遥感CNN图像分类
个人博客
hehehehe.160219.xyz/
摘要
使用Landset 8波段数据,CNN模型进行遥感地物分类
1、简介
CNN模型在图像分类中的应用比较广泛,但是遥感领域的的分类对应深度学习中的图像分割,因为它是将一张图片中不同类型的地物区分开,而不是将一个图片归为一个类别。并且,遥感中深度学习的模型虽然应用也比较多,但是可用代码较少,现有代码也存在无法直接使用,代码注释较少,理解困难,代码较多,对新手来说理解困难。因此本文基于一个现有代码进行修改适配,详细讲解过程,模型简单易于理解整个深度学习的全流程。
2、数据准备
2.1 学习区
学区为英国南安普顿附近的一个森林公园加一小片城市
2.2 地物划分
| category | value |
|---|---|
| Forest | 0 |
| Water | 1 |
| Gress | 2 |
| Ground | 3 |
| Building | 4 |
| Road | 5 |
2.3 工作流程
与遥感其他的监督分类方法一样,需要设计地物类别,选择样本,训练模型,最后输出训练结果。

CNN的模型则是使用,李亚飞的《基于卷积神经网络的遥感图像分类研究》这篇论文设计结构。这是一个由Alex Net改造来的模型。
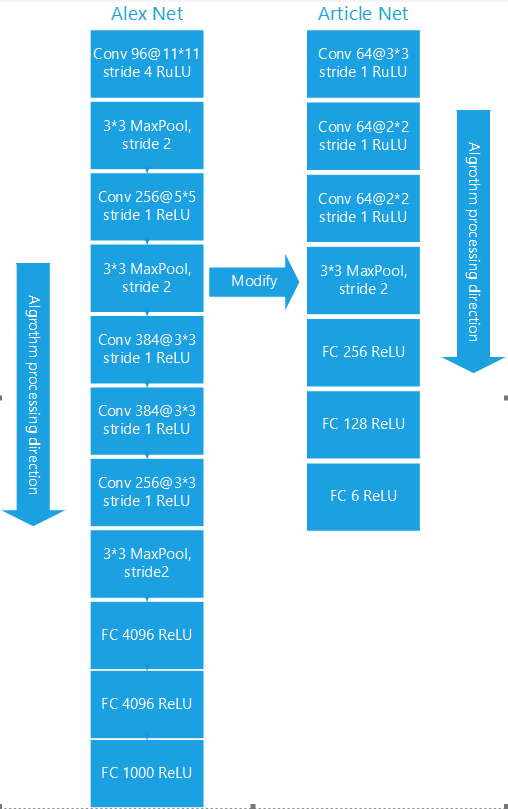
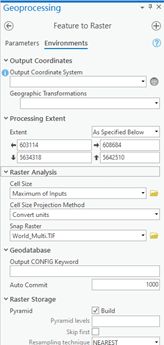
3、训练数据生成
使用Arcgis pro制作数据集并保存为shp,在转为raster,通过extent设置输出栅格分辨率,使其与分类图像一致,为new_class
输出文件需指定tif后缀
4、数据预处理
现在我们有两个文件,一个待分类的tif和ROI的tif。需要将两个文件读入为numpy格式才能处理。
import os, math, random, glob, time
random.seed(2)
import numpy as np
from pyrsgis import raster
from pyrsgis.ml import imageChipsFromFile
# 设置工作路径
output_directory = r"F:\cnn"
os.chdir(output_directory)
feature_file = r"F:\img_class\example.tif"
label_file = r"F:\img_class\new_class.tif"
# 读取文件并按指定大小切片
features = imageChipsFromFile(feature_file, x_size=3, y_size=3)
# 读取标签文件并reshape
ds, labels = raster.read(label_file)
labels = labels.flatten()
# 保存两个np数组
np.save('CNN_3by3_features_ex.npy', features)
np.save('CNN_3by3_new_labels.npy', labels)
5、训练模型
本代码使用tensorflow框架进行训练
# 读取两个文件
features = np.load('CNN_3by3_features.npy')
labels = np.load('CNN_3by3_new_labels.npy')
# 将训练数据feature和训练样本lables中的类别与值一一对应
forest_features = features[labels==0]
forest_labels = labels[labels==0]
water_features = features[labels==1]
water_labels = labels[labels==1]
...
# 由于CNN模型对数据数量较为敏感,因此需要将数据量大的数据减少为与其他数据在一个水平线上
forest_features = resample(forest_features,
replace = False, # sample without replacement
n_samples = gress_features.shape[0], # match minority n
random_state = 2)
forest_labels = resample(forest_labels,
replace = False, # sample without replacement
n_samples = gress_labels.shape[0], # match minority n
random_state = 2)
# 数据合并
features = np.concatenate((forest_features, water_features,gress_features,ground_features,built_features,road_features,out_features), axis=0)
labels = np.concatenate((forest_labels, water_labels,gress_labels,ground_labels,built_labels,road_labels,out_labels), axis=0)
# 数据归一化,图片最大值为2047,应当除以2047进行归一化,以图片最大值,不是特征最大值
print(features.min(),features.max())
features = features*4 / (255.0*7)
# 数据划分,将数据分为test和train
train=feature_clip(feature_pos,trainProp,1)
test=feature_clip(feature_pos,trainProp,0)
train_x=features[[train.astype(np.int32)], :, :, :][0]
test_x = features[[test.astype(np.int32)], :, :, :][0]
train_y = labels[train.astype(np.int32)]
test_y = labels[test.astype(np.int32)]
# 创建模型
model = keras.Sequential()
model.add(Conv2D(32,strides=1, kernel_size=1, padding='valid', activation='relu', input_shape=(rowSize, colSize, nBands)))
model.add(Dropout(0.25))
model.add(Conv2D(64,strides=1, kernel_size=1, padding='valid', activation='relu'))
model.add(Dropout(0.25))
model.add(Conv2D(64,strides=1, kernel_size=1, padding='valid', activation='relu'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(7, activation='softmax'))
# 模型训练
model.compile(loss='sparse_categorical_crossentropy', optimizer= keras.optimizers.RMSprop(learning_rate=0.001),metrics=['accuracy'])
history = model.fit(train_x, train_y, epochs=200,verbose=1,steps_per_epoch=2)
# 模型验证与保存
yTestPredicted = model.predict(test_x,steps=1)
classnum=np.argmax(yTestPredicted,axis=1)
model.save('trained_models/CNN_%s_3by3.h5' % (out_model))
#输出误差矩阵
cMatrix = confusion_matrix(test_y,classnum)
print("Confusion matrix:\n", cMatrix)
6、预测土地分类
model = tf.keras.models.load_model('F:\\trained_models\\CNN_7class_3by3.h5')
outFile = 'landsat_7Class_CNN_predicted_3by3.tif'
# 图片读取,可以直接读取前面保存的np数组
features = np.load('CNN_3by3_features.npy')
# 归一化
features = features*4 / (255.0*7)
# 预测并保存结果
newPredicted = model.predict(features)
newPredicted = np.argmax(newPredicted,axis=1)
prediction = np.reshape(newPredicted, (ds.RasterYSize, ds.RasterXSize))
raster.export(prediction, ds, filename=outFile, dtype='float')
7、结果展示
具体代码在github