点云分割。 该网络利用随机点采样在内存和计算方面实现了非常高的效率。
进一步提出了一个局部特征聚合模块来捕获和保留几何特征
Attention-based aggregation:基于注意力聚合的方法:
为了进一步提高分割精度,在点云分割中引入了注意力机制。
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.
Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”
in NeurIPS, 2017. 文章听起来有点意思
Yang等人[56]提出了一种群体洗牌注意模型来模拟点之间的关系,并提出了一种置换不变、任务不可知和可微的Gumbel子集抽样(GSS)permutation-invariant, task-agnostic and differentiable Gumbel Subset Sampling (GSS),以取代广泛使用的FPS方法。该模块对异常值不太敏感,可以选择具有代表性的点子集。
为了更好地捕捉点云的空间分布,提出了一种局部空间感知 Local Spatial Aware (LSA)层,用于根据点云的空间布局和局部结构学习空间感知权重。与CRF类似,Zhao等人[208]提出了一个基于注意的分数细化(ASR)模块,用于对网络产生的分割结果进行后处理。初始分割结果通过将相邻点的分数与学习到的注意权重相结合来细化。该模块可以很容易地集成到现有的深度网络中,以提高分段性能。
局部-全局信息共同处理Local-global concatenation:
Zhao等人提出了一种置换不变PS2网络,以结合点云的局部结构和全局上下文。Edgeconv和NetVLAD被反复叠加,以捕获局部信息和场景级全局特征。
Point Convolution Methods点卷积法。
这些方法倾向于为点云提出有效的卷积算子。
Hua等人[76]提出了一种逐点卷积算子,将相邻点合并到核单元中,然后与核权重进行卷积。如图12(b)所示,
Wang等人提出了一种基于参数连续卷积层的PCCN网络。该网络的核函数参数由MLP来决定,跨越整个连续的向量空间
Thomas等人提出了一种基于核点卷积(KPConv)的核点全卷积网络 Kernel Point Fully Convolutional Network(KP-FCNN)。具体地说,KPConv的卷积权重由到核点的欧几里德距离确定,并且核点的数目不是固定的。将核点的位置转化为为球面空间中最佳覆盖的优化问题。注意,半径邻域用于保持一致的感受野,而网格子采样用于每层,以在不同密度的点云下实现高鲁棒性。
在[211]中,Engelmann等人提供了丰富的消融实验 ablation experiments和可视化结果,以显示感受野对基于聚集的方法性能的影响。他们还提出了一种扩展点卷积(DPC)操作来聚合扩展的相邻特征,而不是K个最近邻。该操作被证明在增加感受野方面非常有效,并且可以很容易地集成到现有的基于聚合的网络中
注 消融实验 笔者第一次见到消融实验(Ablation experiment)这个概念是在论文《Faster R-CNN》中。
消融实验类似于“控制变量法”。
假设在某目标检测系统中,使用了A,B,C,取得了不错的效果,但是这个时候你并不知道这不错的效果是由于A,B,C中哪一个起的作用,于是你保留A,B,移除C进行实验来看一下C在整个系统中所起的作用。
————————————————
版权声明:本文为CSDN博主「房东丢的猫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gaolijing_/article/details/105626733
RNN方法
To capture inherent context features from point clouds, Recurrent Neural Networks (RNN)have also been used for semantic segmentation of point clouds.
基于pointnet的方法,Engelmann等人[213]首先将点块转换为多尺度块和网格块,以获得输入级上下文。然后,将PointNet提取的分块特征依次输入合并单元(CU)或循环合并单元(RCU),以获得输出级上下文。实验结果表明,结合空间上下文对于提高分割性能是非常重要的。
Huang等人[212]提出了一个轻量级局部依赖建模模块,并利用切片池层将无序的点特征集转换为有序的特征向量序列。如图12(c)所示,Ye等人[202]首先提出了一个逐点金字塔池(3P)模块来捕获从粗到细的局部结构,然后利用双向分层RNN进一步获得长距离空间依赖性。然后应用RNN实现端到端学习。然而,当将局部邻域特征与全局结构特征聚合时,这些方法失去了点云丰富的几何特征和密度分布[220]。
为了缓解刚性和静态池操作所带来的问题,赵等人提出了一种动态聚合网络(DARNET),以兼顾全局场景复杂性和局部几何特征。使用自适应接收场和节点权重动态聚合媒体间特征。
Liu等人[221]提出了3DCNN-DQN-RNN,用于大规模点云的有效语义解析。该网络首先使用3D CNN网络学习空间分布和颜色特征,然后使用DQN定位属于特定类别的对象。最后将拼接后的特征向量送入残差RNN中,得到最终的分割结果
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 这篇文章 三维视觉的深度学习的开山之作,之后所有的作品都是以pointnet 为基本https://github.com/anjinglala/ComprehensiveEvaluation1框架来进行搭建并提高的
Pointnet 和pointnet++ 神作 不多说了 斯坦福大学 祁芮中台 或者英文名字查理斯
相关资源
1 将门创投 | 斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用 https://www.bilibili.com/video/BV1As411377S?spm_id_from=333.999.0.0 作者亲自讲解pointnet的设计思想
2 作者主页:https://stanford.edu/~rqi/
3相关ppt文字和文字记录
https://www.cnblogs.com/wangchangshuo/p/13884574.html 点云上的深度学习及其在三维场景理解中的应用(PPT内容整理PointNet)
点云深度学习的3D场景理解 https://www.cnblogs.com/Libo-Master/p/9759130.html
3D数据的表达方式
关于为什么选择点云

前人方法的局限性

点云方法的困难性 重点可以关注这两个方面的解决

关于点云是无序性的,所以改变点云的输入顺序应该不影响其结果
因此解决方案是 选用对称函数,具有置换不变性

单纯的使用max的话可能会导致特征丢失,因此我们考虑把每个点映射到高维空间,然后对高维空间取max

原始结构
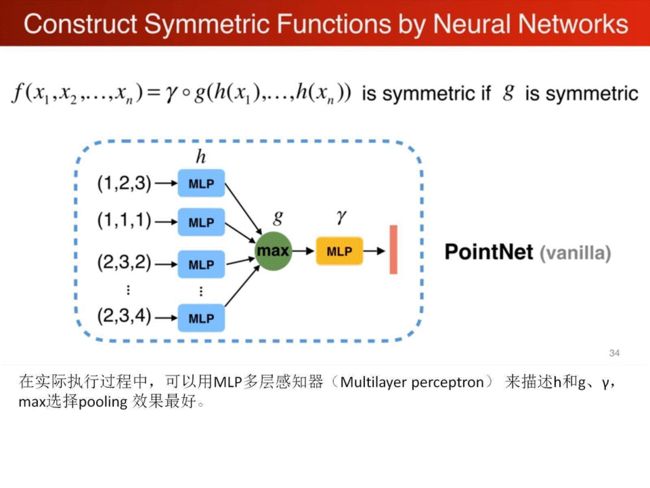
针对点云的旋转不变性

考虑利用变换函数使得网络所有的输入对齐(详见论文 T-Net)


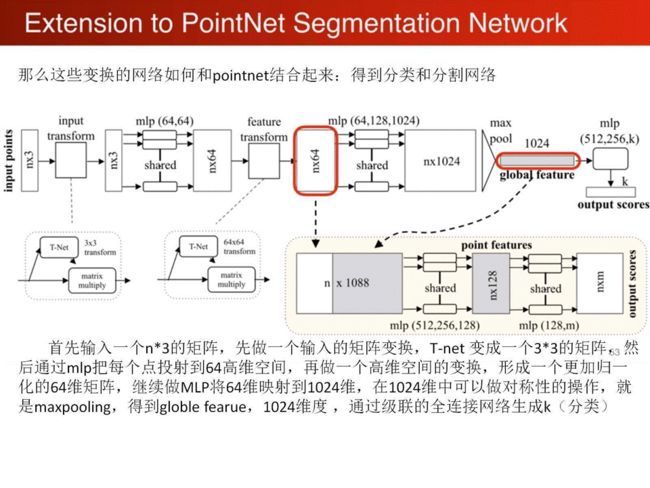

pointnet到pointnet++
Pointnet的局限性

pointnet++ 的思想



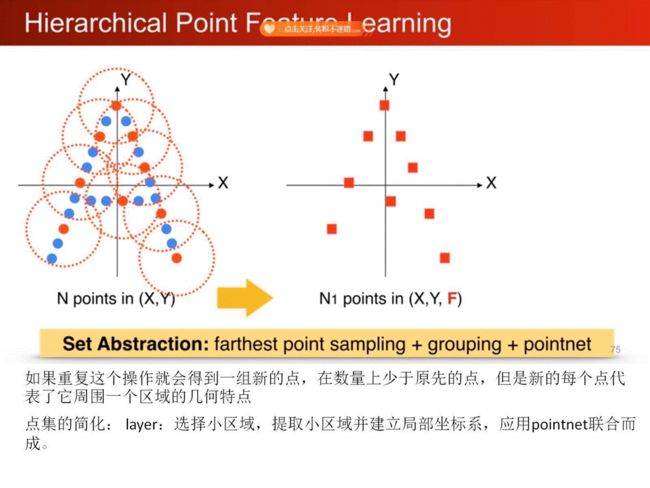
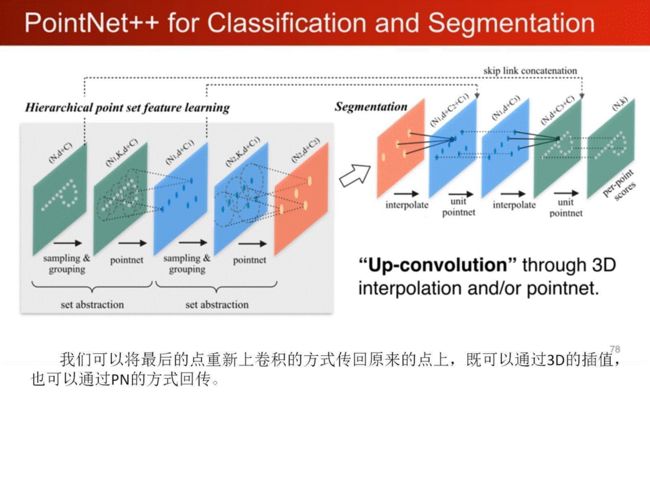
1、pointnet局部特征学习,平移和视角变换的不变性。
2、部分填充数据丢失的鲁棒性。
3、采样率变化的鲁棒性。
4、外形相似的分类鲁棒性。
回到pointnet 论文的学习
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) 以及-Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds (NeurIPS 2019) 牛津大学
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e5LaaYD1-1637327148595)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211115151107471.png)]
首先 介绍一下3D点云的一些方法,
1) projected images:这是一种具有3D效果的2D图像,可以联想生活中一些3D绘画作品,虽然人可以感受到3D的效果,但是本质还是2D,计算机并不能识别其3D信息;
2) voxel grids:这是一种体素化的表达方式,体素是3D中的东西,对应到2D就是像素。在空间中用一个个小方块(体素)来对物体进行填充,便达到了3D的效果;
3) implicit surfaces:隐式曲面,计算机图形学中的概念,用数学函数形式来表达物体的表面形状;
4) mesh:用一系列的点和面将物体表面围起来,来表达3D信息;
5) point clouds:点云,一堆点的集合{(x1,y1,z1), (x2,y2,z2)……},当然每个点除了3个坐标也可能有其它属性,如RGD之类。
点云的很大的应用优势就是,可以实时被传感器测量出来、可以很紧凑的表示一个大规模场景的3D信息、可以非常好的表示物体的3D形状信息,对光照等外界因素并不敏感(因为是主动式的发射反射光信息,2D只是接受其它光源的反射光)。
当然,点云也有其不好处理的一面。点云是不规则的、不均匀的、无序的。虽然有这些缺点,但是其巨大的优点,让研究者们不断去想尽办法,寻找足够好的算法,去更好的处理点云。
点云处理的一些方法,同前面的Survey
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HuyuQB5w-1637327148597)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119163150886.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-frcWEOLx-1637327148599)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119163229613.png)]
首先介绍下 voxel-based方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MiCIQaPE-1637327148600)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119163433014.png)]
利用voxel方法,可以使得点的信息较为完整的保存下来,可以利用cnn等方法进行较好的识别
缺点是占用大量的计算资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aO1FdUvk-1637327148603)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119195045083.png)]
point-based 也是以pointnet为例讲解,pointnet的想法是对每一个点进行fcn网络,然后利用一层一层的提取特征,最后利用max-pooling提取最大特征。pointnet的关键–globalfeature
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2ZpJcJo-1637327148605)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119195410247.png)]
这里指出了voxel-based方法和Point-based的优缺点
显然,voxel-based方法牺牲了效率,增加了准确率 Point-based则相反
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) 大场景点云的分割
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fjaQSGff-1637327148607)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119195736172.png)]
相关工作
Point Convolutions Methods方法
Pointcnn可以对点云进行convulsion同时可以对点云的顺序进行排序diordered–到ordered
Kpconv方法,针对pointnet 的kernel半径改变可能会使网络本身不稳定,KPconv通过mapping方法将点云映射到一个空间,可以实现较为稳定的核来进行学习
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2y08ZXqG-1637327148609)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119200326916.png)]
其他大场景点云的工作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IRhLeLeg-1637327148611)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119200352010.png)]
Motivation目前的方法都是针对小点云块,没有针对大场景的分割效果
研究发现,pointnet在尺度越大效果越差,原因是pointnet只是对所有的点进行FCN,仅仅通过max-pooling损失了很多的特征。pointnet++学习了点的和周围的关系,在分割的效果逐步提升,但是时间复杂度却非常高,一直增大
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HB91U99K-1637327148613)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119200954440.png)]
作者先简单介绍了两篇前人的工作,PointCNN和KPConv,这两篇论文并不是做大场景的,但是它们提出的想法是基础性的,就是自定义卷积,通过自定义的卷积在点云上进行操作,可以提取更好的特征。
在大场景领域,作者也简单提了两篇工作,SPG和FCPN。SPG为整个场景的点云构建了一个超点图,边信息表征了点云内在的关联,然后在graph上进行操作。FCPN是结合了point-based和voxel-based,将无规则的点云,转换为内部有序的数据结构,然后再使用3D卷积进行处理。作者提到之前做大场景的工作,处理起来都非常耗时,因此RandLA-Net工作motivation便有了。
那现有的方法,比如pointnet和pointnet++能直接迁移到大场景领域吗?作者做了相关实验,首先pointnet是直接用max pooling来取得全局特征,局部特征的提取是缺失的。随着切块的块越来越大,直接max pooling,必然会损失很多信息,因此pointnet的性能会越来越低。那结合了局部特征的pointnet++呢?通过实验,我们发现随着块的变大,性能也在变好。然而耗时也越来越严重,因为pointnet++中使用的点集的降采样算法,是和点数的二次方成正比的,块越大,点数越多,速度越慢。
作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
那么大场景点云语义分割领域的难点在哪?作者提了三点,首先是整体的点云相比于一个小块的点云的结构要复杂很多;其次是点数的增多势必会带来GPU显存的上升;最后是传感器采集到的点云数是非固定的,之前都是切块后再采固定数量的点。
作者希望能找到一个符合以下三点的大场景处理方法:1)不用切块,直接全局输入;2)计算复杂度和显存占用要低;3)还要保证精度和能够自适应输入点数。作者希望能找到一个符合以下三点的大场景处理方法:1)不用切块,直接全局输入;2)计算复杂度和显存占用要低;3)还要保证精度和能够自适应输入点数。
对于大场景的点云,如何直接处理呢?一个核心的步骤就是降采样。作者认为我们需要一个更有效的降采样算法,来保留点云的key points。同时还希望能够有一种更好的局部特征提取和聚合的算法来学到局部特征。
作者先对现有的点云降采样技术做了总结,大范围可以分为两类:Heuristic Sampling(启发式的)、Learning-based Sampling(可学习的)。
对于启发式的降采样:
Farthest Point Sampling(FPS):这是一种在点云领域被广泛使用的降采样方法,如PointNet系列。每次采样都去离采上一个点最远的点,迭代进行,这样可以把一些边边角角的点都能找到,但是算法计算复杂度O(N^2);
Inverse Density Importance Sampling (IDIS):先对每个点的密度进行排序,然后密集的部分多采样,稀疏的部分尽可能都保留。然而这种算法会容易受到噪声的影响,计算复杂度O(N);
Random Sampling (RS):随机采样,计算复杂度为O(1),与输入点数无关,当然可能会丢掉一些重要的点
对于可学习的降采样:
Generator-based Sampling (GS):算法通过学习来生成一个点云子集来实现降采样。这是很新颖的方法,然而这种方法可能比FPS方法的复杂度更高;
Continuous Relaxation based Sampling (CRS):通过学习一个矩阵,类似与实现一个全连接网络,然后和输入点云相乘得到输出的低维点云空间。然而当输入点数非常大的时候,矩阵需要的显存也将非常大;
Policy Gradient based Sampling (PGS):使用一个马尔科夫决策来对每一个点进行决策,决定其是否被保留。当输入点数很多的时候,其决策过程非常缓慢,搜索空间非常大,而且很容易不收敛。
通过以上的对比,最后作者认为也许随机采样才是最适合大场景的点云分割任务的。然而,随机采样很容易去丢掉那些重要的点,我们该如何解决这个问题呢?作者提出了Local Feature Aggregation。这个Local Feature Aggregation主要包括三个子模块,分别是LocSE、Attentive Pooling、Dilated Residual Block。 作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-spN2qqKA-1637327148616)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119202518757.png)]
仔细看这个这个图,分为三个模块
LocSE 采用 k-nearst 方法求取局部的feature ,大多数的方法是把x,y,z坐标直接作为通道输入网络。
但受到论文 RSCNN Relation-Shape CNN for Point Cloud Analysis的启发,需要知道点云的位置相对关系,计算了相对位置与欧氏距离作为通道加入encoder[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-niB6SruG-1637327148619)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119204228931.png)]
特征融合 attentive pooling 引入注意力机制Attention
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2bgSLBIE-1637327148623)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119204535259.png)]
为了避免采样影响效果,引入感受野机制,更好的融合局部信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bN4POdTd-1637327148625)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211119204559956.png)]
LocSE,即Local Spatial Encoding
该模块希望从输入点云里得到一个局部空间特征。步骤是先对于每一个点进行K近邻,找到它的邻域点集;然后将中心点的坐标、邻域点的坐标、邻域点和中心点的相对坐标和邻域点和中心点的欧式距离连在一起;再过一个MLP,和邻域点的特征在连在一起,得到最终输出。
Attentive pooling
将上面提取到的特征聚合在一起,PointNet系列一般都是直接一个Max Pooling,实现特征聚合。作者认为Max Pooling有些粗暴,容易丢掉一些重要的信息。作者使用Attention机制,在SeNet工作中提到过,学习一个MASK,来作为每个特征的权值,然后加权,再过一个MLP,实现聚合。
Dilated Residual Block
随机降采样不可避免会丢掉一些重要的点,如何解决这个问题,作者认为如果每个点的感受野足够大,其能够更好地聚合局部的特征,而且当这种感受野足够大时,即便有些点的特征被随机的丢掉了,但整个点云的大部分信息还是能够被有效地保留下来。因此我们将多个LocSE和Attentive Pooling模块连在一起,组成一个大的Dilated Residual Block。这样的话,输入点云通过不断的聚合,便增大了保留下点的视野。
基于上面的方法,作者设计了一个沙漏网络的结构,即点数先降低,再增加。每一层局部特征聚合和随机采样交替进行,点数下来了,每个点的视野也上去了。
通过实验,作者发现随机采样方法,无论是从速度还是显存,都是对比最优的,整体方法的效率,在大场景领域对比也是速度最快。再看精度,在Semantic3D、SemanticKITTI和S3DIS上,作者的方法也取得的非常好的效果。 作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
MLP多层感知机
3Blue1Brown
https://www.bilibili.com/video/BV1bx411M7Zx?spm_id_from=333.999.0.0 一定要多看几遍
一、MLP神经网络的结构和原理
理解神经网络主要包括两大内容,一是神经网络的结构,其次则是神经网络的训练和学习,其就好比我们的大脑结构是怎么构成的,而基于该组成我们又是怎样去学习和识别不同事物的,这次楼主主要讲解第一部分,而训练和学习则放到后续更新中。
神经网络其实是对生物神经元的模拟和简化,生物神经元由树突、细胞体、轴突等部分组成。树突是细胞体的输入端,其接受四周的神经冲动;轴突是细胞体的输出端,其发挥传递神经冲动给其他神经元的作用,生物神经元具有兴奋和抑制两种状态,当接受的刺激高于一定阈值时,则会进入兴奋状态并将神经冲动由轴突传出,反之则没有神经冲动。
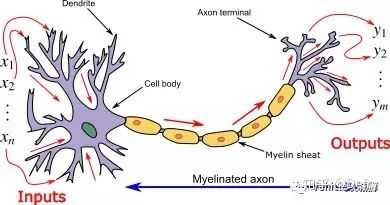
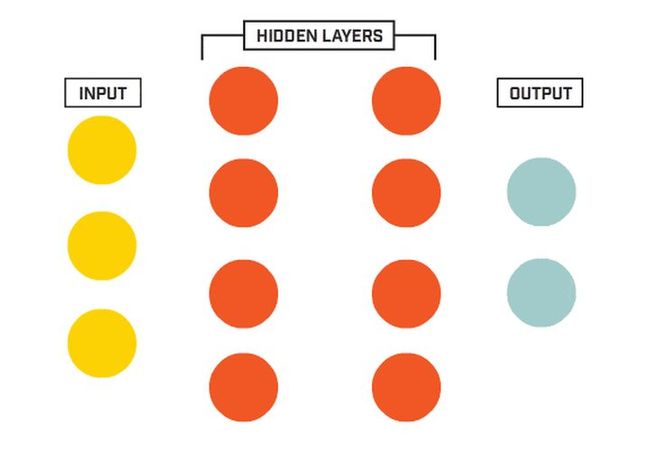
我们基于生物神经元模型可得到多层感知器MLP的基本结构,最典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
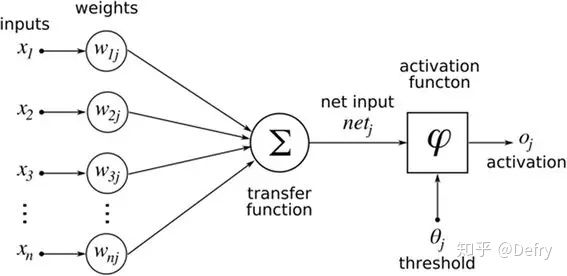
由此可知,神经网络主要有三个基本要素:权重、偏置和激活函数
权重:神经元之间的连接强度由权重表示,权重的大小表示可能性的大小
偏置:偏置的设置是为了正确分类样本,是模型中一个重要的参数,即保证通过输入算出的输出值不能随便激活。
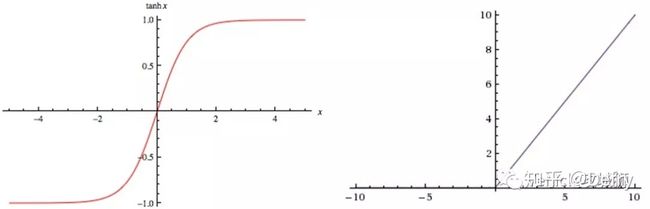
激活函数:起非线性映射的作用,其可将神经元的输出幅度限制在一定范围内,一般限制在(-11)或(01)之间。最常用的激活函数是Sigmoid函数,其可将(-∞,+∞)的数映射到(0~1)的范围内。
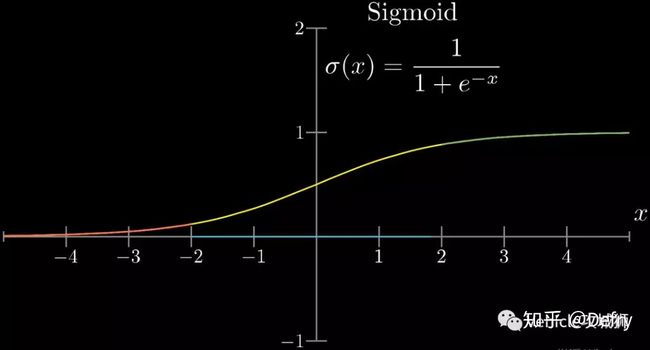
激活函数还有tanh和ReLU等函数,tanh是Sigmoid函数的变形,tanh的均值是0,在实际应用中有比Sigmoid更好的效果;ReLU是近来比较流行的激活函数,当输入信号小于0时,输出为0;当输入信号大于0时,输出等于输入;具体采用哪种激活函数需视具体情况定。
从上面可知下层单个神经元的值与上层所有输入之间的关系可通过如下方式表示,其它以此类推。
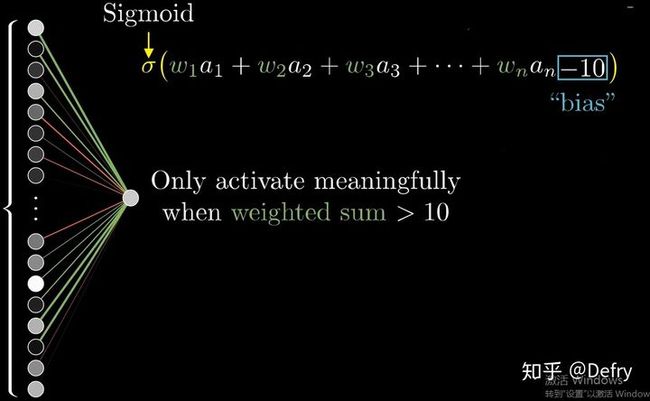
MLP的最经典例子就是数字识别,即我们随便给出一张上面写有数字的图片并作为输入,由它最终给出图片上的数字到底是几。
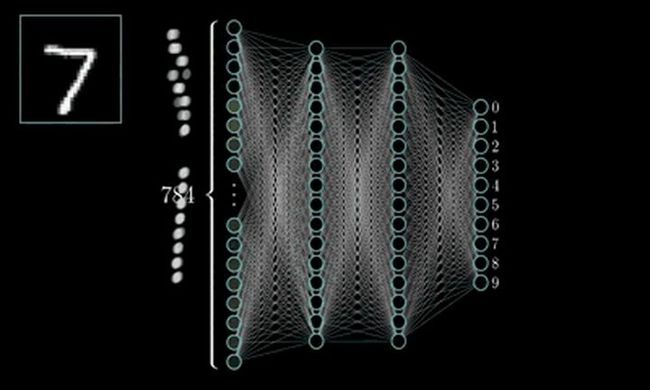
对于一张写有数字的图片,我们可将其分解为由28*28=784个像素点构成,每个像素点的值在(0~1)之间,其表示灰度值,值越大该像素点则越亮,越低则越暗,以此表达图片上的数字并将这786个像素点作为神经网络的输入。
而输出则由十个神经元构成,分别表示(09)这十个数字,这十个神经元的值也是在(01)之间,也表示灰度值,但神经元值越大表示从输入经判断后是该数字的可能性越大。
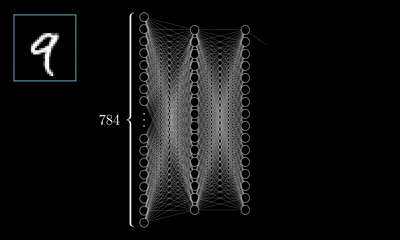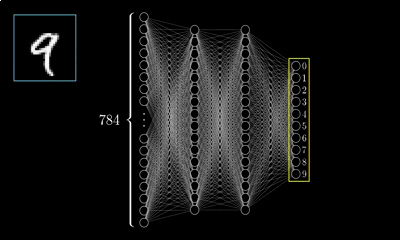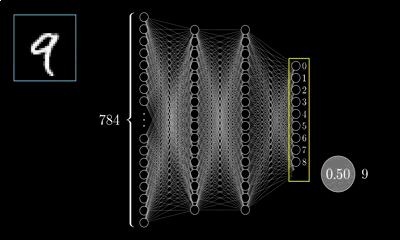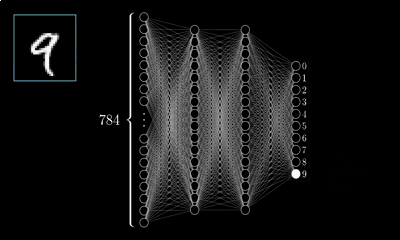
隐层的层数和神经元的选择需根据具体情况选择,此例选择两层隐层,每层16个神经元。那么根据上面的叙述,根据权重、偏置的个数此神经网络将会有13002个参数需要去调节,而如何调整这些参数,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yrx0Cagl-1637327148642)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20211116100534588.png)]
通过楼主上面的叙述,该图像识别问题最终可通过线性方程的方式表示出来,从而来描述本篇通过MLP神经网络进行数字识别的案例,并通过建立的问题描述模型来编程实现。
激活函数:起非线性映射的作用,其可将神经元的输出幅度限制在一定范围内,一般限制在(-11)或(01)之间。最常用的激活函数是Sigmoid函数,其可将(-∞,+∞)的数映射到(0~1)的范围内。
[外链图片转存中…(img-ZehKldII-1637327148631)]
激活函数还有tanh和ReLU等函数,tanh是Sigmoid函数的变形,tanh的均值是0,在实际应用中有比Sigmoid更好的效果;ReLU是近来比较流行的激活函数,当输入信号小于0时,输出为0;当输入信号大于0时,输出等于输入;具体采用哪种激活函数需视具体情况定。
[外链图片转存中…(img-GfIZ55FB-1637327148633)]
从上面可知下层单个神经元的值与上层所有输入之间的关系可通过如下方式表示,其它以此类推。
[外链图片转存中…(img-LQoRKNNr-1637327148637)]
MLP的最经典例子就是数字识别,即我们随便给出一张上面写有数字的图片并作为输入,由它最终给出图片上的数字到底是几。
[外链图片转存中…(img-qLuUDKfT-1637327148639)]
对于一张写有数字的图片,我们可将其分解为由28*28=784个像素点构成,每个像素点的值在(0~1)之间,其表示灰度值,值越大该像素点则越亮,越低则越暗,以此表达图片上的数字并将这786个像素点作为神经网络的输入。
而输出则由十个神经元构成,分别表示(09)这十个数字,这十个神经元的值也是在(01)之间,也表示灰度值,但神经元值越大表示从输入经判断后是该数字的可能性越大。
[外链图片转存中…(img-ceGnpB5X-1637327148640)]
隐层的层数和神经元的选择需根据具体情况选择,此例选择两层隐层,每层16个神经元。那么根据上面的叙述,根据权重、偏置的个数此神经网络将会有13002个参数需要去调节,而如何调整这些参数,
[外链图片转存中…(img-yrx0Cagl-1637327148642)]
通过楼主上面的叙述,该图像识别问题最终可通过线性方程的方式表示出来,从而来描述本篇通过MLP神经网络进行数字识别的案例,并通过建立的问题描述模型来编程实现。