在Ubuntu18.04系统中非root服务器用户如何跑通PointRCNN(禁止转载)
上周刚刚复现了PointRCNN,从数据集的准备,到代码的下载,再到环境的配置,其中种种波折,不胜其数。参照了很多大神的帖子,现在终于顺利跑通代码,在此记录一下,以备自己回顾,也希望能给大家一点帮助。
数据集的准备
这一部分参照KITTI数据集下载(百度云)、Linux zip与tar分卷压缩及合并解压和点云目标检测(一)——PointRcnn复现。
Step 1 下载KITTI数据集
根据KITTI数据集下载(百度云)中的百度云链接,下载KITTI数据集。下载得到的文件如下图:
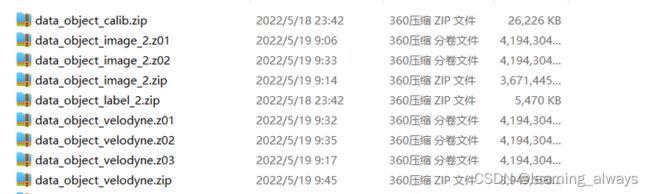
也可以从github作者给的链接中再下载一个train_planes.zip的文件。
Step2 将下载后的文件解压
参照Linux zip与tar分卷压缩及合并解压,将data_objet_image_2前缀的3个压缩文件放一个文件夹里,在终端中:
# 将上述三个压缩包合并为一个压缩文件
zip subimgs.zip -s=0 --out single.zip
# 解压single.zip
unzip -d ./single.zip
对于data_objet_velodyne前缀的4个压缩文件也进行类似的操作。
其他没有子压缩包的压缩文件直接解压。
Step3 组织数据集结构
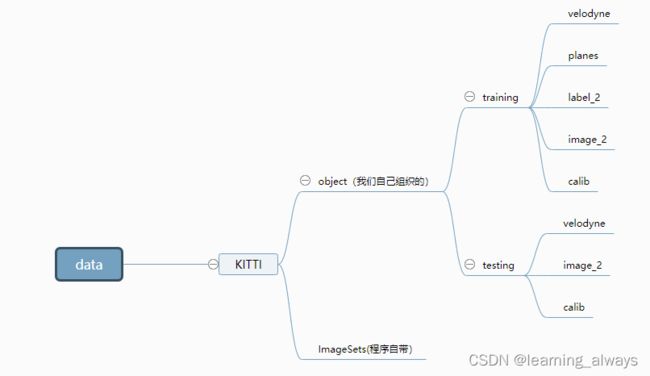
参照点云目标检测(一)——PointRcnn复现 组织数据结构,最终得到的数据结构如下图所示:
程序的下载
参照点云目标检测(一)——PointRcnn复现,用git clone 在linux终端下载程序,直接在github里下载得到的zip文件不全,在window终端中下载的版本不一样,不适用linux。
git clone --recursive https://github.com/sshaoshuai/PointRCNN.git
环境的配置
这个是重头戏,PointRCNN的环境配置非常苛刻。在服务器自己的账号中最好是要配置自己的cuda环境,因为root账号的cuda版本一般较高,直接配置往往会失败。经多次试验后发现 cuda10.1+python3.6.2+ pytorch 1.4.0+torchvision0.5.0的配置是ok的。
Step 1 配置cuda 10.1
去官网下载cuda10.1。一定要下载下图所示的cuda版本cuda_10.1.243.418.87.00_linux.run。相较于其他的cuda10.1的cuda版本,这个版本可以自定义路径。另一个版本试过,失败。
cudnn的版本可以参照下图的,到官网选个合适的应该就行。下载的时候不用注册,可以直接复制下载链接,用wget或者迅雷下载。

参照非root用户在服务器上安装CUDA10.1和对应cudnn到指定目录_sdkjkfk的博客-程序员秘密进行安装。
Step 2 配置pytorch 环境
(1)为了更快地下载包,先添加清华源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --set show_channel_urls yes
(2)创建并激活虚拟环境。
conda activate -n py36 python=3.6.2
source activate py36
(3)安装pytorch
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.1
(4)安装包
conda install easydict
conda install tqdm
conda install tensorboardX
conda install fire
conda install numba
conda install pyyaml
conda install scikit-image
conda install shapely
(5)通过代码中的程序安装包
cd pointRCNN
sh build_and_install.sh
到这里基本上环境就可以配置成功了。如果有失败的话,可以考虑步骤(4)中安装包的时候用pip,或者把步骤(4)时将清华源删去,恢复默认设置。
训练阶段
该部分主要参照点云目标检测(一)——PointRcnn复现。
Step 1 数据预处理
cd pointRCNN/tools #进入程序目录
python generate_gt_database.py --class_name 'Car' --split train
Step 2 第一阶段的训练(rpn)
多GPU训练
CUDA_VISIBLE_DEVICES=0,1 python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 16 --train_mode rpn --epochs 200 --mgpus
Step3 第二阶段的训练(RCNNNet)
多GPU训练
CUDA_VISIBLE_DEVICES=0,1 python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 4 --train_mode rcnn --epochs 70 --ckpt_save_interval 2 --rpn_ckpt ../output/rpn/default/ckpt/checkpoint_epoch_200.pth --mgpus
该部分在运行代码时会出现问题:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_SUPPORTED. This error may appear if you passed in a non-contiguous input.
这是因为输入不连续的问题,参照https://github.com/sshaoshuai/PointRCNN/issues/151,对torch的代码进行修改。
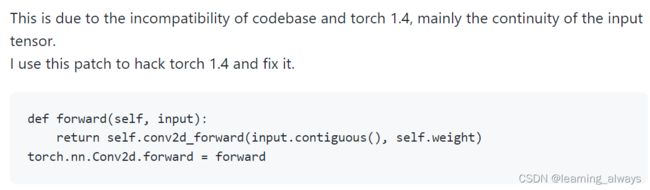
然后代码就可以正常运行了。
以上就是跑通PointRCNN代码的全过程,这一套流程在不同的服务器上都试过,都可以成功跑通代码。如果有实践的过程中,有其他bug出现,欢迎在评论区留言。