Spring——配置数据源和数据库连接池
文章目录
-
- 一、高内聚低耦合
- 二、数据库连接池
- 1、什么是数据库连接池
- 2、常用数据库连接池
- Druid
- 二、配置数据源
- 1、抽取properties文件
- 2、spring配置数据源对象
- 3、加载properties配置文件
- 三、利用数据源查询数据库
- 1、properties文件配置
- 2、将properties文件加载到spring容器
- 3、实现查询数据库
一、高内聚低耦合
“”高内聚,低耦合”是相对于代码而言,一个项目中:每个模块之间相互联系的紧密程度,模块之间联系越紧密,则耦合性越高,模块的独立性就越差!一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即‘高内聚’ !我们对于程序的要求就是要高内聚,低耦合,出现各个框架都是为了更好的解耦。比如你表现层代码需要改动,不会影响到业务逻辑层或者持久层,那就说明模块之间联系不高,耦合性就低。将来若是某个技术特别优秀,我们需要重构代码,如果代码耦合度低,那就很方便重构,反之就得改动许多的程序。
下面讲到的配置数据源就是为了很好的解耦,为什么我们在获取连接时要避免硬编码,为什么要配置文件,为什么要有spring容器,这些都是为了降低代码耦合度,使后期维护代码更方便。
二、数据库连接池
1、什么是数据库连接池
概念:数据库连接池是存放数据库连接的一个容器,当系统初始化后,容器被创建,容器会申请一些连接对象放在数据库连接池里面。当用户来访问时,由数据库连接池分配连接给用户。当用户访问结束后,会将连接归还给连接池,而不是将其销毁掉。
优点:
(1)资源的重用:当一个连接被用户使用完成之后,数据库连接池会回收连接,并不是直接将它销毁掉,能够保持资源重用性。
(2)访问高效性,提高访问效率:在原始创建连接时,对系统底层空间不友好。并且运行一个程序都会重新申请获取连接,如果运行后没有关闭连接对内存消耗很大。数据库连接池就针对这些问题有很好改进。
(3)避免数据库连接遗漏;在申请连接之后一直没有销毁,而你的系统出现断网关机等问题都可能导致连接遗漏。数据库连接池有一个超时属性,可以很好避免这些情况。
2、常用数据库连接池
现在使用的数据库连接池差不多都是Druid,还有就是c3p0,dbcp等,他们操作步骤大致一样,我就只演示Druid了
下面实现手动配置连接数据库。
Druid
实现步骤:
-
导入Druid坐标以及数据库驱动坐标
具体坐标我放在下面了,复制即可用。mysql mysql-connector-java 5.1.32 com.alibaba druid 1.2.1 -
创建数据库连接池对象
原始方法就直接new一个DruidDataSource对象就行。
![]()
- 设置数据库连接池的基本信息
这里先用硬编码演示
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/dbcsdn");
dataSource.setUsername("root");
dataSource.setPassword("1234");
-
获取连接
DruidPooledConnection connection = dataSource.getConnection(); -
操作数据库
String sql = "select * from stu";
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String adr = resultSet.getString("adr");
System.out.print("id:"+id+"\t");
System.out.print("username:"+name+"\t");
System.out.println("password:"+adr);
System.out.println("---------------");
}
-
释放资源
statement.close(); connection.close(); dataSource.close();
对数据库连接池大致操作就是这些了。
二、配置数据源
数据源(DataSource):是由SUN公司制定的用于获取数据库连接的规范接口。它可以实现获取连接,获取数据库基本信息等等。
下面的操作都以Druid连接池为例。
1、抽取properties文件
什么是properties文件:在获取连接之前我们需要把驱动信息,数据库地址,还有用户名密码等通过硬编码方式写在代码里面,这样的方式不能实现“低耦合”的思想。但是如果我们直接把数据库信息配置在一个文件里面,直接在代码里面加载配置文件,对后期代码维护较为友好。而且编译之后的代码时字节码文件,配置文件不会编译成字节形式,我们维护信息只需要修改配置文件就行。
抽取druid.properties文件:
在resources目录下面新建一个druid.properties文件,用于存放连接信息以及连接池信息。配置以下信息:
druid.driver=com.jdbc.mysql.Driver
druid.url=mysql:jdbc://localhost:3306:dbcsdn
druid.username=root
druid.password=1234
当然,你的数据库地址用户名密码可能不同,你自己修改一下。
测试是否配置成功:
先读取配置文件,我用properties读取总读取不到,后面换了ResourceBundle读才行。
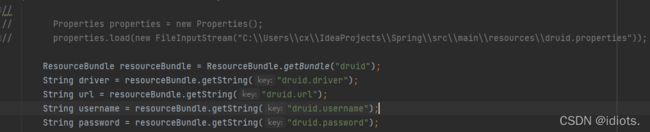
后面的代码都大同小异,就不拿出来了。
2、spring配置数据源对象
这里的spring配置数据源对象就是配置一个Druid的实现类的具体属性注入。就是把连接信息配置到spring容器中直接拿来用。和前面属性注入一样,先配置一个DruidDataSource对象,然后在里面配置连接信息,连接池信息等。
下面就是我配置的数据源对象
下面就可以从容器里面拿对应的实例化对象来用了
@Test
//测试spring依赖注入DruidPooledConnection
public void DruidTest003() throws SQLException {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext-Druid.xml");
DruidDataSource dataSource = applicationContext.getBean("dataSource", DruidDataSource.class);
DruidPooledConnection connection = dataSource.getConnection();
System.out.println(connection);
}
}
可以看到有连接地址,说明已经获取连接,后面就可以操作数据库了。
![]()
3、加载properties配置文件
我们前面不管是使用properties配置文件,还是使用依赖注入连接信息,都是为了解耦。然而配置文件还是需要输入配置连接信息的key值信息。而依赖注入需要输入配置文件的具体信息,也就是value里面的值还是有硬编码的情况。那有没有耦合度更低的解决方法呢,答案是有的,就是将properties文件加载到xml依赖注入文件里面。这样如果换了连接信息,直接在properties文件里面修改就行,不需要动xml文件里面的信息了,这样耦合度更低。
下面介绍如何实现加载properties配置文件:
- 引入context命名空间
这里引入context命名空间和前面的set注入引入的p命名空间大致相同。将下列两句加到图示的位置就OK了。
xmlns:context="http://www.springframework.org/schema/context"
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd

-
加载外部的properties文件
利用context:property-placeholder标签,然后利用location属性将properties位置赋值过去。现在properties文件的内容就加载到spring容器里面了。 -
利用properties文件里面的键名赋给实例化对象的属性名,这样就可以通过键名找到对应的连接信息或者连接池配置了。这里用到了spel表达式,它和el表达式一样都是${键名},其实spel就是spring的el表达式。
-
最后测试效果
@Test
//测试properties加载到spring容器里面
public void DruidTest004() throws SQLException {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext-Druid.xml");
DruidDataSource dataSource = applicationContext.getBean("dataSource", DruidDataSource.class);
DruidPooledConnection connection = dataSource.getConnection();
System.out.println(connection);
}
可以看到是有输出的,证明获取到连接了。
![]()
三、利用数据源查询数据库
1、properties文件配置
druid.driver=com.mysql.jdbc.Driver
druid.url=jdbc:mysql://localhost:3306/dbcsdn
druid.username=root
druid.password=1234
2、将properties文件加载到spring容器
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:druid.properties">context:property-placeholder>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${druid.driver}">property>
<property name="url" value="${druid.url}">property>
<property name="username" value="${druid.username}">property>
<property name="password" value="${druid.password}">property>
bean>
beans>
3、实现查询数据库
@Test
//测试properties加载到spring容器里面
public void DruidTest004() throws SQLException {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext-Druid.xml");
DruidDataSource dataSource = applicationContext.getBean("dataSource", DruidDataSource.class);
DruidPooledConnection connection = dataSource.getConnection();
String sql = "select * from stu";
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String adr = resultSet.getString("adr");
int score = resultSet.getInt("score");
String gender = resultSet.getString("gender");
System.out.print("id:"+id+"\t");
System.out.print("username:"+name+"\t");
System.out.print("password:"+adr+"\t");
System.out.print("score:"+score+"\t");
System.out.println("gender:"+gender);
}
statement.close();
connection.close();
dataSource.close();
}

这里只是简单实现查询数据库的数据,当然查询不是这么用的。一般都是将查询的数据封装成为实例化对应,放到集合里面,通过response返回到前端。这里只是简单的实现,证明能够成功查询而已。