pyecharts导演人物关系图
目录
- 前言
- 一、pyecharts是什么?
- 二、操作步骤
-
- 1.导入包
- 2.数据预处理
- 3.生成json数据信息
- 4.生成json
- 5.生成关系图
- 数据集
前言
帮别人做了一个小作业,需要根据豆瓣TOP250的电影信息,提取需要人物关联关系,并生成节点链接网格图绘制需要的json文件,用关系图描述导演和演员的联系。
其中,节点大小编码映射该节点与其他人物链接关系次数
数据集样式:
TOP250电影数据包含字段:片名、上映年份、评分、评价人数、导演、编剧、主演、类型、国家/地区、时长等

一、pyecharts是什么?
Echarts是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而python是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上了数据可视化时,pyecharts诞生了。
pyecharts官网:https://pyecharts.org/#/zh-cn/intro
安装:pip install pyecharts
二、操作步骤
所有电影数据全部绘制出来,可能数据量比较大,先在原表格筛选出中国的数据,所以这里先绘制“中国”的电影导演人物关联关系。

1.导入包
import pandas as pd
import json
import random
from pyecharts import options as opts
from pyecharts.charts import Graph
2.数据预处理
1、如《霸王别姬》主演数据信息:张国荣 / 张丰毅 / 巩俐 / 葛优 / 英达 / 蒋雯丽 / 吴大维 / 吕齐 / 雷汉 / 尹治 / 马明威 / 费振翔 / 智一桐 / 李春 / 赵海龙 / 李丹 / 童弟 / 沈慧芬 / 黄斐 / 徐杰
‘/’前后都带了空格,需要把前后空格替换
2、以‘/’为分隔符,把多个导演的分隔开,设置成“第一导演”“第二导演”…
3、同一主演可能出演了另一部电影,所以需要合并去重
4、最后生成一个新的表格,一个导演对应所有的主演

代码如下:
df['导演'] = df['导演'].str.replace(' / ', '/')
df['主演'] = df['主演'].str.replace(' / ', '/')
df=df[['导演','主演']]
three_dy=pd.DataFrame((x.split('/') for x in df['导演']),index=df.index,columns=['第一导演','第二导演','第三导演'])
new=pd.merge(df,three_dy,left_index=True,right_index=True)
new=new.drop(columns = ['导演'])
dy1=new[['第一导演','主演']]
dy1.rename(columns={'第一导演':'导演'}, inplace = True)
dy2=new[['第二导演','主演']]
dy2.rename(columns={'第二导演':'导演'}, inplace = True)
dy2=dy2.dropna()
dy3=new[['第三导演','主演']]
dy3.rename(columns={'第三导演':'导演'}, inplace = True)
dy3=dy3.dropna()
one_dy=pd.concat([dy1,dy2],axis=0,join='outer')
one_dy=pd.concat([one_dy,dy3],axis=0,join='outer')
#重复出现导演去重
dy=one_dy['导演'].drop_duplicates().values.tolist()
b=[]
for i in dy:
temp=one_dy[one_dy['导演']==i]
x=temp['主演'].tolist()
if len(x)>=2:
a=''
a+=x[0]
for j in range(1,len(x)):
a+='/'
a+=x[j]
else:
a=x[0]
b.append(a)
c={"导演" : dy,
"主演" : b}
data=pd.DataFrame(c)
data.to_csv('导演与主演.csv',index=0,encoding='utf-8')
3.生成json数据信息
查阅了很多资料,发现生成json主要有两种办法
第一种是根据层层关系来写入,每一行都是一个关系,作为一条边,源节点是数据节点,目的节点是系统节点,对应JSON文件中的edges中的每个元素。通过遍历文件,建立节点、边的信息,形成一个大的JSON文件。参考 使用pyecharts绘制系统依赖关系图
第二种是通过建立csv表格,将一个节点的全部信息列出,通过python进行转化成json。参考 如何将csv格式文件转换为Json格式文件?
关系图的josn包含节点信息和边信息,自我感觉第二种方法更简单, 不需要理清太多层的逻辑关系,所以对于节点和边,我都生成了两个表格,便于后面一起转成json格式。
生成数据表格代码:
边数据:
dy=df['导演']
zy=df['主演']
listdy=[]
listzy=[]
for i in range(len(zy)):
tempzy=zy[i].split('/')
tempzy=list(set(tempzy))
tempdy = [dy[i]]*len(tempzy)
listzy+=tempzy
listdy+=tempdy
a={
'导演':listdy,
'主演':listzy
}
a=pd.DataFrame(a)
data=pd.DataFrame()
for i in range(len(dy)-1):
temp1 = a[a['导演'] == dy[i]]
for j in range(i+1,len(dy)):
temp2 = a[a['导演'] == dy[j]]
result = pd.merge(temp1, temp2, on='主演')
data = pd.concat([data, result], axis=0, join='outer')
data.rename(columns={'导演_x':'sourceID', '主演':'value','导演_y':'targetID'}, inplace = True)
data.to_csv('导演与主演对应关系.csv',index=0,encoding='utf-8')
节点数据:
def randomcolor_func():# 生成随机颜色
color_char = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F']
color_code = ""
for i in range(6):
color_code += color_char[random.randint(0, 14)] # randint包括前后节点0和14
return "#" + color_code
list_color=[]
list_label=[]
list_id=[]
list_size=[]
list_value=[]
for i in range(len(df1)):
color = randomcolor_func()
list_color.append(color)
list_label=df1['导演'].values.tolist()
list_id=df1['导演'].values.tolist()
value_count=df2['sourceID'].value_counts()#默认降序
for i in list_id:
if i in value_count.index:
list_value.append(value_count[i])
list_size.append((value_count[i]+10))#控制节点大小
else:
list_value.append(0)
list_size.append(10)
c={
"id": list_id,
"name": list_label,
"size": list_size,
"value":list_value,
"color":list_color,
}
data=pd.DataFrame(c)
data.to_csv('json节点数据内容.csv',index=0,encoding='utf-8')
4.生成json
读取两个表格,转化为json
#读取表格,将表格内容转化为json
fo = open("json节点数据内容.csv", "r", encoding='utf-8') # 打开csv文件
fo2 = open("导演与主演对应关系.csv", "r", encoding='utf-8')
nodes = []
edges=[]
for line in fo:
line = line.replace("\n", "") # 将换行换成空
nodes.append(line.split(",")) # 以,为分隔符
for line in fo2:
line = line.replace("\n", "")
edges.append(line.split(","))
fo.close() # 关闭文件流
fo2.close()
# 将Python数据类型转换成json格式,编码过程
fw = open("director_relationship.json", "w",encoding='utf-8')
for i in range(1, len(nodes)): # 遍历文件的每一行内容,除了列名
nodes[i] = dict(zip(nodes[0], nodes[i])) # nodes[0]为列名,nodes[i]为value,zip()是一个内置函数,将两个长度相同的列表组合成一个关系对
nodes=nodes[1:]
for i in range(1, len(edges)):
edges[i] = dict(zip(edges[0], edges[i]))
edges=edges[1:]
a={
'nodes':nodes,
'edges':edges,
}
json.dump(a, fw, sort_keys=False, indent=4,ensure_ascii=False)# indent参数用语增加数据缩进,使文件更具有可读性
fw.close()
生成的json如图所示:


5.生成关系图
- 关系图属性官方文档链接
with open("director_relationship.json", 'r', encoding='utf-8') as f:
data_local = f.read()
data = json.loads(data_local)
#导入节点
nodes = [
{
"id": node["id"],
"name": node["name"],
"symbolSize": node["size"],
"values": node["value"],
"itemStyle": {"normal": {"color": node["color"]}}
}
for node in data["nodes"]
]
#导入边
edges = [
{
"source": edge["sourceID"],
"target": edge["targetID"],
"value": edge["value"],
}
for edge in data["edges"]
]
#配置关系图属性
(
Graph(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add(
"",
nodes=nodes,
links=edges,
# categories=categories,
layout="circular",
is_rotate_label=True,
linestyle_opts=opts.LineStyleOpts(color="source", curve=0.3),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国电影导演关系图"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="2%", pos_top="20%"),
)
.render("中国电影导演关系图.html")
)
生成的html:(每次颜色都是随机生成)
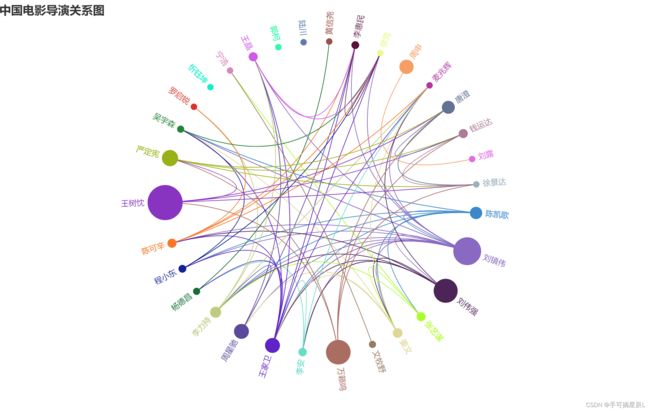
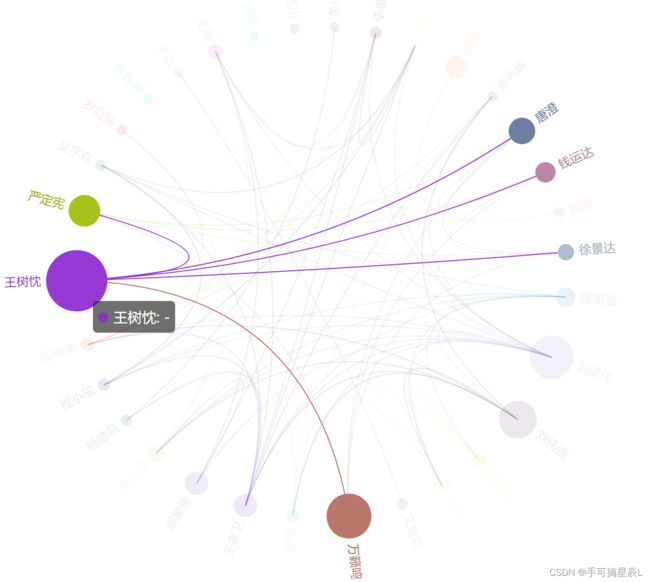
节点信息包含对应关系导演
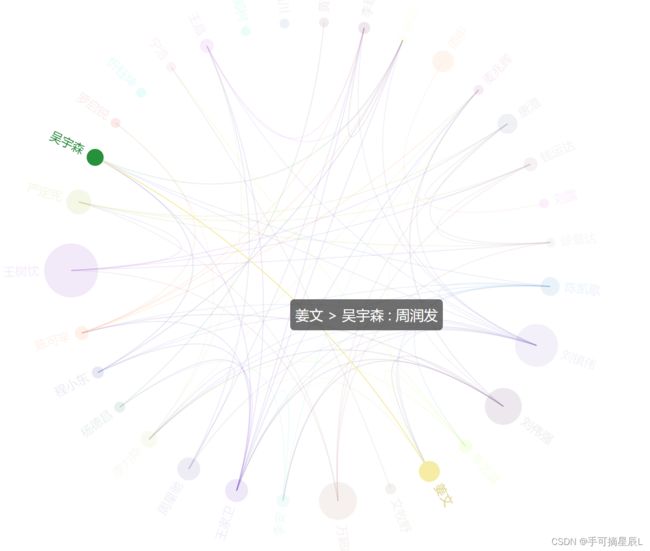
边信息包含链接演员
当把数据改成TOP250表格后,非常杂乱(不堪入目~)
数据集
完整代码+数据百度网盘链接
以此作为本次学习的总结,希望也能帮到正在学习的你~
有问题欢迎在评论区留言讨论
