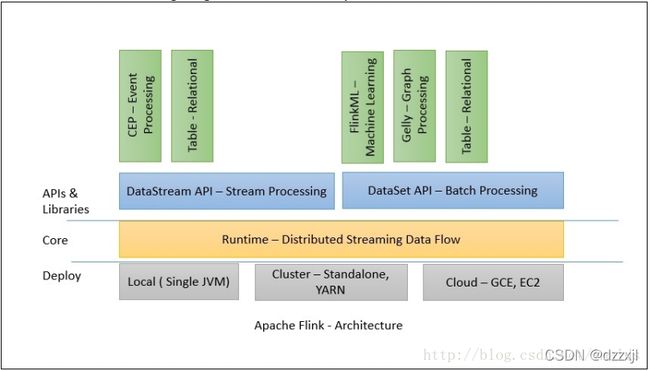
Apache Flink 1.14.0
- 在 Flink 的世界里一切都是流,纯流式计算引擎
- flink是一个类似spark的“开源技术栈”,因为它也提供了批处理,流式计算,图计算,交互式查询,机器学习等。
- flink也是内存计算,比较类似spark,但是不一样的是,spark的计算模型基于RDD,将流式计算看成是特殊的批处理,他的DStream其实还是RDD。而flink把批处理当成是特殊的流式计算,但是批处理和流式计算的层的引擎是两个,抽象了DataSet和DataStream。
- flink在性能上也标新很好,流式计算延迟比spark少,能做到真正的流式计算,而spark只能是准流式计算。而且在批处理上,当迭代次数变多,flink的速度比spark还要快,所以如果flink早一点出来,或许比现在的Spark更火。类似于Spark这种微批的引擎,只是Flink流式引擎的一个特例。
Flink的诞生
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
或许会有人不同意以上的分类,我觉得其实这并不重要的,重要的是体会各个框架的差异,以及更适合的场景。并进行理解,没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能完全取代另一个,就像 Spark 没有完全取代 Hadoop,当然 Flink 也不可能取代 Spark。本文将致力描述 Flink 的原理以及应用。
Flink的历史
其实早在 2008 年,Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。Flink 的最新版本目前已经更新到了 0.10.0 了(摘抄时版本已经到了1.13.2),在很多人感慨 Spark 的快速发展的同时,或许我们也该为 Flink 的发展速度点个赞。
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。
对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。
并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。
就框架本身与应用场景来说,Flink 更相似与 Storm。如果之前了解过 Storm 或者 Flume 的读者,可能会更容易理解 Flink 的架构和很多概念。
Flink 是一个比 Spark 起步晚的项目,但是并不代表 Flink 的前途就会暗淡。Flink 和 Spark 有很多类似之处,但也有很多明显的差异。例如 Flink 如何更高效的管理内存,如何进一步的避免用户程序的 OOM。在 Flink 的世界里一切都是流,它更专注处理流应用。
由于其起步晚,加上社区的活跃度并没有 Spark 那么热,所以其在一些细节的场景支持上,并没有 Spark 那么完善。例如目前在 SQL 的支持上并没有 Spark 那么平滑。在企业级应用中,Spark 已经开始落地,而 Flink 可能还需要一段时间的打磨。
Flink在头条的演进历程
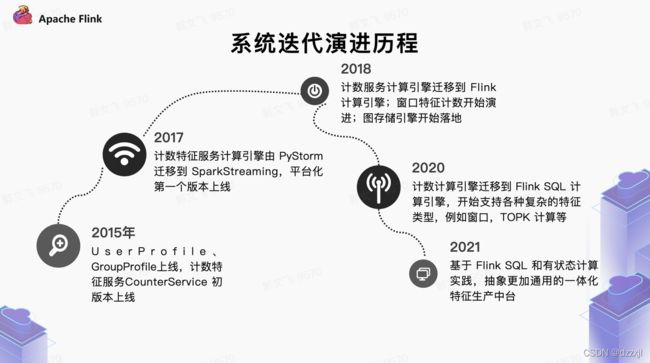
Blink
Blink可以说是基于开源流计算引擎Apache Flink的阿里巴巴定制版。
Flink的部署
Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。对于 Local 模式来说,JobManager 和 TaskManager 会公用一个 JVM 来完成 Workload。如果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者 Yarn Cluster。下面我主要介绍下这两种模式。
Yarn 就会用自己的 Container 来启动 Flink 的 JobManager(也就是 App Master)和 TaskManager。
基础原理
flink核心
Flink 中每一个 TaskManager 都是一个JVM进程,它可能会在独立的线程上执行一个或多个 subtask
flink运行环境
StreamExecutionEnvironment 的socketTextStream 方法并不是自己监听一个端口,起一个服务队,等你给他发消息。是你先得通过nc 启动这个端口,然后flink再与之建立socket连接。
flink运行模式
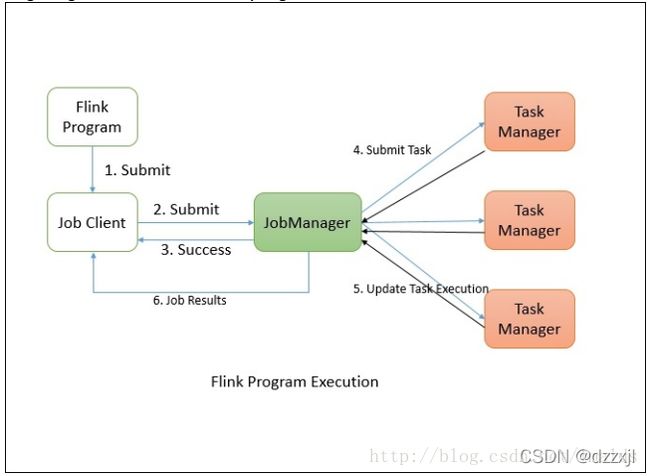
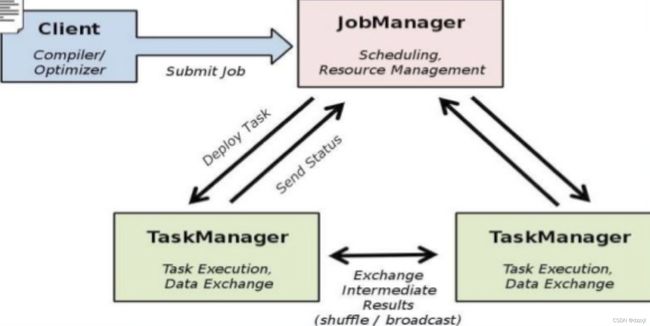
Runtime是主要的数据处理引擎,它以JobGraph形式的API接收程序,JobGraph是一个简单的并行数据流,包含一系列的tasks,每个task包含了输入和输出(source和sink例外)
Flink程序提交给JobClient,JobClient再提交到JobManager,JobManager负责资源的协调和Job的执行。一旦资源分配完成,task就会分配到不同的TaskManager,TaskManager会初始化线程去执行task,并根据程序的执行状态向JobManager反馈,执行的状态包括starting、in progress、finished以及canceled和failing等。当Job执行完成,结果会返回给客户端。
Job Client并不是Flink程序执行中的内部组件,而是程序执行的入口。Job Client负责接收用户提交的程序,并创建一个data flow,然后将生成的data flow提交给Job Manager。一旦执行完成,Job Client将返回给用户结果。
Data flow就是执行计划,比如下面一个简单的word count的程序:
当用户将这段程序提交时,Job Client负责接收此程序,并根据operator生成一个data flow,那么这个程序生成的data flow也许看起来像是这个样子:
默认情况下,Flink的data flow都是分布式并行处理的,对于数据的并行处理,flink将operators和数据流进行partition。Operator partitions叫做sub-tasks。数据流又可以分为一对一的传输与重分布的情况。
我们看到,从source到map的data flow,是一个一对一的关系,没必要产生shuffle操作;而从map到groupBy操作,flink会根据key将数据重分布,即shuffle操作,目的是聚合数据,产生正确的结果。
时间语义
Window机制
Tumbling Windows vs Sliding Windows
可以将Tumbling Windows看作是Sliding Windows的特殊情况,当Sliding Windows的滑动时间和窗口时间是一样的时候,这时候Sliding Windows窗口之间就不会重叠,这就是Tumbling Windows
在Flink中存在非常丰富的窗口函数,包括Global Windows、Tumbling Windows、Sliding Windows以及Session Windows等等,这也是Flink功能强大的一面
flink sql
tumble函数用在group by子句中,用来定义滚动窗口。
TUMBLE(ptime, INTERVAL ‘5’ MINUTE),
TUMBLE(ts, INTERVAL ‘1’ MINUTE)
UDF
flink的udf—自定义函数(UDF)是一种扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑
https://ohmyweekly.github.io/notes/2020-08-22-table-api-user-defined-functions/
Reader与Consumer
除了统一消息 API 之外,由于 Pulsar 主题分区实际上是存储在 Apache BookKeeper 中,它还提供了一个读取 API(Reader),类似于消费者 API(但 Reader 没有游标管理),以便用户完全控制如何使用 Topic 中的消息。
Savepoints和Checkpoints
pass
Flink与Kafka
Flink 提供了特殊的Kafka Connectors来从Kafka topic中读取数据或者将数据写入到Kafkatopic中,Flink的Kafka Consumer与Flink的检查点机制相结合,提供exactly-once处理语义。为了做到这一点,Flink并不完全依赖于Kafka的consumer组的offset跟踪,而是在自己的内部去跟踪和检查。
一致性语义exactly once
exactly-once需要特别注意一个点:
我们必须要求数据sink到外部存储后,offset才能commit,不管是到zk,还是mysql里面,你最好保证它在一个transaction里面,而且必须在输出到外部存储(这里最好保证一个upsert语义,根据unique key来实现upset语义)之后,然后这边源头driver再根据存储的offeset去产生kafka RDD,executor再根据kafka每个分区的offset去消费数据。如果满足这些条件,就可以实现端到端的exactly-once. 这是一个大前提。
- at-most-once:即fire and forget,我们通常写一个java的应用,不去考虑源头的offset管理,也不去考虑下游的幂等性的话,就是简单的at-most-once,数据来了,不管中间状态怎样,写数据的状态怎样,也没有ack机制。
- at-least-once: 重发机制,重发数据保证每条数据至少处理一次。
- exactly-once: 使用粗Checkpoint粒度控制来实现exactly-once,我们讲的exactly-once大多数指计算引擎内的exactly-once,即每一步的operator内部的状态是否可以重放;上一次的job如果挂了,能否从上一次的状态顺利恢复,没有涉及到输出到sink的幂等性概念。
- at-least-one + idempotent = exactly-one:如果我们能保证说下游有幂等性的操作,比如基于mysql实现 update on duplicate key;或者你用es, cassandra之类的话,可以通过主键key去实现upset的语义, 保证at-least-once的同时,再加上幂等性就是exactly-once。
参考
- http://training.data-artisans.com/
- https://tech.meituan.com/Flink_Benchmark.html
- https://blog.csdn.net/lmalds/article/details/60575205