变种 背包问题_深度强化学习-求解组合优化问题
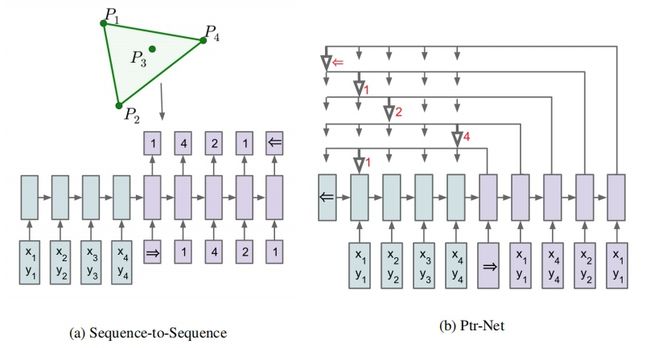
1 Pointer Networks
paper
github
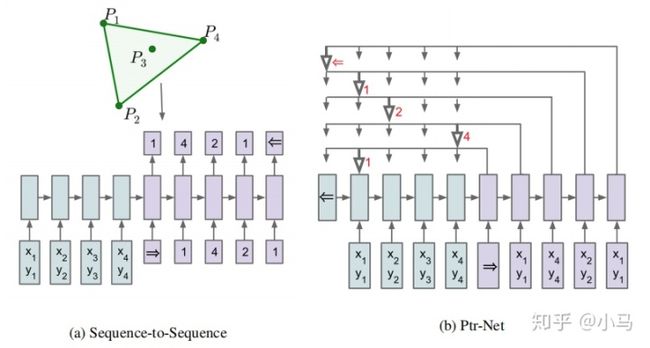
Vinyals的这篇论文提出了PointerNetwork(PN),求解了一些经典的组合优化问题,比如旅行商问题(TSP)和背包问题(Knapsack problem)。他们使用注意力机制计算Softmax概率值,将其当做指针(Pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练。这篇论文是后面几篇论文的基础
在Seq2Seq的结构中,原来的Attention机制为:
在PointerNetwork中,Attention机制变为:
2 Neural Combinatorial Optimization with Reinforcement Learning
paper
github
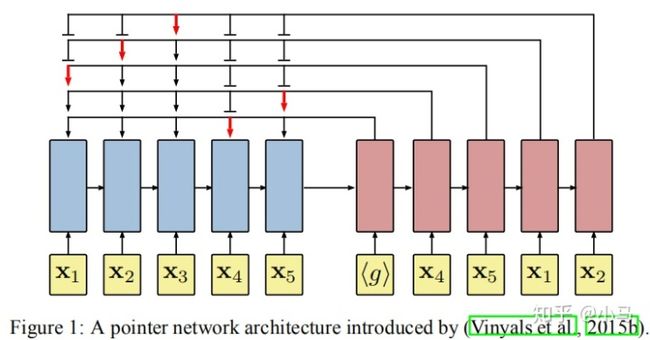
PointerNetwork是基于参考算法提供的标签数据进行的有监督训练,所以算法的性能不会优于参考算法。高质量的标签难以获得。当节点n>50后,效果变差。针对于有监督训练中训练数据获取困难、精度不足的问题,Bello等使用Actor Critc强化学习算法对PN进行训练,在节点长度n=100的TSP问题上获得了近似最优解
路径长度为:
Actor-Critic算法:
- Policy gradient:
- Critic:
Pointing mechanism:
加入了两个trick:
- Softmax temperature:
- Logit clipping:
3 Reinforcement Learning for Solving the Vehicle Routing Problem
paper
github
PointerNetwork结构存在的问题在于,当输入序列中的动态元素发生变化时,要对整个Encoder进行更新才能进行下一个节点的预测,增加了计算量。Nazari等使用一个Embedding Layer对PN的Encoder部分进行了替换,这样一来,当输入序列中的动态元素发生变化时,不必对Encoder的RNN部分进行完全更新
Embedding Layer:直接把输入映射为一个D维的向量空间,对encoder的RNN进行简化,不同时刻的输入共享同一个input结构

Attention Layer with Glimpse:
训练算法的伪代码如下:

A3C算法的伪代码:

4 Learning Combinatorial Optimization Algorithms over Graphs
paper
github
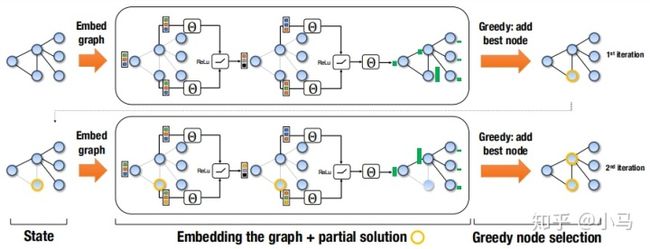
该算法更适合解决基于图论的组合优化问题,上图所示为求解Minimum Vertex Cover(最小顶点覆盖问题)的过程,整体上采用Structure2Vec+Q learning的结构
Graph embedding vector:
Q function:
Q target:
Minimize squared loss:
5 Attention, Learn to Solve Routing Problems!
paper
github
这一篇基于Transformer中Self Attention(MHA+FF)建立了一个复杂的Encoder,使用Rollout强化学习算法对模型训练,求解了TSP和VRP及其变种OP、PCTSP和SPCTSP
MHA:

Embedding:
Dot-product Compatibility:
Attention weights:
Combination vector:
Multi-head attention (MHA) layer:
Batch normalization:
Feed-forward (FF) layer:
Encoder:
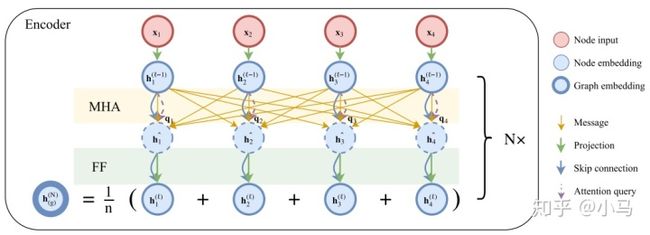
Node embedings:
MHA sublayer:M = 8 heads
Batch normalization (BN):
FF sublayer:512 dimensions and ReLU activation
Graph embeddings:
Decoder:
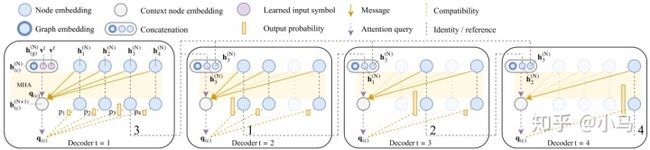
Context embedding:
MHA to New Context embedding like Glimpse:
Single query:
MHA without Skip,BN,FF Compatibility clipping:
Softmax log-probability:
Finally to Model:
Rollout训练算法:

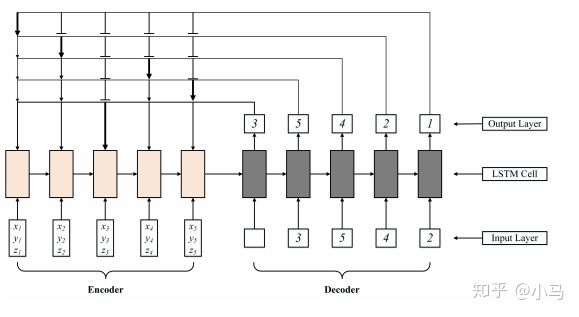
6 Solving a New 3D Bin Packing Problem with Deep Reinforcement LearningMethod
paper
问题建模:
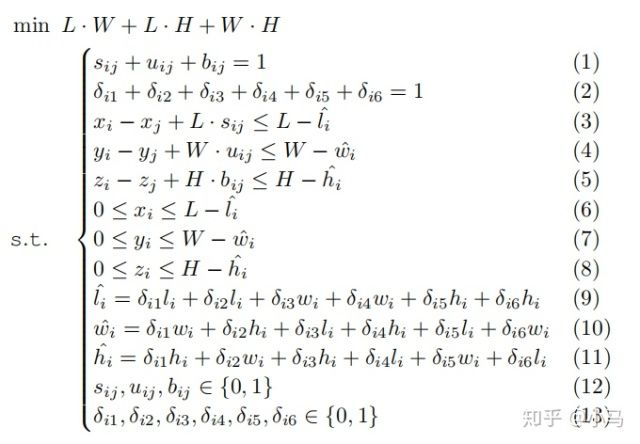
模型:
7 An Efficient Graph Convolutional Network Technique for the Travelling Salesman Problem
paper
github
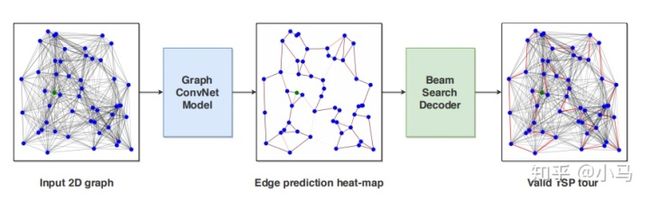
输入为一个邻接矩阵,后经过图卷积神经网络得到邻接矩阵的概率heat-map,最后使用beam search算法对路径进行搜索。算法是基于有监督训练的
Input layer:
Node input feature:
The edge input feature:
GCN:
Node feature vector:
Edge feature vector:
MLP classififier:
参考文献:
[1] Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer Networks, 1–9. Retrieved from http://arxiv.org/abs/1506.03134
[2] MohammadReza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takac. Reinforcement learning for solving the vehicle routing problem. In Advances in Neural Information Processing Systems, pp. 9860–9870, 2018.
[3] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In Advances in Neural Information Processing Systems, pp. 2692–2700, 2015.
[4] Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning. arXiv preprint arXiv:1611.09940, 2016.
[5] Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning, pages 1928–1937, 2016.
[6] Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4):229–256, 1992.