寻找值得学习的强化学习自定义
文章目录
- 前言
- 一、隐性扰动人工调整数据?
- 二、车间调度问题的转化
-
- 2.1.状态空间
- 2.2 动作空间
- 2.3 奖惩函数
- 2.4环境
- 三、深度强化学习算法
-
- 3.1动作探索策略
- 3.2激活函数的选择
- 3.3 DDPG 算法
- 总结
前言
标题: 基于深度强化学习的离散型制造企业车间动态调度研究
作者:蒋静静
文献摘要
为了适应变化万千、竞争激烈的市场环境,制造企业向多类型、小规模的离散制造模式转变,导致车间生产过程变得复杂动态,发生突发事件的概率大大提高。而目前离散型制造企业使用的车间调度系统,同生产实际情况相差甚远,在复杂动态场合很难应用,通常需要人工对调度方案进行适应性调整。但是人工调整的优劣取决于调度员的经验和知识水平,而且往往需要耗费大量的时间和劳动力,调度方案的稳定性及车间生产效率难以保证。所以,迫切需要改善生产车间依赖人工调整的现状。与此同时,智能制造与数字化工厂的发展,使生产车间产生大量数据,为机器…
关键词
动态车间调度;深度强化学习算法;隐性扰动;智能制造
文献链接
https://x.cnki.net/kcms/detail/detail.aspx?dbname=CMFD2021&filename=1020306632.nh&dbcode=CMFD
一、隐性扰动人工调整数据?
加工时间的偏差、人工水平的高低
1).调整时刻点确定
隐性扰动只有达到一定程度,才能被发现;人工调整开始时刻的确定就需要对隐性扰动采取量化的方式。
隐性扰动的触发与否可以通过初始调度方案与实际调度方案的加工时间偏差得以体现;
分别记录每一个工件初始调度方案得到的理想加工时间以及实际加工中得到的实际加工时间,通过对比二者的差值获取人工调整的触发时间。
当工件的实际加工时间与理想加工时间差值大于扰动阈值时,表明实际加工情况受到影响,确定该时刻为调整时刻点;当实际加工时间小于等于理想加工时间时,表明生产过程未受影响,不触发人工调整操作。
2).深度网络的输入
人工在进行调整操作时判断的因素主要是生产加工信息:

3). 深度网络的输出标签
深度网络的输出标签对应隐性扰动下人工调整的操作方式。选取延后加工与重排两种调整方式。当选择重排操作时,输出标签为 1,当选择延后加工时,输出标签为 0。
二、车间调度问题的转化
当机器数量变大时,在模型中仅使用一个机器智能体时的动作空间将太大,导致训练深度强化学习将成为一项艰巨的任务。
MDP 和 MMDP 之间的主要区别在于 MDP 仅具有一个智能体来处理所有机器,因此,需要该智能体调度的整个情况。在 MMDP 中,可以使用多个智能体与多台机器进行关联,因此,MMDP 建模更加灵活,并且避免了在发生机器故障时重新计划时间表。而且,单个智能体的集中控制计算复杂度高,对于解决大规模问题适应性较差。
``
2.1.状态空间
车间调度问题与深度强化学习结合优劣的关键就是状态空间、动作空间以及奖惩函数的定义。
定义状态空间,首先,需要保证对深度强化学习的环境进行全面描述,能够捕捉各种情况下环境的变化。其次,为了本文算法的灵活性,状态空间的定义还必须考虑到向其他类型的调度问题的泛化能力。最后,选取的状态空间还必须便于计算,方便神经网络快速拟合状态值。
状态空间设置为三个矩阵的形式,包括加工时间矩阵、任务分配布尔矩阵和加工情况布尔矩阵。
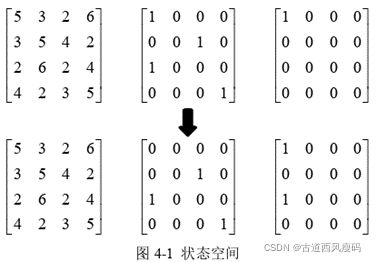
第一个矩阵为加工时间矩阵,反映各工序在该机器上的加工时间,如果不可以加工,加工时间取无穷大,保证机器智能体优化过程中不会选取该工序。第二个矩阵为任务分配布尔矩阵,是该机器智能体在加工过程中缓冲区停放的工序,作为该机器的待加工工序。第三个矩阵为该机器智能体已加工完成的工序。当机器智能体在下一状态选择工序O31这一动作时,此刻适用的规则是 SPT 规则,状态空间将作如图 4-1 所示的更新,可以快速地反映环境变化。同时,这三个矩阵表示可以对应卷积神经网络输入状态的三个不同通道。这种表示类似于图像的 RGB 通道,便于计算。
2.2 动作空间
车间调度问题的动作空间指机器在当前状态下选取缓冲区的任一工件进行加工的这一行为。车间调度规则作为深度强化学习的动作空间。

2.3 奖惩函数
可以通过奖励函数作为了算法的偏向和最终目标。所以奖惩函数的设置需要具备以下特点:第一,奖惩函数值需要反映智能体行为的即时奖励,所以在函数的设置过程中,需要考虑该因素;
第二,累计的奖惩值总和关系着深度强化学习网络的收敛方向,所以一般选取优化目标作为奖惩函数;
第三,函数设置需要满足通用性,适用不同的规模。

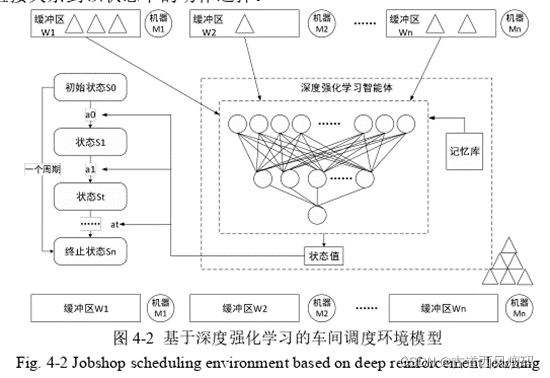
2.4环境
车间调度环境模型包括缓冲区以及加工单元。
三、深度强化学习算法
3.1动作探索策略
选用的方法是ε贪婪策略。
3.2激活函数的选择
在构建网络模型过程中,选择一种好的激活函数能大大提高网络对非线性复杂数据的学习能力。
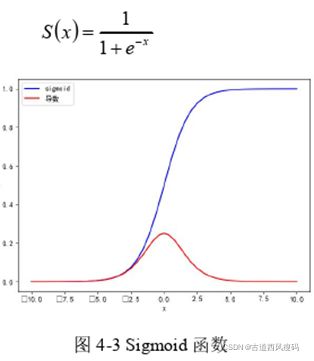
- Sigmoid 函数
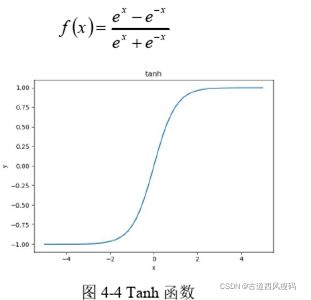
2)Tanh 激活函数是Sigmoid 函数的变形公式
- 对于深度强化学习网络来说,ReLU 激活函数使用的比较多。

3.3 DDPG 算法
在 Q 学习中,值函数是学习算法的主要元素。对于小规模的问题,可以在计算机内存中将值函数Q(s,a)保存。但是,对于大规模问题,Q(s,a)的数量将是巨大的,甚至是无限的。我们的目标是学习行为,而不是仅使用贪婪策略。采用 DDPG 同时获得价值估计和行为估计。
在动态环境中训练 RL 智能体时,状态 s(t)和 s(t+1)之间的强相关性使智能体的即时更新效率降低。智能体需要在环境中执行更多的迭代,以找到更多的状态样本。但是,DQN 算法通过经验重播机制的巨大经验数据池解决了此问题。智能体的每个步骤的经验将存储在一个大型数据集中,智能体将通过从经验库中采样而不是使用即时情况进行更新。综合了 DQN 和 Actor-Critic 两种算法的 DDPG 算法.
使用的 DDPG 算法中的 DRL 智能体被分为批评家网络和行动者网络两部分,从两个方面对作业车间调度问题进行分析。
在评论者网络中,智能体评估行为的值,并给出一个近似值,使智能体知道它所面对的状态是好还是坏。
同时,行动者网络依赖于评论者网络给出的近似值来做出相应的行为。整个过程就像一个教学场景,评论者网络是老师,行动者网络是学生。当遇到问题时,学生给出答案,然后老师检查学生的作业,并根据答案给学生奖励。
总结
这篇学位论文是2020年的毕业作品,现在看来虽然稍有瑕疵,但是可取之处还是很多,其中的强化学习部分在状态设置上和同期论文有相似之处,但是作为学习对象也足够了。从这次开始,我要重点关注不同论文的状态定义,虽然作为新手,我的看法是车间调度问题的状态设置是非常重要的,会直接导致训练结果是否令人满意。
欢迎有想法需要相互学习的同学联系[email protected]