65、Dex-NeRF: Using a Neural Radiance Field to Grasp Transparent Objects
简介
主页:https://sites.google.com/view/dex-nerf
论文利用JaxNeRF(50k迭代)为透明物体的场景建模,获取透明物体的深度图,交给Dex-Net训练机械臂。
掌握和操作透明物体的能力是机器人面临的主要挑战,传统的机器人抓取方法是通过分析物体形状来识别成功的抓取姿势,数据驱动方法使用标记数据或通过在模拟或物理环境中进行多次试验的自我监督进行先验学习,并推广到掌握具有未知几何形状的新对象,其依赖于RGB和深度传感器来生成对目标物体的精确观测
现有的深度相机假设被观测物体的表面向各个方向均匀地反射光,但这一假设不适用于透明物体,因为由于透明材料的反射和折射特性,在不同的视点方向和光照条件下,透明物体的外观会发生显著的变化,论文使用神经辐射场(NeRF)来检测、定位和推断透明物体的几何形状,并具有足够的准确性来安全地发现和掌握它们,同时利用NeRF的视依赖性学习密度,放置灯光来增加镜面反射,并执行一个透明感知的深度渲染。从NeRF模型渲染一个高质量的深度图,然后传递到Dex-Net计算把握
实现流程
假设在一个环境中,在已知的固定位置有一组相机,或者机器人可以操纵一个相机(例如,手腕安装)来捕捉场景的多个图像,给定刚性透明物体的环境,Dex-NeRF计算机器人抓取器的框架
NeRF公式回顾
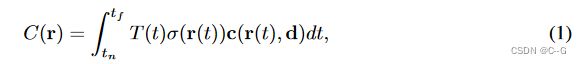

Recovering Geometry of Transparent Objects
NeRF通过回归视图方向和监督与视图相关的发射辐射来恢复非朗伯效应,例如来自镜面的反射,并不直接支持透明的物体效果——它对每个源图像像素投出单一的射线,没有反射、分裂或反弹。
虽然RGB颜色c是视相关的,体积密度σ不是——这意味着NeRF必须学习一个非零σ来表示该空间位置上的任何颜色。否则,通常的结果是,在渲染的RGB图像中,透明对象显示为原始对象的“幽灵”或“模糊”版本。

Rendering Depth for Grasp Analysis
Dex-NeRf 渲染一个深度图像,并让 Dex-Net 使用它来规划抓取,这里考虑了两种候选的深度重建
- 用与NeRF相同的深度渲染。NeRF重构首先将 σ i σ_i σi转换为占用概率 α i α_i αi。然后应用变换 w i = α i ∏ j = 1 i − 1 ( 1 − α j ) w_i = α_i∏^{i−1}_{j=1}(1−α_j) wi=αi∏j=1i−1(1−αj)。为了渲染像素坐标 [u, v] 处的深度,它计算到相机的样本距离之和,由终止概率 D [ u , v ] = ∑ i = 1 N w i δ i D[u, v] =∑^N_{i=1}w_iδ_i D[u,v]=∑i=1Nwiδi。当应用于透明对象时,这将导致噪声深度映射
- Dex-NeRF 沿着 σ i > m σ_i > m σi>m 的射线搜索第一个样本,其中 m是一个固定的阈值。然后将深度设置为样品 δ i δ_i δi 的距离。论文研究了不同的 m 值,观察到较低的值会导致有噪声的深度图,而较高的值会在深度图中产生洞,导致部分场景消失,论文采用m = 15

Dex-NeRF使用透明的深度渲染来渲染深度图,可以用于抓取规划。相比之下,NeRF的深度图充满了洞,导致了糟糕的把握预测。
Improving Reconstruction with Light Placement
对于NeRF学习一个透明物体的几何形状,它必须能够从多个相机视图“看到”它。如果透明对象在任何视图中都不可见,那么它将对训练中使用的损失函数没有影响,因此不会被学习到。因此,寻找一种方法来提高NeRF对透明对象的可见性。
透明物体(如玻璃、透明塑料)共有的一个特性是,它们具有光泽,因此当相机的视角方向与光入射方向的表面法线相反时,就会产生镜面反射
在NeRF模型中,从多个角度观看镜面反射时,在固体表面上会出现一个亮点。 c = [ 1 , 1 , 1 ] T c = [1,1,1]^T c=[1,1,1]T, σ > 0,而从其他角度则表现为 σ≤0,由于 σ 与视图无关,对于这些点,NeRF在完全不透明和完全透明之间学习 σ。
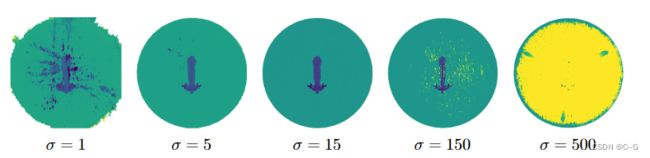
论文通过在场景中放置额外的光,创造了更多的角度,摄像机将从透明物体看到镜面反射,NeRF学习的模型,填补了场景中的洞。虽然用于优化训练的光的数量和位置取决于预期的物体分布和摄像机位置,实验表明从单顶高强度灯增加到5x5光阵列可以提高学习到的几何质量。
更多的光意味着更多的镜面反射,并导致更好的NeRF深度估计透明表面。
在(a)和(b)中,展示了一个由单顶高强度灯照亮的场景。
在( c)和(d)中,展示了由头顶5x5的灯光阵列照亮的同一场景。两种场景的总光瓦数相等。
(a)和( c)为现场视图,(b)和(d)为从管道中获得的相应深度图像。
在(b)中,两侧的两个玻璃缺少顶部表面(用红色虚线表示),而在(d)中,由于增加了光源,效果降低了。
效果
机械臂目标是抓住一个置于稳定姿势的透明物体,并与其他透明物体靠近,深度渲染质量应该足以把握规划和避免碰撞,最终的抓取接触点精确到2毫米的公差,这表明从精确已知的相机位置拍摄的足够图像的Dex-NeRF可能在高度杂乱的环境中是实用的。

模拟实验中合成的单一对象。第一行:训练数据中对象的图像。最下面一行:计算深度图和候选掌握。
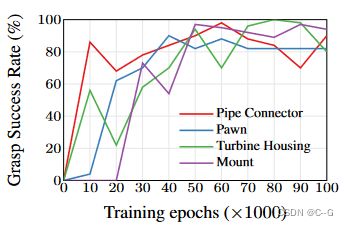
掌握成功率vs训练时间。与需要超过20万epoch的视图合成相反,我们观察到在5万到6万epoch后的高把握成功率。

物理把握对象。背景是YuMi机器人的底座。
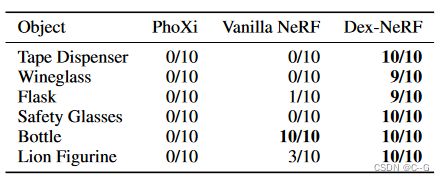
物理抓握成功率。对于每个对象,使用PhoXi相机、未修改的Vanilla NeRF和用于抓取透明对象的Dex-NeRF计算深度图。从深度图中,Dex-Net计算10种不同的抓取,ABB YuMi尝试抓取。成功的把握举起了物体。