Flink-flink原理解读
1 Task和subtask
1.1 概念
-
Task(任务):Task 是一个阶段多个功能相同 subTask 的集合,类似于 Spark 中的 TaskSet。
-
subTask(子任务):subTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑。
-
Operator Chains(算子链):没有 shuffle 的多个算子合并在一个 subTask 中,就形成了 Operator Chains,类似于 Spark 中的 Pipeline。
-
Slot(插槽):Flink 中计算资源进行隔离的单元,一个 Slot 中可以运行多个 subTask,但是这些 subTask 必须是来自同一个 application 的不同阶段的 subTask。
1.2 如何划分task
Task的并行度发生变化
调用Keyby这样产生shuffle的算子
调用startNewChain
调用disableChaining
处理分区器 Rebalance Shuffle Broadcast Rescale
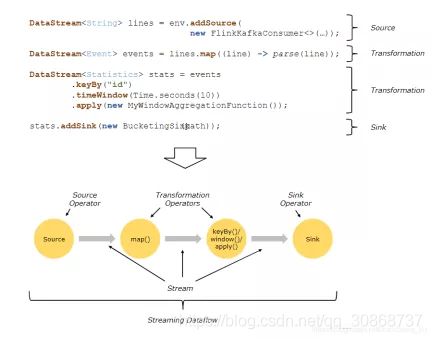
1.3 区别
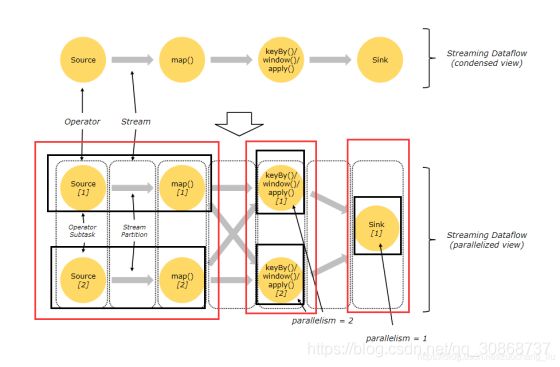
上图并行数据流,一共有 3个 Task,5个 subTask。(红框代表Task,黑框代表subTask)
2 startNewChain的使用
Forward no shuffle
Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first mapper.
someStream.filter(...).map(...).startNewChain().map(...);
3 disableChain的使用
将该算子前面和后面的链都断开
Do not chain the map operator
someStream.map(...).disableChaining();
4 共享资源槽
-
Flink的任务资源草默认名称是default
-
可以通过调用slotSharingGroup方法指定槽位的名称
-
如果改变共享槽位的名称后,后面的没有再设置共享槽位的名称,那么跟上一次改变槽位的名称一致
-
槽位名称不同的subtask不能在一个槽位中执行
每个工作程序(TaskManager)是一个JVM进程,并且可以在单独的线程中执行一个或多个子任务。为了控制一个worker接受多少个任务,一个worker有一个所谓的任务槽(至少一个)。
每个任务槽代表TaskManager的资源的固定子集。例如,具有三个插槽的TaskManager会将其托管内存的1/3专用于每个插槽。分配资源意味着子任务不会与其他作业的子任务竞争托管内存,而是具有一定数量的保留托管内存。请注意,此处没有发生CPU隔离。当前插槽仅将任务的托管内存分开。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager具有一个插槽,意味着每个任务组都在单独的JVM中运行(例如,可以在单独的容器中启动)。具有多个插槽意味着更多子任务共享同一JVM。同一JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。
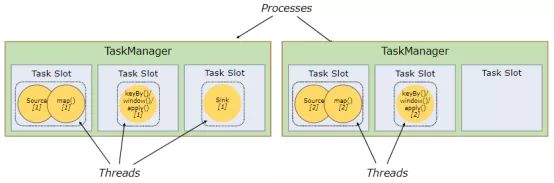
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一作业即可。结果是一个插槽可以容纳整个作业流水线。允许此插槽共享有两个主要好处:
-
Flink集群所需的任务槽数与作业中使用的最高并行度恰好一样。无需计算一个程序总共包含多少个任务(并行度各不相同)。
-
更容易获得更好的资源利用率。如果没有插槽共享,则非密集型 source / map()子任务将阻塞与资源密集型窗口子任务一样多的资源。通过插槽共享,我们示例中的基本并行度从2增加到6,可以充分利用插槽资源,同时确保沉重的子任务在TaskManager之间公平分配。

5 任务重启策略
Flink开启checkpoint功能,同时就开启了重启策略,默认是不停重启
如果不开启checkpoint功能,也是可以配置重启策略的(不能容错)
Flink的重启策略可以配置成启动固定次数且每次延迟指定时间启动
Flink出现异常后,会根据配置的重启策略重新启动,将原来的subtask释放,重新生成subtask并调度到taskmanage的slot中运行
Flink任务重启后,重新生成的subtask被调度到taskmanage中,会从stagebackend中恢复上一次checkpoint的状态
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000));
6 chekpoint
6.1 定义
Flink的 Checkpoint 默认是关闭的,当Flink程序的checkpoint被激活时,状态会被持久化到checkpoint,以防止数据丢失和无缝恢复。状态在内部如何组织和它们如何以及在哪持久化,依赖于所选的状态后端。
Flink默认状态是存储在 JM(JobManager)的 JVM内存中,当然也可以存储在远程文件系统如HDFS,只有将状态的快照持久化的保存起来,才能提供有利的保证,否则存储在 JM 的内存中,JM挂了之后状态就丢失了。
Fkink实时计算为了容错,可以将中间数据定期保存起来,这种定期出发保存中间结果的机制叫checkpointing,它是周期性执行的,具体的过程是JobManager定期的向TaskManager中的SubTask发送RPC消息,subTask将其计算的state保存到stateBackEnd中,并且向JobManager响应checkpointing是否成功,如果程序出现异常或重启,TaskManager中饭的SubTask可以从上一次成功的checkPointing的state恢复

6.2 配置checkpoint
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2 个 Checkpoint 之间最少是要等 500ms,也就是刚做完一个 Checkpoint。比如某个 Checkpoint 做了700ms,按照原则过 300ms 应该是做下一个 Checkpoint,因为设置了 1000ms 做一次 Checkpoint 的,但是中间的等待时间比较短,不足 500ms 了,需要多等 200ms,因此以这样的方式防止 Checkpoint 太过于频繁而导致业务处理的速度下降。
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(6000);
//程序异常退出或人为cancel掉,不删除checkpoint数据(默认是会删除) env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置存储位置覆盖默认方式
env.setStateBackend(new FsStateBackend(args[0]));
7 Barrier
Flink的容错机制主要是通过持续产生快照的方式实现的,对应的快照机制的实现主要由2部分组成,一个是屏障(Barrier),另一个是状态(state)
对齐机制
流屏障(barrier)是Flink分布式快照中的核心元素。这些屏障将注入到数据流中,并与记录一起作为数据流的一部分流动。壁垒从不超越记录,它们严格按照顺序进行。屏障将数据流中的记录分为进入当前快照的记录集和进入下一个快照的记录集。每个屏障都带有快照的ID,快照的记录已推送到快照的前面。屏障不会中断流的流动,因此非常轻便。来自不同快照的多个障碍可以同时出现在流中,这意味着各种快照可能会同时发生。

流屏障在流源处注入并行数据流中。快照n的屏障被注入的点(我们称其为 S n)是快照中覆盖数据的源流中的位置。例如,在Apache Kafka中,此位置将是分区中最后一条记录的偏移量。该位置S n 被报告给检查点协调器(Flink的JobManager)。
然后,屏障向下游流动。当中间操作员从其所有输入流中收到快照n的屏障时,它会将快照n的屏障发射到其所有输出流中。接收器运算符(流式DAG的末尾)从其所有输入流接收到屏障n后,便将快照n确认给检查点协调器。所有接收器都确认快照后,就认为快照已完成。
一旦完成快照n,该作业将不再向源请求S n之前的记录,因为此时这些记录(及其后代记录)将通过整个数据流拓扑。

接收多个输入流的操作员需要在快照屏障上对齐输入流。上图说明了这一点:
1.操作员一旦从传入流接收到快照屏障n,就无法处理该流中的任何其他记录,直到它也从其他输入接收到屏障n为止。否则,它将混合属于快照n的记录和属于快照n + 1的记录。
2.一旦最后一个流接收到屏障n,操作员将发出所有未决的传出记录,然后自身发出快照n屏障。
3.它快照状态并恢复所有输入流中的记录处理,在处理来自流中的记录之前,先处理输入缓冲区中的记录。
4.最后,操作员将状态异步写入状态后端。
请注意,所有具有多个输入的运算符以及经过洗牌后的运算符使用多个上游子任务的输出流时,都需要对齐。
8 state
8.1 概念
State是flink计算过程的中间结果和状态信息,为了容错,必须把状态持久化到一个外部的系统中
State可以是多种类型的,默认是保存在jobManage的内存中,也可以保存到taskmanage本地文件系统或者HDFS这样的分布式文件系统中
8.2 分类
Keystate
调用keyby方法后,每个分区中相互独立的state
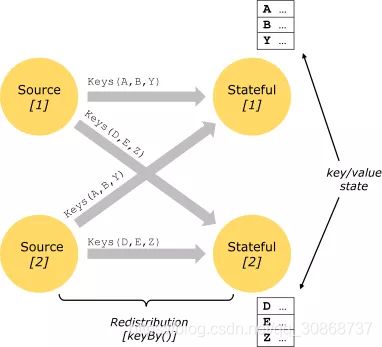
Operatorstate
没有分组,每一个subtask自己维护一个状态
与Keyed State不同,Operator State跟一个特定operator的一个并发实例绑定,整个operator只对应一个state。相比较而言,在一个operator上,可能会有很多个key,从而对应多个keyed state。而且operator state可以应用于非keyed stream中。
举例来说,Flink中的Kafka Connector,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射。
Broadcast state
广播state,一个可以通过connect方法获取广播流的数据,广播流的特点是可以动态更新
广播state通常作为字典数据,维度数据关联,广播到属于该任务的所有taskmanager的每个taskslot中,类似于map
8.3 应用
1.先定义一个状态描述器
//广播数据的状态描述器
MapStateDescriptor mapStateDescriptor = new MapStateDescriptor(
"broadcasr-state",
String.class,
String.class
);
2.通过context获取state
3.对数据处理后要更新数据
8.4 operator state和keyed state的一致性
参考7 Barrier
9 stateBackEnd
用来保存state的存储后端就叫做stateBackEnd,默认是保存在JobManager的内存中,也可以保存在本地文件系统或者HDFS这样的分布式文件系统
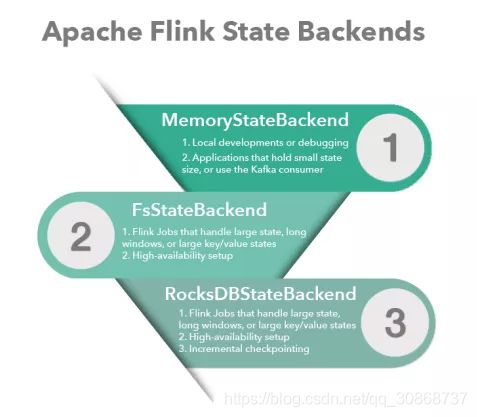
在没有配置的情况下,系统默认使用 MemoryStateBackend。
尽管有checkpoint保证exactly-once,但对于实时性要求高的业务场景,每次重启所消耗的时间都可能会导致业务不可用。也许你也经常遇到这样的情况,checkpoint又失败了?连续失败?task manager 内存爆了?这些情况都很容易导致Flink任务down了,这时候需要思考下你所处的业务场景下,选用的Flink State Backends是否合理?
9.1 MemoryStateBackend
Checkpoint 的存储,第一种是内存存储,即 MemoryStateBackend,构造方法是设置最大的StateSize,选择是否做异步快照,这种存储状态本身存储在 TaskManager 节点也就是执行节点内存中的,因为内存有容量限制,所以单个 State maxStateSize 默认5M,且需要注意 maxStateSize <= akka.framesize 默认 10 M。Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。推荐使用的场景为:本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。不推荐在生产场景使用。
9.2 FsStateBackend
存储在文件系统上的 FsStateBackend ,构建方法是需要传一个文件路径和是否异步快照。State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 有 5 M 的设置上限,Checkpoint 存储在外部文件系统(本地或 HDFS),打破了总大小 Jobmanager 内存的限制。容量限制上,单 TaskManager 上 State 总量不超过它的内存,总大小不超过配置的文件系统容量。推荐使用的场景、常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
9.3 RocksDBStateBackend
存储为 RocksDBStateBackend ,RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过 RocksDB 支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
10 flink如何保证ExactlyOnce的
使用执行exactly-once的数据源,如kafka
开启checkpoint,并且设置checkpointingMode.EXACTLY_ONCE,不让消费者自动提交偏移量
存储系统支持覆盖(redis,Hbase,ES),使用其幂等性,将原来的数据覆盖
Barrier(隔离带)可以保证一个流水线中的所有算子都处理完成了在对该条数据做checkpoint
存储系统支持事务
Jobmanager定时出发checkpoint的定时器(checkpointCodination)给有状态的subtask做checkpoint
Checkpoint成功后,将数据写入statebackend中
写成功后向jobmanager发送ack应答
Jobmanager接收到所有subtask的响应后,jobmanager向所有实现了checkpointListener的subtask发送notifycompleted方法成功的消息
把数据写入kafka,提交事务,即使提交事务失败,也没关系,会重启从checnkpoint恢复再写
11 flink背压机制
Flink 在运行时主要由 operators 和 streams 两大组件构成。每个 operator 会消费中间态的流,并在流上进行转换,然后生成新的流。对于 Flink 的网络机制一种形象的类比是,Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。还记得经典的线程间通信案例:生产者消费者模型吗?使用 BlockingQueue 的话,一个较慢的接受者会降低发送者的发送速率,因为一旦队列满了(有界队列)发送者会被阻塞。Flink 解决反压的方案就是这种感觉。
在 Flink 中,这些分布式阻塞队列就是这些逻辑流,而队列容量是通过缓冲池(LocalBufferPool)来实现的。每个被生产和被消费的流都会被分配一个缓冲池。缓冲池管理着一组缓冲(Buffer),缓冲在被消费后可以被回收循环利用。这很好理解:你从池子中拿走一个缓冲,填上数据,在数据消费完之后,又把缓冲还给池子,之后你可以再次使用它。
12 两段提交原理
12.1 原理
Jobmanager定时出发checkpoint的定时器(checkpointCodination)给有状态的subtask做checkpoint
Checkpoint成功后,将数据写入statebackend中
写成功后向jobmanager发送ack应答
Jobmanager接收到所有subtask的响应后,jobmanager向所有实现了checkpointListener的subtask发送notifycompleted方法成功的消息
把数据写入kafka,提交事务,即使提交事务失败,也没关系,会重启再写
12.2 mysql分两段提交代码实现
package com.wedoctor.flink;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class DruidConnectionPool {
private transient static DataSource dataSource = null;
private transient static Properties props = new Properties();
static {
props.put("driverClassName", "com.mysql.jdbc.Driver");
props.put("url", "jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8");
props.put("username", "root");
props.put("password", "123456");
try {
dataSource = DruidDataSourceFactory.createDataSource(props);
} catch (Exception e) {
e.printStackTrace();
}
}
private DruidConnectionPool() {
}
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
}
package com.wedoctor.flink;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.typeutils.base.VoidSerializer;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;
import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction, MySqlTwoPhaseCommitSink.ConnectionState, Void> {
public MySqlTwoPhaseCommitSink() {
super(new KryoSerializer<>(MySqlTwoPhaseCommitSink.ConnectionState.class, new ExecutionConfig()), VoidSerializer.INSTANCE);
}
@Override
protected MySqlTwoPhaseCommitSink.ConnectionState beginTransaction() throws Exception {
System.out.println("=====> beginTransaction... ");
Connection connection = DruidConnectionPool.getConnection();
connection.setAutoCommit(false);
return new ConnectionState(connection);
}
@Override
protected void invoke(MySqlTwoPhaseCommitSink.ConnectionState connectionState, Tuple2 value, Context context) throws Exception {
Connection connection = connectionState.connection;
PreparedStatement pstm = connection.prepareStatement("INSERT INTO t_wordcount (word, counts) VALUES (?, ?) ON DUPLICATE KEY UPDATE counts = ?");
pstm.setString(1, value.f0);
pstm.setInt(2, value.f1);
pstm.setInt(3, value.f1);
pstm.executeUpdate();
pstm.close();
}
@Override
protected void preCommit(MySqlTwoPhaseCommitSink.ConnectionState connectionState) throws Exception {
System.out.println("=====> preCommit... " + connectionState);
}
@Override
protected void commit(MySqlTwoPhaseCommitSink.ConnectionState connectionState) {
System.out.println("=====> commit... ");
Connection connection = connectionState.connection;
try {
connection.commit();
connection.close();
} catch (SQLException e) {
throw new RuntimeException("提交事物异常");
}
}
@Override
protected void abort(MySqlTwoPhaseCommitSink.ConnectionState connectionState) {
System.out.println("=====> abort... ");
Connection connection = connectionState.connection;
try {
connection.rollback();
connection.close();
} catch (SQLException e) {
throw new RuntimeException("回滚事物异常");
}
}
static class ConnectionState {
private final transient Connection connection;
ConnectionState(Connection connection) {
this.connection = connection;
}
}
}