第七章 MapReduce详解
MapReduce是一种并行编程模型,用于大规模数据集(大于1TB)的并行计算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象为两个函数:Map和Reduce。
MapReduce是单输入、两阶段、粗粒度数据并行、分布式计算框架。
适合用MapReduce来处理的数据集要满足一个前提条件:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
MapReduce实现离线批处理
Impala实现实时交互查询分析
Storm实现流式数据实时分析
Spark实现迭代计算
并发、并行与分布式编程的概念区分
并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。并发是一次处理很多事情,并行是同时做很多事情。
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。就好像两个人各拿一把铁锨在挖坑,一小时后,每人一个大坑。所以无论从微观还是从宏观来看,二者都是一起执行的。
当系统有一个以上CPU时,则线程的操作有可能非并发,当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
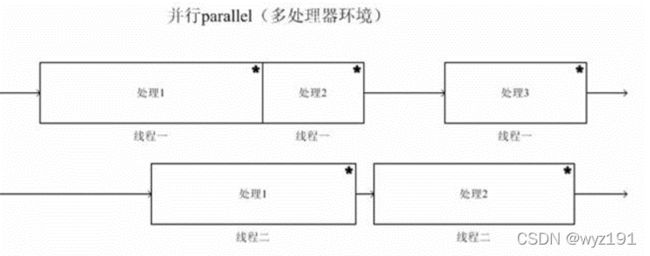
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。这就好像两个人用同一把铁锨,轮流挖坑,一小时后,两个人各挖一个小一点的坑,要想挖两个大一点得坑,一定会用两个小时。

当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状态,这种方式我们称之为并发(Concurrent)。
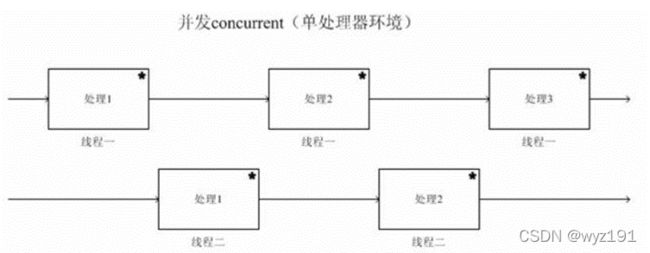
并行在多处理器系统中存在,而并发可以在单处理器和多处理器系统中都存在,并发能够在单处理器系统中存在是因为并发是并行的假象,并行要求程序能够同时执行多个操作,而并发只是要求程序假装同时执行多个操作(每个小时间片执行一个操作,多个操作快速切换执行)。
“摩尔定律”,CPU的性能大约每隔18个月性能翻一翻。从2005年开始摩尔定律逐渐失效。人们开始借助于分布式编程来提高程序的性能。分布式程序运行在大规模计算机集群上,集群中包括大量廉价服务器,可以并行执行大规模数据处理任务,从而获得少量的计算能力。
分布式并行编程与传统的程序开发方式有很大的区别。传统的程序都以单指令、单数据流的方式顺序执行,这种程序的性能受到单台机器性能的限制,可扩展性较差。分布式并行程序可以运行在由大量计算机构成的集群上,从而可以充分利用集群的并行处理能力,同时通过向集群中增加新的计算节点,可以很容易地实现集群计算能力的扩充。
谷歌公司最先提出分布式并行编程模型MapReduce,Hadoop MapReduce是它的开源实现。谷歌的MapReduce运行在分布式文件系统GFS上。Hadoop MapReduce运行在分布式文件系统HDFS上。Hadoop MapReduce要比Google的MapReduce的使用门槛低很多。
| 传统并行计算框架 |
MapReduce |
|
| 集群架构/容错性 |
共享式(共享内存/共享存储)容错性差 |
非共享式,容错性好 |
| 硬件/价格/扩展性 |
刀片服务器、高速网、SAN,价格贵,扩展性差 |
普通PC机,便宜,扩展性好 |
| 适用场景 |
实时、细粒度计算、计算密集型 |
批处理、非实时、数据密集型 |
为什么要用MapReduce
1)海量数据在单机上处理因为硬件资源限制,无法胜任
2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
3)引入MapReduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
MapReduce的优缺点
MapReduce优点:
海量数据离线处理&易开发&易运行(易开发和易运行只是相对而言)
MapReduce缺点:
实时流式计算
实时:MapReduce的作业都是通过进程方式启动,必然速度会慢很多,不可能实时的把数据处理完,无法像MySQL一样,在毫秒级或者秒级内返回结果
流式:MapReduce的输入数据集是静态的,不能动态变化;MapReduce自身的设计特点决定了数据源必须是静态的。
MapReduce模型
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce,这两个函数及其核心思想都源自函数式编程语言。
MapReduce的核心思想可以用“分而治之”来描述,一个存储在分布式文件系统中的大规模数据集会被切分成许多独立的小数据集,这些小数据集可以被多个 Map任务并行处理。MapReduce框架会为每个Map任务输入一个小数据集(分片),Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”。因为,移动计算要比移动数据更加经济,只要有可能,MapReduce框架就会将Map程序就近地在HDFS数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少节点间的数据移动开销。
注意:适合用 MapReduce来处理的数据集需要满足一个前提条件“待处理的数据集可以分解成许多个小的数据集,而且每一个小数据集都可以完全并行地进行处理。”
Map和Reduce函数
MapReduce模型的核心是Map和Reduce函数,二者都是由应用程序开发者负责具体实现的。程序员只需要关注如何实现Map和Reduce函数,而不需要处理并行编程中的其他各种复杂问题。
Map和 Reduce函数都是以
| 函数 |
输入 |
输出 |
说明 |
| Map |
|
List( |
将小数据集(split)进一步解析成一批 每一个输入的 |
| Reduce |
|
|
输入的中间结果 |
Map函数的输入来自分布式文件系统的文件块。文件块是一系列任意类型的元素集合,同一个元素不能跨文件块存储。Map函数将输入的元素转换成
Reduce函数将输入的一系列具有相同键的键值对以某种方式组合起来,输出处理后的键值对,输出结果合并为一个文件。用户可以指定Reduce任务的个数,并通知实现系统。然后主控进程通常会选择一个Hash函数,Map任务输出的每个键都会经过Hash函数计算,并根据哈希结果将该键值对输入相应的Reduce任务来处理。
MapReduce的工作流程
工作流程概述
大规模数据集的处理方式包括分布式存储和分布式计算两个核心环节。Hadoop使用分布式文件系统HDFS实现分布式存储,用Hadoop MapReduce实现分布式计算。MapReduce的输入和输出都需要借助分布式文件系统进行存储,这些文件被分布存储到集群的多个节点上。
MapReduce的核心思想是“分而治之”,也就是把一个大的数据集拆分成多个小数据集在多台机器上并行处理。即一个大的MapReduce作业,首先会被拆分成多个Map任务在多台机器上并行处理,每个Map任务通常运行在数据存储的节点上(也就是所谓的:计算向数据靠拢)。这样计算和数据就可以放在一起运行,不需要额外的数据传输开销。当Map任务结束后,会生成以
注意:
不同的Map任务之间不会进行通信,不同的Reduce任务之间也不会发生任何信息交换;用户不能显式地从一台机器向另一台机器发送消息,所有的数据交换都是通过MapReduce框架自身去实现的。
整个执行过程中,Map任务的输入文件、Reduce任务的处理结果都是保存在分布式文件系统中的,而Map任务处理得到的中间结果保存在本地存储中。只有当Map处理全部结果后,Reduce过程才能开始;只有Map才需要考虑数据局部性,实现“计算向数据靠拢”,Reduce则无须考虑数据局部性。
各个执行阶段

1、数据预处理 - InputFormat
MapReduce框架使用InputFormat模块做Map前的预处理,比如验证输入的格式是否符合输入定义;将要进行计算的数据输出给Split
2、逻辑切分 - Split
MapReduce框架将输入文件切分为逻辑上的多个InputSplit。InputSplit是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit并没有对文件进行实际切分,只是记录了要处理的数据的位置和长度。将结果输出给RecordReader(RR)
3、转换成Map任务读取的
因为InputSplit是逻辑切分而非物理切分,所以还需要通过RecordReader(RR)根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并将其转换为适合Map任务读取的键值对,输出给Map。RecordReader读取切片中的每一条记录,按照记录格式读取,偏移值作为map的key,记录行作为value,当做map方法的参数。
key : 每一行行首字母的偏移量
value: 每一行数据
4、Map
根据用户自定义的映射规则,输出一系列的
将第三步生成的
---------------------------------------Map-------------------------------------
为了让Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区(Partition)、排序(Sort)、合并(Combine)、归并(Merge)等操作,得到
Shuffle是指对Map任务输出结果进行分区、排序、合并、归并等处理并交给Reduce的过程。Shuffle过程分为Map端的操作和Reduce端的操作。
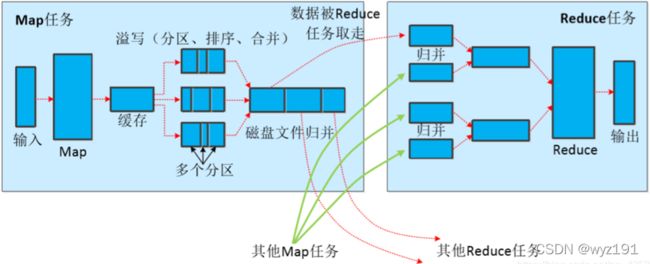
5、Shuffle
(1) 在Map端的Shuffle过程
Map任务的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要对缓存中的数据进行分区(默认的分区方式是先采用Hash函数对key进行哈希,再对Reduce任务的数量进行取模),然后对每个分区的数据进行排序(排序时先按照Partition进行排序,再按照key进行排序,默认排序算法是快速排序。 在内存中进行排序时,数据本身不用移动,仅对索引排序即可。)和合并,再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并成一个大的磁盘文件,然后通知相应的Reduce任务来“领取”属于自己处理的数据。
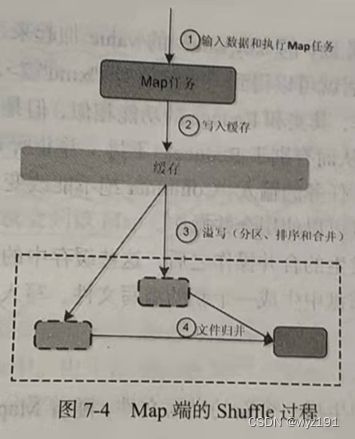
1)输入数据和执行Map任务
Map任务的输入数据一般保存在分布式文件系统的文件块中,这些文件块的格式是任意的,可以是文档格式,也可以是二进制格式。Map任务接收
2)写入缓存
每个Map任务都会被分配一个缓存,Map任务的输出结果首先写入缓存。在缓存中积累一定数量的Map任务输出结果以后,再一次性批量写入磁盘,这样可以大大减少对磁盘I/O的影响。注意:在写入缓存之前,key与value都会被序列化成字节数组。
3)溢写(分区、排序和合并)
提供给Map缓存的容量默认大小是100MB。随着Map任务的执行,缓存中Map任务结果的数量会不断增加,很快占满整个缓存。这时,就必须启动溢写(Spill)操作,把缓存中的内存一次性写入磁盘,并清空缓存。
溢写的过程通常是由另外一个单独的后台线程来完成的,不会影响Map结果往缓存写入。但是为了保证Map结果能够持续写入缓存,不受溢写过程的影响,就必须让缓存中一直有可用的空间,不能等到全部占满才启动溢写过程,所以一般会设置一个溢写比例,比如0.8。也就是说,当100MB大小的缓存被填入80MB数据时,就启动溢写过程,把已经写入的80MB数据写入磁盘,剩余20MB空间从给Map结果继续写入。
经过分区、排序以及可能发生的合并操作之后,缓存中的键值对可以被写入磁盘,并清空缓存。每次溢写操作都会在磁盘中生成一个新的溢写文件,写入溢写文件中的所有键值对都是经过分区和排序的。
- 分区Partition
按照一定的规则对
溢写到磁盘之前,缓存中的数据首先会被分区。缓存中的数据是
- 排序Sort
对每个分区内的数据进行排序。 输出给Shuffle(Combiner)
对于每个分区内的键值对,后台线程会根据key对它们进行内存排序,排序是MapReduce的默认操作。排序结束后,还有一个可选的合并操作。如果用户事先没有定义Combiner函数,就不用进行合并操作。如果用户事先定义了Combiner函数,则这个时候会执行合并操作,从而减少需要溢写到磁盘的数据量。
- 合并Combiner
在Map端进行局部聚合(汇总)目的是为了减少网络带宽的开销输出给Shuffle(Merge)
“合并”是指将那些具有相同key的
4)文件归并
将相同key的key提取出来作为唯一的key ,将相同key对应的value提取出来组装成一个value 的List 输出给Shuffle(reduce)
每次溢写操作都会在磁盘中生成一个新的溢写文件。最终,在Map任务全部结束之前,系统会对所有溢写文件中的数据进行归并,生成一个大的溢写文件,这个大的溢写文件中的所有键值对也是经过分区和排序的。
“归并”是指具有相同key的键值对会被归并成一个新的键值对。
另外,进行文件归并时,如果磁盘中已经生成的溢写文件的数量超过参数min.num.spills.for.combine的值时(默认值是3,用户可以修改),那么,就可以再次运行Combiner,对数据进行合并操作,从而减少写入磁盘的数据量。
Map端的Shuffle过程全部完成后,最终生成一个会被存放在本地磁盘上的大文件。这个大文件中的数据是被分区的,不同的分区会被发送到不同的Reduce任务进行并行处理。JobTracker会一直监测Map任务的执行,当监测到一个Map任务完成后,会立即通知相关的Reduce任务来“领取”数据,然后开始Reduce端的Shuffle过程。
(2)在Reduce端的Shuffle过程
Reduce任务从Map端的不同Map机器“领取”属于自己处理的那部分数据,然后对数据进行归并后交给Reduce处理。
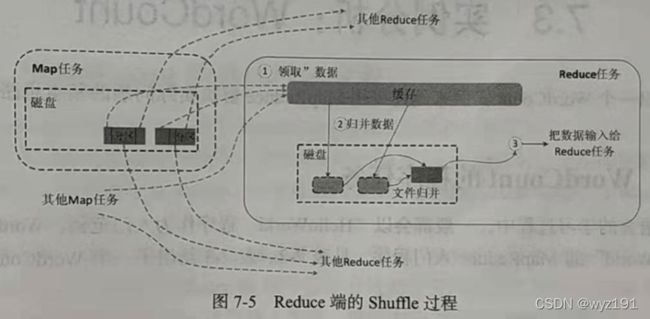
1)“领取”数据
Map端的Shuffle过程结束后,所有Map任务输出结果都保存在Map机器的本地磁盘上,每个Reduce任务会不断地通过RPC向JobTracker询问Map任务是否已经完成;JobTracker监测到一个Map任务完成后,就会通知相关的Reduct任务来“领取”数据,把这些数据“领取”(Fetch)回来后放到自己所在机器的本地磁盘上。一旦一个Reduce任务收到JobTracker的通知,它就会到该Map任务所在机器上把属于自己处理的分区数据领取到本地磁盘中。
2)归并数据
从Map端“领取”的数据会被存放在Reduce任务所在机器的缓存中,如果缓存占满,就会像Map端一样被溢写到磁盘中。由于在Shuffle阶段Reduce任务还没真正开始,因此,这时可以把内存的大部分空间分配给Shuffle过程作为缓存。需要注意的是,系统中一般存在多个Map机器,Reduce任务会从多个Map机器“领取”属于自己处理的那些分区的数据,因此缓存中的数据是来自不同的Map机器的,一般会存在很多可以合并的键值对。当溢写过程启动时,具有相同key的键值对会被归并,如果用户定义了Combiner,则归并后的数据还可以执行合并操作,减少写入磁盘的数据量。每个溢写过程结束后,都会在磁盘中生成一个溢写文件,因此,磁盘上会存在多个溢写文件。最终,当所有的Map端数据都已经被“领取”时,和Map端类似,多个溢写文件会被归并成一个大文件,归并的时候还会对键值对进行排序,从而使得最终大文件中的键值对都是有序的。当然,在数据很少的情形下,缓存可以存储所有数据,就不需要把数据溢写到磁盘,而是直接在内存中执行归并操作,然后直接输出给Reduce任务。需要说明的是,把磁盘上的多个溢写文件归并成一个大文件可能需要执行多轮归并操作。每轮归并操作可以归并的文件数量是由参数io.sort.factor的值来控制的(默认值是10,用户可以修改)。假设磁盘中生成了50个溢写文件,每轮可以归并10个溢写文件,则需要5轮归并,得到5个归并后的大文件。
3)把数据输入给Reduce任务
磁盘中经过多轮归并后得到的若干个大文件,不会继续归并成一个新的大文件,而是直接输入Reduce任务,这样可以减少磁盘读写开销。由此,整个Shuffle过程顺利结束。接下来,Reduce任务会执行Reduce函数中定义的各种映射,输出最终结果,并将其保存到分布式文件系统中。
------------------------------------Shuffle------------------------------------
6、reduce
根据业务需求对传入的数据进行汇总计算。 输出给Shuffle(outputFormat)
7、outputFormat
将最终的额结果写入HDFS
------------------------------------reduce-------------------------------------
作业执行流程

一个MapReduce的作业执行流程是:
(1)代码编写
代码编写主要是编写我们需要的map函数和Reduce函数。
(2)作业配置
主要是指定将来执行任务的map函数和Reduce函数是哪个,是否需要对map函数的输出结果做处理等等,
(3)作业提交
主要是讲作业提交到Hadoop集群上进行处理
(4)Map任务的分配和执行
当作业提交给MapReduce框架(实际上是提交给了JobTracker)之后,并不是立刻就能够分配相关线程对对其进行处理,而是将作业放置到作业调度队列中,等待按照某种作业调度策略进行调度(如FIFO等),一旦获得调度,进行开始执行map任务。
(5)处理中间结果
(6)Reduce任务的分配与执行
执行Reduce任务分成三个阶段:shuffle阶段,merge阶段,Reduce函数处理阶段
1)shuffle阶段
Reduce启动一个复制线程,根据JobTracker传过来的地址,将对应的映射到自己任务上的数据复制过来
2)merge阶段
Reduce复制过来的数据会首先放入到内存缓冲区中,当缓冲区中的数据达到一定程度之后会进行内存缓冲区到本地磁盘的merge,实际上也是spill过程。
ps:实际上merge和shuffle是可以同时进行的,即边复制边merge。
3)Reduce处理
merge之后,会形成一个文件,这个文件可能存放在内存中(文件小),也可能存放在本地磁盘中(文件很大),文件中的数据形式为key-list对,这个文件就是作为reduce函数的输入,文件中有多少个key-list对,就执行多少次reduce函数。
(7)作业完成
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。