RCNN网络源码解读(Ⅳ) --- 训练SVM二分类模型的准备过程
目录
1.回忆上一讲及本讲我们要做什么
2.回顾finetune是怎么训练的(finetune.py)
3. 训练SVM二分类模型 (linear_svm.py)
3.1 load_data
3.2 custom_classifier_dataset.py
3.3 custom_batch_sampler.py
3.4 hinge_loss
1.回忆上一讲及本讲我们要做什么
每次我们取出来一个mini_batch= 128数量的数据进行了一个finetune训练,将选取的框体和真实的框体进行比对(IOU运算),取得了我认为它是汽车的一些图和认为他不是汽车的(局部或者不是汽车),目的是为了当我们观察到一辆汽车时保证我们把整个汽车都框下来当然汽车局部就是负例了,通过finetune训练我们希望电脑看到一个汽车整体的时候才是正例。
我们现在要做的是:
在使用finetune方法继承alexnet的网络模型和参数。(深度学习当中较为常用)做2分类,需要对2分类的数据集进行训练。获得了确定一张图像中是否有汽车的模型。在这个模型的基础上,进行svm二分类器的模型训练。
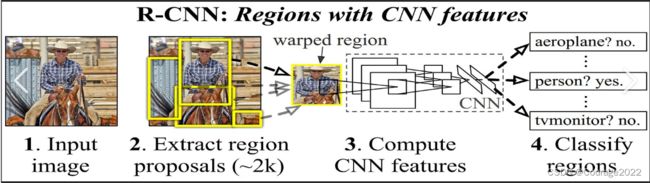
2.回顾finetune是怎么训练的(finetune.py)
from image_handler import show_images import numpy as np if __name__ == ' __main__': device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") data_loaders,data_sizes = load_data('./data/classifier_car') #加载alexnet神经网洛 model = models.alexnet(pretraine = True) print(model) data_loader = data_loaders["train"] print("一次迭代取得所有的正负数据,如果是多个类则取得多类数据集合") """ index: 323 inage_id: 200 target: 1 image.shape: (254,342,3)[xmin,ymin,xnax,ymax]: [80,39,422,293] """ inputs,targets = next(data_loader.__iter__()) print(inputs[0].size(),type(inputs[0])) trans = transforms.ToPILImage() print(type(trans(inputs[0]))) print(targets) print(inputs.shape) titles = ["TRUE" if i.item() else "False" for i in targets[0:60]] images = [np.array(trans(i))for i in inputs[0:60]] show_images(images,titles=titles,num_cols=12) # #把alexnet变成二分类模型,在最后一行改为2分类。 num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(num_features,2) print("记alexnet变成二分类模型,在最后一行改为2分类",model) model = model.to(device) criterion = nn.CrossEntroyLoss() optimizer = optim.SGD(model.parameters(),lr=1e-3, momentum=0.9) lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=7,gamma=0.1) best_model = train_model(data_loaders,model,criterion,optimizer,lr_scheduler,device=device num_epachs=10) check_dir('./models') torch.save(best_model.state_dict(),'models/alexnet_car.pth ')①指定设备
②读取数据,建立数据的迭代器
③加载alexnet神经网络
④alexnet变成二分类模型,在最后一行改为2分类。
⑤指定好参数进行训练
⑥保存训练模型
3. 训练SVM二分类模型 (linear_svm.py)
我们发现有几点不同:
①加载模型的时候缺少了pretrain=true选项,因为我们要加载我们上一步训练好的finetune的模型。
②固定特征提取(注释有标注)
import time import copy import os inport random import numpy as np inport torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision.transforms as transforms from torchvision.models import alexnet from utils.data.custom_classifier_dataset import CustomClassifierDataset from utils.data.custom_hard_negative_mining_dataset impont CustomHardNegativeNiningDatasetfrom utils.data.custom_batch_sampler import customBatchSampler from utils.util import check_dir from utils.util import save_model if __name__ == '__main__': device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') #dataloadr 有train val remain #dataloader是一个样本含有128(32+96)个框体的迭代器,这个迭代器含元素个数为data_size data_loaders,data_sizes = load_data("./data/classifier_car') #加载CNN模型 model_path = "./models/alexnet_car.pth' model = alexnet() #指定二分类 num_classes = 2 #将Alexnet的最后一层改成一个线性层(第六层):因为我们之前训练好的 #Alexnet最后一层是两个输出的,如果这里不改改网络结构的话那么我们模型加载不出来 num_features = model.classifier[6].in_features model.classifier[6] =nn.Linear(num_features,nun_classes) #将finetune模型训练好的数据加载进去 model.load_state_dict(torch.load(model_path)) #进入估算模式 model.eval() #固定特征提取:迁移学习 不取梯度了 for param in model.parameters(): param.requires_grad = False #创建SVM分类器:再将第六层设置为一个二分类 #那么最后一层的param.requires_grad = True model.classifier[6] = nn.Linear(num_features,nun_classes) #print(model) model = model.to(device) ##查看各层的训练情况:最后一次required_grad = true #for param in model.parameters(): # print(param,param.requires_grad) for name,param in model.named_parameters(): #查看可优化的参数有哪些 print(name,param.size(), param.requires.grad) criterion = hinge_loss #由于初始训练集数量很少,所以降低学习率 optimizer = optim.SGD(model.parameters(),lr=1e-4,momentum=0.9) #共训练10轮,每隔4论减少一次学习率 lr_schduler = optim.lr_scheduler.stepLR(optimizer,step_size=4,gamma=0.1) best_model = train_model(data_loaders,model,criterion,optimizer,1r_schduler,num_epochs=10,device=device) #保存最好的模型参数 save_model(best_model,'models/best_linear_svm_alexnet_car.pth')
3.1 load_data
我将讲解内容写在了代码注释里:
对于random那块代码,我们用一个简单的示例进行解释:
我们看一些random的细节 ,以正例的长度取负例的index值,大概取出来是[10,16,9,7,6,19]随机取的。
第二行代码的意思是在负例的idx中,如果这个idx属于[10,16,9,7,6,19]中,取出它的idx对应的负例数据
6 - 17 7 - 18 9 -20....
第三行将剩余的负例也打印出来了。
def load_data(data_root_dir): transform = transforms.Compose([ transforms.ToPILImage(), transforms. Resize((227,227)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) ]) data_loaders={} data_sizes = {} remain_negative_list = list() #我们进行完for循环 得到了一个数据样本 这个样本里面正例和负例的大小相等 for name in ['train', 'val']: data_dir = os.path.join(data_root_dir,name) #在后面的博客 #这个数据又三项组成:小图片,0/1,图片信息(rect框,归属于哪张大图片) data_set = CustomclassifierDataset(data_dir,transform=transform) if name is 'train': """ 使用hard negative mining方式 初始正负样本比例为1:1。由于正样本数远小于负样本,所以以正祥本数为基准,在负样本集中随机提取同样数目负样本作为初始负样本集,finetune中是32:96 """ #获取正例负例列表 (正向/负向框体信息 + 所属图片索引) positive_list = data_set.get_positives() negative_list = data_set.get_negatives() #finetune是取32:96的正负例样本,这里不一样!! #负例样本索引 init_negative_idxs =random.sample(range(len(negative_list)),len(positive_list)) #负例样本 init_negative_list = [negative_list[idx] for idx in range(len(negative_list)) if idx in init_negative_idxs] #剩余的负例样本 remain_negative_list = [negative_list[idx] for idx in range(len(negative_list)) if idx not in init_negative_idxs] #将数据集中的负例样本 = 正例样本 data_set.set_negative_list(init_negative_list) #remain表示剩余的负例 data_loaders['remain'] = remain_negative_list #sample是一个迭代器,含 iter_num * (32 + 96) 个样本 sampler = CustomBatchSampler(data_set.get_positive_num(),data_set.get_negative_num(),batch_positive,batch_negative) #迭代器 data_loader = DataLoader(data_set,batch_size=batch_total,sampler=sampler,num_workers=8,drop_last=True) #data_loader['train'] data_loader['val'] data_loaders[name] = data_loader #sample是一个迭代器,含 iter_num * (32 + 96) 个样本 data_sizes[name] = len(sampler) return data_loaders, data_sizes

3.2 custom_classifier_dataset.py
我将讲解内容写在了代码注释里:
@description:分类器数据集类,可进行正负样本替换,适用于hard negative mining操作 @[email protected] @2012/12/15 import numpy as np import os inport cv2 from PIL inport Image from torch.utils.data import Dataset from torch.utils.data import DataLoader import torchvision.transforms as transforms from .util import parse_car_csv class CustomclassifierDataset(Dataset): def __init__(self, root_dir,transform=None): #samples是图片名称 samples = parse_car_csv(root_dir) jpeg_images = list() positive_list = list() negative_list = list() #读取单张图像 for idx in range(len(samples)): #sample_name是一张图片的索引并在前面补0 sample_name = samples[idx] sample_name = sample_name.zfill(6) #把sample索引对应的jepg文件都出来了 jpeg_images.append(cv2.imread(os.path.join(root_dir,'JPEGImages',sample_name + ".jpg”))) #sample这张图片对应的正例框体的索引 positive_annotation_path = os.path.join(root_dir,'Annotations',sample_name + '_1.csv') positive_annotations = np.loadtxt(positive_annotation_path,dtype=np.int,delimiter=' ') #考虑csv文件为空或者仅包含单个标注框 if len(positive_annotations.shape) == 1: #单个标注框坐标,四个数就是rect if positive_annotations.shape[0] == 4: positive_dict = dict() #positive_annotation就是四个数字,idx是大图片的索引 positive_dict['rect'] = positive_annotations positive_dict['image_id'] = idx # positive_dict[ 'image_name' ] = sample_name #第几张图片的id是什么 positive_list.append(positive_dict) else: for positive_annotation in positive_annotations: positive_dict = dict() positive_dict['rect'] = positive_annotation positive_dict['image_id'] = idx # positive_dict['image_name'] = sample_name #positivelist里面存放的是 框体 + 图像索引 的列表 positive_list.append(positive_dict) nagative_annotation_path = os.path.join(root_dir,'Annotations',sample_name + '_0.csv') nagative_annotations = np.loadtxt(positive_annotation_path,dtype=np.int,delimiter=' ') #考虑csv文件为空或者仅包含单个标注框 if len(nagative_annotations.shape) == 1: #单个标注框坐标,四个数就是rect if nagative_annotations.shape[0] == 4: nagative_dict = dict() #nagative_annotation就是四个数字,idx是大图片的索引 nagative_dict['rect'] = nagative_annotations nagative_dict['image_id'] = idx # nagative_dict[ 'image_name' ] = sample_name #第几张图片的id是什么 nagative_list.append(positive_dict) else: for nagative_annotation in nagative_annotations: nagative_dict = dict() nagative_dict['rect'] = nagative_annotation nagative_dict['image_id'] = idx # nagative_dict['image_name'] = sample_name nagative_list.append(nagative_dict) self.transform = transform self.jpeg_images = jpeg_images self.positive_list = positive_list self.negative_list = negative_list def __getitem__(self,index:int): #定位下标所属图像 if index < len(self.positive_list): #正样本 target = 1 #positive_dict 是 正样本的一个框体的信息(框体 + 所属图片索引) positive_dict = self.positive_list[index] xmin, ynin,xmax,ymax = positive_dict['rect'] image_id = positive_dict['image_id'] image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax] #cache_dict是(框体信息 + 所属图片索引) cache_dict = positive_dict else: #负样本 target = 0 idx = index - len(self.positive_list) negative_dict = self.negative_list[idx] xmin,ymin,xmax,ynax = negative_dict['rect'] image_id = negative_dict['image_id'] image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax] cache_dict = negative_dict if self.transform: image = self.transform(image) #返回图片,0/1,以及图片信息(框体 + 所属图片索引) #返回 图片,0/1,(框体 + 所属图片索引) return image,target,cache_dict #正例和负例的框体总数 def __len__(self) -> int: return len(self.positive_list) + len(self.negative_list) def get_transform(self): return self.transform def get_jpeg_images(self) ->list: return self.jpeg_images def get_positive_num(self) -> int: return len(self.positive_list) def get_negative_num(self) -> int: return len(self.negative_list) #返回(正向框体信息 + 所属图片索引)的列表 def get_positives(self) -> list: return self.positive_list def get_negatives(self) -> list: return self.negative_list #替换负样本 def set_negative_list(self, negative_list): self.negative_list = negative_list
3.3 custom_batch_sampler.py
我将讲解内容写在了代码注释里:
和finetune里面没什么区别。。。
这里返回num_iter个的128个数据(32+96)的迭代器。
class customBatchsampler(sampler): def __init__(self,num_positive,num_negative,batch_positive,batch_negative) >None: """ 2分类数据集 每次批量处理,其中batch_positive个正样本,batch_negative个负样本 @param num_positive:正样本数目 @param num_negative:负样本数目 @param batch_positive:单次正样本数 @param batch_negative:难次负样本数 """ self.num_positive = num_positive self.num_negative = num_negative self.batch_positive = batch_positive self.batch_negative = batch_negative length = num_positive + num_negative self.idx_list = list(range(length)) self.batch = batch_negative + batch_positive self.num_iter = length // self.batch def __iter__(self): sampler_list = list() for i in range(self.num_iter): """ 在self.idx_list的正向数据中取得32个数据 在反面数据中获取随机96个数据作为测试数据集合 """ tmp = np.concatenate( (random.sample(self.idx_list[:self.num_positive],self.batch_positive),random.sample(self.idx_list[self.num_positive:], self.batch_negative)) ) random.shuffle(tmp) sampler_list.extend(tmp) return iter(sampler_list) def __len__(self)-> int: return self.num_iter * self.batch def get_num_batch(self) -> int: return self.num_iter
3.4 hinge_loss
折页损失:
具体原理请参阅我的博客:
深度学习与计算机视觉---损失函数及优化
https://mp.csdn.net/mp_blog/creation/editor/128208185
def hinge_loss(outputs,labels): """ 折页损失计算 :param outputs:大小为(N,num_classes) :param labels:大小为(N) :return:损失值 面临多分类问题的时候,每个样本都经历svm计算在不同分类上的打分,其中每个样本的1oss计算方法如下 1、针对每个样本上对不同分类的分数,选择不是该样本真实分类上的分数和该样本真实分类上的分数进行比较,如果该分数1小于真实分类上的分数,则1oss为0. 2、反之,该样不的1oss 为该分数+1再减去该样本在真实分类上的分数, 3、对所有的样本都按照此方法进行计算得到每个样本的LoSS,然后将它们加在一起凑成总loss值,并除以样本数以求平均。Li= Σ(0 if yi>= j+1 else 1+j-yi)(j!=yi) """ num_labels = len(labels) corrects = outputs[range(num_labels),labels].unsqueeze(0).T #最大间隔 margin = 1.0 margins = outputs - corrects + margin loss = torch.sun(torch.max(margins,1)[0])/ len(labels) #正则化强度 reg = 1e-3 loss += reg * torch .sum(weight *t 2) return loss