【Python机器学习】K-Means、DBSCAN、GMM三种聚类的对比演示(附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
下面给出一个从多方面综合分析划分聚类,密度聚类和模型聚类。以及聚类算法内部评价指标的示例,该示例先生成三种二维平面上的实验数据和一种高维空间中的实验数据,然后分别用kmeans,DBSCAN,GaussianMixture三种算法对它们进行聚类,并计算SC DBI CH ZQ四个指标,展示实验样本点的分布与聚类算法实用性,评价指标值有效性的关系。
三种二维平面上的实验样本图如下,它们分别是圆环,高斯分布和月牙形状的,由datasets模块中响应的函数产生

高维空间中的实验样本通过PCA降维后,在二维平面上的分布如下所示,它是由datasets模块中的make_gaussian_quantiles()函数在四维空间中以原点为中心,按高斯分布随机产生的,由内向外分为9层的类球状分布,随后去掉1-6层和第8层,只保留内核的第0层和外面的第7层,可以将此数据想象成一个带核的空心四维类球体
三种聚类算法的结果以及指标值对比如下图所示
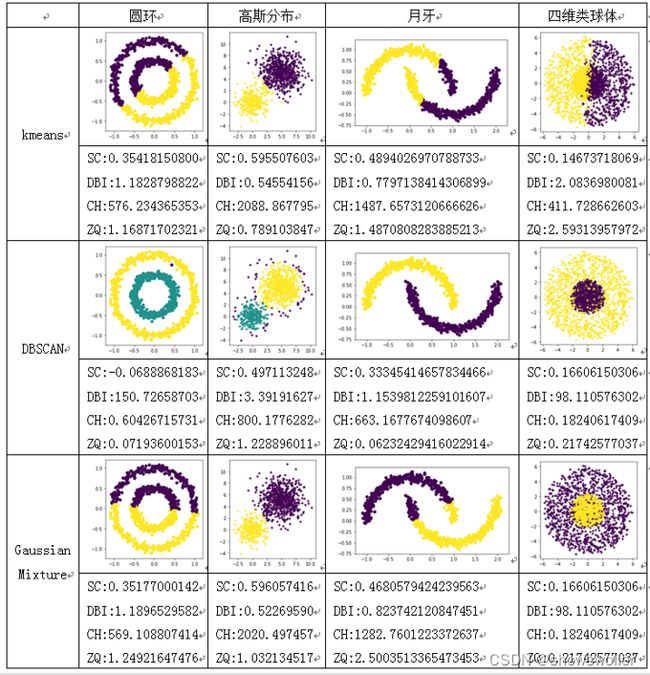
DBSCAN算法对非凸簇有较好的聚类效果,GaussianMixture算法对高斯分布的簇有较好的聚类效果,四维类球体样本集也是按高斯分布产生的,因此它可以很好地学习到模型参数,高斯分布的样本集在实际工程中比较常见
预先探索样本集在空间中的分布对于选择合适的聚类算法也很重要,除了通过降维来直观的观察样本集在空间中的分布外,聚类内部评价指标也可以帮助分析,比如在面对大数据量的聚类任务时,可以先随机抽取或者划分网格抽取小部分样本进行试分簇,如果发现运行DBSCAN算法后的ZQ指标改善较多,而其他指标变差,则样本集可能是非凸的分布
部分代码如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans, DBSCAN
from sklearn.mixture import GaussianMixture
from sklearn import metrics
from zqscore import ZQ_score
X1, y1 = make_blobs(n_samples=300, n_features=2, centers=[[0,0]], cluster_std=[1.2])
X2, y2 = make_blobs(n_samples=600, n_features=2, centers=[[3,3]], cluster_std=[1.8])
plt.scatter(X1[:, 0], X1[:, 1], marker='o', color='r')
plt.scatter(X2[:, 0], X2[:, 1], marker='+', color='b')
plt.show()
y_pred = gm.predict(X)
C1 = []
C2 = []
for i in range(len(X)):
if y_pred[i] == 1:
C1.append(list(X[i]))
else:
C2.append(list(X[i]))
C1 = np.array(C1)
C2 = np.array(C2)
plt.scatter(C1[:, 0], C1[:, 1], marker='o', color='r')
plt.scatter(C2[:, 0], C2[:, 1], marker='+', color='b')
plt.show()
samples = np.loadtxt("kmeansSamples.txt")
gm = GaussianMixture(n_components=2, random_state=0).fit(samples)
labels = gm.predict(samples)
plt.scatter(samples[:,0],samples[:,1],c=labels+1.5,linewidths=np.power(labels+1.5, 2))
plt.show()创作不易 觉得有帮助请点赞关注收藏~~~