Kafka 核心源码解读【一】--日志模块
文章目录
-
- 1 日志段:保存消息文件的对象是怎么实现的?
-
- 1.1 Kafka 日志结构概览
- 1.2 日志段代码解析
- 1.3 日志段类声明
- 1.4 append 方法
- 1.5 read 方法
- 1.6 recover 方法
- 1.7 总结
- 2 日志:日志究竟是如何加载日志段的?LOG对象常见操作
-
- 2.1 Log 源码结构
- 2.2 Log Class & Object
- 2.3 日志段加载总结
- 2.4 高水位管理操作
- 2.5 日志段管理
- 2.6 关键位移值管理
- 2.7 读写操作
- 2.9 LOG常见操作总结
- 3 索引:改进的二分查找算法在Kafka索引的应用
-
- 3.1 索引类图及源文件组织架构
- 3.2 写入索引项
- 3.3 查找索引项
- 3.4 二分查找算法
- 3.5 改进版二分查找算法
- 3.6 二分法查找索引总结
- 3.7 位移索引
-
- (1)索引项的定义
- (2)写入索引项
- 3.8 时间戳索
-
- (1)索引项的定义
- (2)写入索引项
- 3.9 位移索引和时间戳索引总结
1 日志段:保存消息文件的对象是怎么实现的?
今天,我们开始学习 Kafka 源代码分析的第一模块:日志(Log)、日志段(LogSegment)以及索引(Index)源码。
1.1 Kafka 日志结构概览
Kafka 日志在磁盘上的组织架构如下图所示:

日志是 Kafka 服务器端代码的重要组件之一,很多其他的核心组件都是以日志为基础的,比如后面要讲到的状态管理机和副本管理器等。
总的来说,Kafka 日志对象由多个日志段对象组成,而每个日志段对象会在磁盘上创建一组文件,包括消息日志文件(.log)、位移索引文件(.index)、时间戳索引文件(.timeindex)以及已中止(Aborted)事务的索引文件(.txnindex)。当然,如果你没有使用 Kafka 事务,已中止事务的索引文件是不会被创建出来的。图中的一串数字 0 是该日志段的起始位移值(Base Offset),也就是该日志段中所存的第一条消息的位移值。
一般情况下,一个 Kafka 主题有很多分区,每个分区就对应一个 Log 对象,在物理磁盘上则对应于一个子目录。比如你创建了一个双分区的主题 test-topic,那么,Kafka 在磁盘上会创建两个子目录:test-topic-0 和 test-topic-1。而在服务器端,这就是两个 Log 对象。每个子目录下存在多组日志段,也就是多组.log、.index、.timeindex 文件组合,只不过文件名不同,因为每个日志段的起始位移不同。
1.2 日志段代码解析
之前碰到过一个问题,当时,大面积日志段同时间切分,导致瞬时打满磁盘 I/O 带宽。最后在 LogSegment 的 shouldRoll 方法中找到了解决方案:设置 Broker 端参数 log.roll.jitter.ms 值大于 0,即通过给日志段切分执行时间加一个扰动值的方式,来避免大量日志段在同一时刻执行切分动作,从而显著降低磁盘 I/O。
日志段源码重点讲一下日志段类声明、append 方法、read 方法和 recover 方法。
你首先要知道的是,日志段源码位于 Kafka 的 core 工程下,具体文件位置是 core/src/main/scala/kafka/log/LogSegment.scala。实际上,所有日志结构部分的源码都在 core 的 kafka.log 包下。
该文件下定义了三个 Scala 对象:
- LogSegment class;
- LogSegment object;
- LogFlushStats object。LogFlushStats 结尾有个 Stats,它是做统计用的,主要负责为日志落盘进行计时。
我们主要关心的是 LogSegment class 和 object。在 Scala 语言里,在一个源代码文件中同时定义相同名字的 class 和 object 的用法被称为伴生(Companion)。Class 对象被称为伴生类,它和 Java 中的类是一样的;而 Object 对象是一个单例对象,用于保存一些静态变量或静态方法。如果用 Java 来做类比的话,我们必须要编写两个类才能实现,这两个类也就是 LogSegment 和 LogSegmentUtils。在 Scala 中,你直接使用伴生就可以了。
1.3 日志段类声明
下面,我分批次给出比较关键的代码片段,并对其进行解释。首先,我们看下 LogSegment 的定义:
class LogSegment private[log] (val log: FileRecords, // 实际保存 Kafka 消息的对象
val lazyOffsetIndex: LazyIndex[OffsetIndex], // 对应位移索引文件,延迟初始化
val lazyTimeIndex: LazyIndex[TimeIndex], // 对应时间戳索引文件,延迟初始化
val txnIndex: TransactionIndex, // 已中止事务索引文件
val baseOffset: Long, // 每个日志段对象的起始位移
val indexIntervalBytes: Int, // 控制日志段对象新增索引项的频率。默认每 4KB 的消息数据新增一条索引项
val rollJitterMs: Long, // rollJitterMs 是日志段对象新增倒计时的“扰动值”
val time: Time) extends Logging { // 用于统计计时的一个实现类
一个日志段包含消息日志文件、位移索引文件、时间戳索引文件、已中止事务索引文件等。这里的 FileRecords 就是实际保存 Kafka 消息的对象。lazyOffsetIndex、lazyTimeIndex 和 txnIndex 分别对应位移索引文件、时间戳索引文件、已中止事务索引文件。不过,在实现方式上,前两种使用了延迟初始化的原理,降低了初始化时间成本。
每个日志段对象保存自己的起始位移 baseOffset,你在磁盘上看到的文件名就是 baseOffset 的值。每个 LogSegment 对象实例一旦被创建,它的起始位移就是固定的了,不能再被更改。
indexIntervalBytes 值其实就是 Broker 端参数 log.index.interval.bytes 值,它控制了日志段对象新增索引项的频率。默认情况下,日志段至少新写入 4KB 的消息数据才会新增一条索引项。rollJitterMs 是日志段对象新增倒计时的“扰动值”。因为目前 Broker 端日志段新增倒计时是全局设置,这就是说,在未来的某个时刻可能同时创建多个日志段对象,这将极大地增加物理磁盘 I/O 压力。有了 rollJitterMs 值的干扰,每个新增日志段在创建时会彼此岔开一小段时间,这样可以缓解物理磁盘的 I/O 负载瓶颈。
最后的 time 参数,它就是用于统计计时的一个实现类。
下面我来说一些重要的方法。
对于一个日志段而言,最重要的方法就是写入消息和读取消息了,它们分别对应着源码中的 append 方法和 read 方法。另外,recover 方法同样很关键,它是 Broker 重启后恢复日志段的操作逻辑。
1.4 append 方法
我们先来看 append 方法,了解下写入消息的具体操作。
def append(largestOffset: Long, // 最大位移值
largestTimestamp: Long, // 最大时间戳
shallowOffsetOfMaxTimestamp: Long, // 最大时间戳对应消息的位移
records: MemoryRecords): Unit = { // 要写入的消息集合
if (records.sizeInBytes > 0) { // 1、判断该日志段是否为空
trace(s"Inserting ${records.sizeInBytes} bytes at end offset $largestOffset at position ${log.sizeInBytes} " +
s"with largest timestamp $largestTimestamp at shallow offset $shallowOffsetOfMaxTimestamp")
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
ensureOffsetInRange(largestOffset) // 2、确保输入参数最大位移值是合法的,就是看它与日志段起始位移的差值是否在整数范围内
// append the messages
val appendedBytes = log.append(records) // 3、调用FileRecords 的 append 方法执行真正的写入
trace(s"Appended $appendedBytes to ${log.file} at end offset $largestOffset")
// Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) { // 4、更新日志段的最大时间戳以及最大时间戳所属消息的位移值
maxTimestampAndOffsetSoFar = TimestampOffset(largestTimestamp, shallowOffsetOfMaxTimestamp)
}
// append an entry to the index (if needed)
if (bytesSinceLastIndexEntry > indexIntervalBytes) { // 5、更新索引项,已写入字节数超过了4KB后,新增索引项
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0 // 清空已写入字节数,以备下次重新累积计算
}
bytesSinceLastIndexEntry += records.sizeInBytes // 更新写入的字节数
}
}
下图展示了 append 方法的完整执行流程:

第一步:在源码中,首先调用 log.sizeInBytes 方法判断该日志段是否为空,如果是空的话, Kafka 需要记录要写入消息集合的最大时间戳,并将其作为后面新增日志段倒计时的依据。
第二步:代码调用 ensureOffsetInRange 方法确保输入参数最大位移值是合法的。那怎么判断是不是合法呢?标准就是看它与日志段起始位移的差值是否在整数范围内,即 largestOffset - baseOffset 的值是不是介于 [0,Int.MAXVALUE] 之间。在极个别的情况下,这个差值可能会越界,这时,append 方法就会抛出异常,阻止后续的消息写入。一旦你碰到这个问题,你需要做的是升级你的 Kafka 版本,因为这是由已知的 Bug 导致的。
第三步:待这些做完之后,append 方法调用 FileRecords 的 append 方法执行真正的写入。前面说过了,专栏后面我们会详细介绍 FileRecords 类。这里你只需要知道它的工作是将内存中的消息对象写入到操作系统的页缓存就可以了。
第四步:再下一步,就是更新日志段的最大时间戳以及最大时间戳所属消息的位移值属性。每个日志段都要保存当前最大时间戳信息和所属消息的位移信息。还记得 Broker 端提供定期删除日志的功能吗?比如我只想保留最近 7 天的日志,没错,当前最大时间戳这个值就是判断的依据;而最大时间戳对应的消息的位移值则用于时间戳索引项。虽然后面我会详细介绍,这里我还是稍微提一下:时间戳索引项保存时间戳与消息位移的对应关系。在这步操作中,Kafka 会更新并保存这组对应关系。
第五步:append 方法的最后一步就是更新索引项和写入的字节数了。我在前面说过,日志段每写入 4KB 数据就要写入一个索引项。当已写入字节数超过了 4KB 之后,append 方法会调用索引对象的 append 方法新增索引项,同时清空已写入字节数,以备下次重新累积计算。
1.5 read 方法
def read(startOffset: Long, // 要读取的第一条消息的位移
maxSize: Int, // 能读取的最大字节数
maxPosition: Long = size, // 能读到的最大文件位置
minOneMessage: Boolean = false): FetchDataInfo = { // 是否允许在消息体过大时至少返回第一条消息。
if (maxSize < 0)
throw new IllegalArgumentException(s"Invalid max size $maxSize for log read from segment $log")
val startOffsetAndSize = translateOffset(startOffset) // 1、定位要读取的起始文件位置, startOffset 仅仅是位移值,Kafka 根据索引信息找到对应的物理文件位置
// if the start position is already off the end of the log, return null
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position
val offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
// return a log segment but with zero size in the case below
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// calculate the length of the message set to read based on whether or not they gave us a maxOffset
val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize) // 2、计算要读取的总字节数,未min(maxSize, 本文件剩余的消息量)
FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize), // 3、调用 FileRecords 的 slice 方法,从指定位置读取指定大小的消息集合
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
read 方法接收 4 个输入参数。
- startOffset:要读取的第一条消息的位移;
- maxSize:能读取的最大字节数;
- maxPosition :能读到的最大文件位置;
- minOneMessage:是否允许在消息体过大时至少返回第一条消息。
前 3 个参数的含义很好理解,我重点说下第 4 个。当这个参数为 true 时,即使出现消息体字节数超过了 maxSize 的情形,read 方法依然能返回至少一条消息。引入这个参数主要是为了确保不出现消费饿死的情况。
下图展示了 read 方法的完整执行逻辑:

第一步:调用 translateOffset 方法定位要读取的起始文件位置 (startPosition)。输入参数 startOffset 仅仅是位移值,Kafka 需要根据索引信息找到对应的物理文件位置才能开始读取消息。
第二步:待确定了读取起始位置,日志段代码需要根据这部分信息以及 maxSize 和 maxPosition 参数共同计算要读取的总字节数。举个例子,假设 maxSize=100,maxPosition=300,startPosition=250,那么 read 方法只能读取 50 字节,因为 maxPosition - startPosition = 50。我们把它和 maxSize 参数相比较,其中的最小值就是最终能够读取的总字节数。
第三步:最后一步是调用 FileRecords 的 slice 方法,从指定位置读取指定大小的消息集合。
1.6 recover 方法
recover 方法用于恢复日志段。什么是恢复日志段呢?其实就是说, Broker 在启动时会从磁盘上加载所有日志段信息到内存中,并创建相应的 LogSegment 对象实例。在这个过程中,它需要执行一系列的操作。
def recover(producerStateManager: ProducerStateManager, leaderEpochCache: Option[LeaderEpochFileCache] = None): Int = {
offsetIndex.reset() // 1、清空索引文件
timeIndex.reset()
txnIndex.reset()
var validBytes = 0
var lastIndexEntry = 0
maxTimestampAndOffsetSoFar = TimestampOffset.Unknown
try {
for (batch <- log.batches.asScala) {
batch.ensureValid() // 2.1、效验消息集合,消息必须要符合 Kafka 定义的二进制格式
ensureOffsetInRange(batch.lastOffset) // 2.1、效验消息集合,最后一条消息的位移值不能越界,即它与日志段起始位移的差值必须是一个正整数值
// The max timestamp is exposed at the batch level, so no need to iterate the records
if (batch.maxTimestamp > maxTimestampSoFar) {
maxTimestampAndOffsetSoFar = TimestampOffset(batch.maxTimestamp, batch.lastOffset) // 2.2、更新最大时间戳以及所属消息的位移值
}
// Build offset index
if (validBytes - lastIndexEntry > indexIntervalBytes) { // 2.3、更新索引项
offsetIndex.append(batch.lastOffset, validBytes)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
lastIndexEntry = validBytes
}
validBytes += batch.sizeInBytes() // 2.4、更新总消息字节数
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) { // 2.5、更新事务Producer状态和Leader Epoch缓存
leaderEpochCache.foreach { cache =>
if (batch.partitionLeaderEpoch >= 0 && cache.latestEpoch.forall(batch.partitionLeaderEpoch > _))
cache.assign(batch.partitionLeaderEpoch, batch.baseOffset)
}
updateProducerState(producerStateManager, batch)
}
}
} catch {
case e@ (_: CorruptRecordException | _: InvalidRecordException) =>
warn("Found invalid messages in log segment %s at byte offset %d: %s. %s"
.format(log.file.getAbsolutePath, validBytes, e.getMessage, e.getCause))
}
val truncated = log.sizeInBytes - validBytes // 3、当前总字节数大于已读取字节数,日志段写入非法消息,需要执行截断操作
if (truncated > 0)
debug(s"Truncated $truncated invalid bytes at the end of segment ${log.file.getAbsoluteFile} during recovery")
log.truncateTo(validBytes)
offsetIndex.trimToValidSize()
// A normally closed segment always appends the biggest timestamp ever seen into log segment, we do this as well.
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar, skipFullCheck = true)
timeIndex.trimToValidSize()
truncated
}
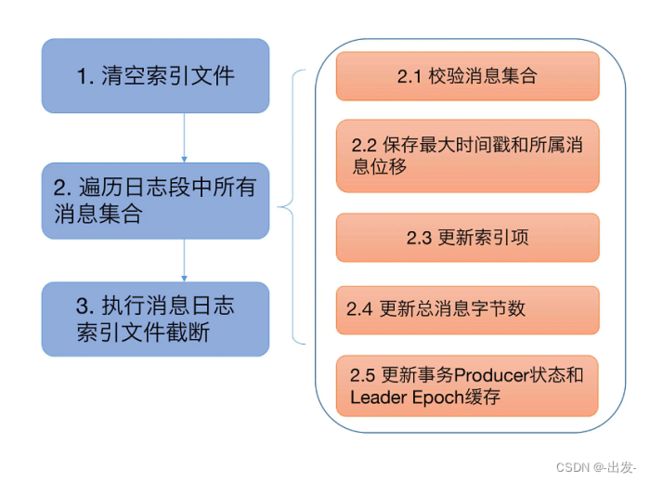
第一步:代码依次调用索引对象的 reset 方法清空所有的索引文件
第二步:遍历日志段中的所有消息集合或消息批次(RecordBatch)。对于读取到的每个消息集合,日志段必须要确保它们是合法的,这主要体现在两个方面:
- 该集合中的消息必须要符合 Kafka 定义的二进制格式;
- 该集合中最后一条消息的位移值不能越界,即它与日志段起始位移的差值必须是一个正整数值。
校验完消息集合之后,代码会更新遍历过程中观测到的最大时间戳以及所属消息的位移值。同样,这两个数据用于后续构建索引项。再之后就是不断累加当前已读取的消息字节数,并根据该值有条件地写入索引项。最后是更新事务型 Producer 的状态以及 Leader Epoch 缓存。不过,这两个并不是理解 Kafka 日志结构所必需的组件,因此,我们可以忽略它们。
第三步:遍历执行完成后,Kafka 会将日志段当前总字节数和刚刚累加的已读取字节数进行比较,如果发现前者比后者大,说明日志段写入了一些非法消息,需要执行截断操作,将日志段大小调整回合法的数值。同时, Kafka 还必须相应地调整索引文件的大小。把这些都做完之后,日志段恢复的操作也就宣告结束了。
1.7 总结
对 Kafka 日志段源码进行了重点的分析,包括日志段的 append 方法、read 方法和 recover 方法。
- append 方法:我重点分析了源码是如何写入消息到日志段的。你要重点关注一下写操作过程中更新索引的时机是如何设定的。
- read 方法:我重点分析了源码底层读取消息的完整流程。你要关注下 Kafka 计算待读取消息字节数的逻辑,也就是 maxSize、maxPosition 和 startOffset 是如何共同影响 read 方法的。
- recover 方法:这个操作会读取日志段文件,然后重建索引文件。再强调一下,这个操作在执行过程中要读取日志段文件。因此,如果你的环境上有很多日志段文件,你又发现 Broker 重启很慢,那你现在就知道了,这是因为 Kafka 在执行 recover 的过程中需要读取大量的磁盘文件导致的。你看,这就是我们读取源码的收获。

2 日志:日志究竟是如何加载日志段的?LOG对象常见操作
日志是日志段的容器,里面定义了很多管理日志段的操作。
2.1 Log 源码结构
Log 源码位于 Kafka core 工程的 log 源码包下,文件名是 Log.scala。总体上,该文件定义了 10 个类和对象,如下图所示:

图中括号里的 C 表示 Class,O 表示 Object。同时定义同名的 Class 和 Object,就属于 Scala 中的伴生对象用法。我们先来看伴生对象,也就是 LogAppendInfo、Log 和 RollParams。
1.LogAppendInfo
- LogAppendInfo(C):保存了一组待写入消息的各种元数据信息。比如,这组消息中第一条消息的位移值是多少、最后一条消息的位移值是多少;再比如,这组消息中最大的消息时间戳又是多少。总之,这里面的数据非常丰富(后面再具体说说)。
- LogAppendInfo(O): 可以理解为其对应伴生类的工厂方法类,里面定义了一些工厂方法,用于创建特定的 LogAppendInfo 实例。
2.Log
- Log(C): Log 源码中最核心的代码。一会儿细聊。
- Log(O):同理,Log 伴生类的工厂方法,定义了很多常量以及一些辅助方法。
3.RollParams
- RollParams(C):定义用于控制日志段是否切分(Roll)的数据结构。
- RollParams(O):同理,RollParams 伴生类的工厂方法。
除了这 3 组伴生对象之外,还有 4 类源码。
- LogMetricNames:定义了 Log 对象的监控指标。
- LogOffsetSnapshot:封装分区所有位移元数据的容器类。
- LogReadInfo:封装读取日志返回的数据及其元数据。
- CompletedTxn:记录已完成事务的元数据,主要用于构建事务索引。
2.2 Log Class & Object
先说说 Log 类及其伴生对象。考虑到伴生对象多用于保存静态变量和静态方法(比如静态工厂方法等),因此我们先看伴生对象(即 Log Object)的实现。毕竟,柿子先找软的捏!
object Log extends Logging {
val LogFileSuffix = ".log"
val IndexFileSuffix = ".index"
val TimeIndexFileSuffix = ".timeindex"
val ProducerSnapshotFileSuffix = ".snapshot"
val TxnIndexFileSuffix = ".txnindex"
val DeletedFileSuffix = ".deleted"
val CleanedFileSuffix = ".cleaned"
val SwapFileSuffix = ".swap"
val CleanShutdownFile = ".kafka_cleanshutdown"
val DeleteDirSuffix = "-delete"
val FutureDirSuffix = "-future"
...
}
这是 Log Object 定义的所有常量。如果有面试官问你 Kafka 中定义了多少种文件类型,你可以自豪地把这些说出来。耳熟能详的.log、.index、.timeindex 和.txnindex 我就不解释了,我们来了解下其他几种文件类型。
- .snapshot 是 Kafka 为幂等型或事务型 Producer 所做的快照文件。不详细展开。
- .deleted 是删除日志段操作创建的文件。目前删除日志段文件是异步操作,Broker 端把日志段文件从.log 后缀修改为.deleted 后缀。如果你看到一大堆.deleted 后缀的文件名,别慌,这是 Kafka 在执行日志段文件删除。
- .cleaned 和.swap 都是 Compaction 操作的产物,等我们讲到 Cleaner 的时候再说。
- -delete 则是应用于文件夹的。当你删除一个主题的时候,主题的分区文件夹会被加上这个后缀。
- -future 是用于变更主题分区文件夹地址的,属于比较高阶的用法。
Log Object 还定义了超多的工具类方法。由于它们都很简单,这里我只给出一个方法的源码,我们一起读一下。
def filenamePrefixFromOffset(offset: Long): String = {
val nf = NumberFormat.getInstance()
nf.setMinimumIntegerDigits(20) // 设置数字的整数部分中允许的最小位数
nf.setMaximumFractionDigits(0) // 设置数字的小数部分中允许的最大位数
nf.setGroupingUsed(false)
nf.format(offset)
}
这个方法的作用是通过给定的位移值计算出对应的日志段文件名。Kafka 日志文件固定是 20 位的长度,filenamePrefixFromOffset 方法就是用前面补 0 的方式,把给定位移值扩充成一个固定 20 位长度的字符串。举个例子,我们给定一个位移值是 12345,那么 Broker 端磁盘上对应的日志段文件名就应该是 00000000000000012345.log。
下面我们来看 Log 源码部分的重头戏:Log 类。这是一个 2000 多行的大类。放眼整个 Kafka 源码,像 Log 这么大的类也不多见,足见它的重要程度。我们先来看这个类的定义:
class Log(@volatile private var _dir: File,
@volatile var config: LogConfig,
@volatile var logStartOffset: Long,
@volatile var recoveryPoint: Long,
scheduler: Scheduler,
brokerTopicStats: BrokerTopicStats,
val time: Time,
val maxProducerIdExpirationMs: Int,
val producerIdExpirationCheckIntervalMs: Int,
val topicPartition: TopicPartition,
val producerStateManager: ProducerStateManager,
logDirFailureChannel: LogDirFailureChannel,
private val hadCleanShutdown: Boolean = true,
val keepPartitionMetadataFile: Boolean = true) extends Logging with KafkaMetricsGroup {
...
}
_dir 和 logStartOffset:_dir 就是这个日志所在的文件夹路径,也就是主题分区的路径。logStartOffset表示日志的当前最早位移。dir 和 logStartOffset 都是 volatile var 类型,表示它们的值是变动的,而且可能被多个线程更新。
你可能听过日志的当前末端位移,也就是 Log End Offset(LEO),它是表示日志下一条待插入消息的位移值,而这个 Log Start Offset 是跟它相反的,它表示日志当前对外可见的最早一条消息的位移值。我用一张图来标识它们的区别:
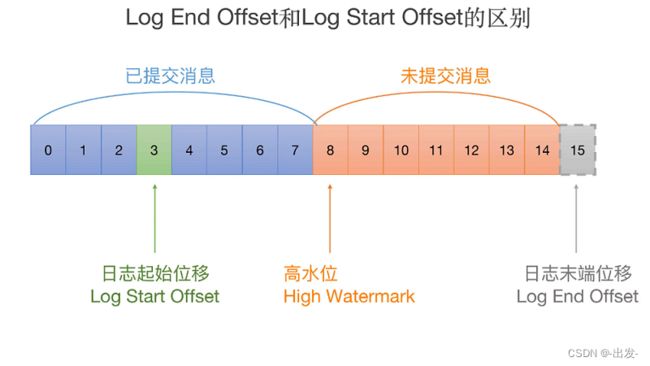
图中绿色的位移值 3 是日志的 Log Start Offset,而位移值 15 表示 LEO。另外,位移值 8 是高水位值,它是区分已提交消息和未提交消息的分水岭。
有意思的是,Log End Offset 可以简称为 LEO,但 Log Start Offset 却不能简称为 LSO。因为在 Kafka 中,LSO 特指 Log Stable Offset,属于 Kafka 事务的概念。这个课程中不会涉及 LSO,你只需要知道 Log Start Offset 不等于 LSO 即可。
Log 类的其他属性你暂时不用理会,因为它们要么是很明显的工具类属性,比如 timer 和 scheduler,要么是高阶用法才会用到的高级属性,比如 producerStateManager 和 logDirFailureChannel。工具类的代码大多是做辅助用的,跳过它们也不妨碍我们理解 Kafka 的核心功能;而高阶功能代码设计复杂,学习成本高,性价比不高。
除了 Log 类签名定义的这些属性之外,Log 类还定义了一些很重要的属性,比如下面这段代码:
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
@volatile var leaderEpochCache: Option[LeaderEpochFileCache] = None
nextOffsetMetadata:它封装了下一条待插入消息的位移值,你基本上可以把这个属性和 LEO 等同起来。
highWatermarkMetadata:是分区日志高水位值。
segments:Log 类中最重要的属性。它保存了分区日志下所有的日志段信息,只不过是用 Map 的数据结构来保存的。Map 的 Key 值是日志段的起始位移值,Value 则是日志段对象本身。Kafka 源码使用 ConcurrentNavigableMap 数据结构来保存日志段对象,就可以很轻松地利用该类提供的线程安全和各种支持排序的方法,来管理所有日志段对象。
leaderEpochCache:Leader Epoch 是社区于 0.11.0.0 版本引入源码中的,主要是用来判断出现 Failure 时是否执行日志截断操作(Truncation)。之前靠高水位来判断的机制,可能会造成副本间数据不一致的情形。这里的 Leader Epoch Cache 是一个缓存类数据,里面保存了分区 Leader 的 Epoch 值与对应位移值的映射关系,我建议你查看下 LeaderEpochFileCache 类,深入地了解下它的实现原理。
掌握了这些基本属性之后,我们看下 Log 类的初始化逻辑:
locally {
// create the log directory if it doesn't exist
Files.createDirectories(dir.toPath) // 1、创建分区日志路径法
initializeLeaderEpochCache() // 2、初始化leaderEpochCache
initializePartitionMetadata()
val nextOffset = loadSegments() // 3、加载所有的日志段对象
/* Calculate the offset of the next message */
nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)// 4、更新nextOffsetMetadata
leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))
updateLogStartOffset(math.max(logStartOffset, segments.firstEntry.getValue.baseOffset)) // 4、更新logStartOffset
// The earliest leader epoch may not be flushed during a hard failure. Recover it here.
leaderEpochCache.foreach(_.truncateFromStart(logStartOffset)) // 5、更新leader Epoch Cache
// Any segment loading or recovery code must not use producerStateManager, so that we can build the full state here
// from scratch.
if (!producerStateManager.isEmpty)
throw new IllegalStateException("Producer state must be empty during log initialization")
// Reload all snapshots into the ProducerStateManager cache, the intermediate ProducerStateManager used
// during log recovery may have deleted some files without the Log.producerStateManager instance witnessing the
// deletion.
producerStateManager.removeStraySnapshots(segments.values().asScala.map(_.baseOffset).toSeq)
loadProducerState(logEndOffset, reloadFromCleanShutdown = hadCleanShutdown)
// Delete partition metadata file if the version does not support topic IDs.
// Recover topic ID if present and topic IDs are supported
if (partitionMetadataFile.exists()) {
if (!keepPartitionMetadataFile)
partitionMetadataFile.delete()
else
topicId = partitionMetadataFile.read().topicId
}
}
在详细解释这段初始化代码之前,我使用一张图来说明它到底做了什么:

这里重点说说第三步,即加载日志段的实现逻辑,以下是 loadSegments 的实现代码:
private def loadSegments(): Long = {
// first do a pass through the files in the log directory and remove any temporary files
// and find any interrupted swap operations
val swapFiles = removeTempFilesAndCollectSwapFiles() //移除上次 Failure 遗留下来的临时文件
// Now do a second pass and load all the log and index files.
// We might encounter legacy log segments with offset overflow (KAFKA-6264). We need to split such segments. When
// this happens, restart loading segment files from scratch.
retryOnOffsetOverflow { // 清空所有日志段对象,重建日志段 segments Map 并删除无对应日志段文件的孤立索引文件
// In case we encounter a segment with offset overflow, the retry logic will split it after which we need to retry
// loading of segments. In that case, we also need to close all segments that could have been left open in previous
// call to loadSegmentFiles().
logSegments.foreach(_.close())
segments.clear()
loadSegmentFiles()
}
// Finally, complete any interrupted swap operations. To be crash-safe,
// log files that are replaced by the swap segment should be renamed to .deleted
// before the swap file is restored as the new segment file.
completeSwapOperations(swapFiles) // 完成未完成的 swap 操作
if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {
val nextOffset = retryOnOffsetOverflow {
recoverLog() // 恢复日志段对象
}
// reset the index size of the currently active log segment to allow more entries
activeSegment.resizeIndexes(config.maxIndexSize)
nextOffset
} else {
if (logSegments.isEmpty) {
addSegment(LogSegment.open(dir = dir,
baseOffset = 0,
config,
time = time,
initFileSize = this.initFileSize))
}
0
}
}
这段代码会对分区日志路径遍历两次。首先,它会移除上次 Failure 遗留下来的各种临时文件(包括 .cleaned、.swap、.deleted 文件等),removeTempFilesAndCollectSwapFiles 方法实现了这个逻辑。之后,它会清空所有日志段对象,并且再次遍历分区路径,重建日志段 segments Map 并删除无对应日志段文件的孤立索引文件。待执行完这两次遍历之后,它会完成未完成的 swap 操作,即调用 completeSwapOperations 方法。等这些都做完之后,再调用 recoverLog 方法恢复日志段对象,然后返回恢复之后的分区日志 LEO 值。如果你现在觉得有点蒙,也没关系,我把这段代码再进一步拆解下,以更小的粒度跟你讲下它们做了什么。理解了这段代码之后,你大致就能搞清楚大部分的分区日志操作了。所以,这部分代码绝对值得我们多花一点时间去学习。
首先来看第一步,removeTempFilesAndCollectSwapFiles 方法的实现。
private def removeTempFilesAndCollectSwapFiles(): Set[File] = {
// 在方法内部定义一个名为deleteIndicesIfExist的方法,用于删除日志文件对应的索引文件
def deleteIndicesIfExist(baseFile: File, suffix: String = ""): Unit = {
info(s"Deleting index files with suffix $suffix for baseFile $baseFile")
val offset = offsetFromFile(baseFile)
Files.deleteIfExists(Log.offsetIndexFile(dir, offset, suffix).toPath)
Files.deleteIfExists(Log.timeIndexFile(dir, offset, suffix).toPath)
Files.deleteIfExists(Log.transactionIndexFile(dir, offset, suffix).toPath)
}
val swapFiles = mutable.Set[File]()
val cleanFiles = mutable.Set[File]()
var minCleanedFileOffset = Long.MaxValue
// 遍历分区日志路径下的所有文件
for (file <- dir.listFiles if file.isFile) {
if (!file.canRead) // 如果不可读,直接抛出异常
throw new IOException(s"Could not read file $file")
val filename = file.getName
if (filename.endsWith(DeletedFileSuffix)) { // 如果以.deleted结尾
debug(s"Deleting stray temporary file ${file.getAbsolutePath}")
Files.deleteIfExists(file.toPath) // 说明上次Failure遗留下来的文件,直接删除
} else if (filename.endsWith(CleanedFileSuffix)) { // 如果以.cleaned结尾
minCleanedFileOffset = Math.min(offsetFromFileName(filename), minCleanedFileOffset)
cleanFiles += file
} else if (filename.endsWith(SwapFileSuffix)) { // // 如果以.swap结尾
// we crashed in the middle of a swap operation, to recover:
// if a log, delete the index files, complete the swap operation later
// if an index just delete the index files, they will be rebuilt
val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))
info(s"Found file ${file.getAbsolutePath} from interrupted swap operation.")
if (isIndexFile(baseFile)) { // 如果该.swap文件原来是索引文件
deleteIndicesIfExist(baseFile) // 删除原来的索引文件
} else if (isLogFile(baseFile)) { // 如果该.swap文件原来是日志文件
deleteIndicesIfExist(baseFile) // 删除掉原来的索引文件
swapFiles += file // 加入待恢复的.swap文件集合中
}
}
}
// 从待恢复swap集合中找出那些起始位移值大于minCleanedFileOffset值的文件,直接删掉这些无效的.swap文件
// KAFKA-6264: Delete all .swap files whose base offset is greater than the minimum .cleaned segment offset. Such .swap
// files could be part of an incomplete split operation that could not complete. See Log#splitOverflowedSegment
// for more details about the split operation.
val (invalidSwapFiles, validSwapFiles) = swapFiles.partition(file => offsetFromFile(file) >= minCleanedFileOffset)
invalidSwapFiles.foreach { file =>
debug(s"Deleting invalid swap file ${file.getAbsoluteFile} minCleanedFileOffset: $minCleanedFileOffset")
val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))
deleteIndicesIfExist(baseFile, SwapFileSuffix)
Files.deleteIfExists(file.toPath)
}
// Now that we have deleted all .swap files that constitute an incomplete split operation, let's delete all .clean files
// 清除所有待删除文件集合中的文件
cleanFiles.foreach { file =>
debug(s"Deleting stray .clean file ${file.getAbsolutePath}")
Files.deleteIfExists(file.toPath)
}
// 最后返回当前有效的.swap文件集合
validSwapFiles
}
执行完了 removeTempFilesAndCollectSwapFiles 逻辑之后,源码开始清空已有日志段集合,并重新加载日志段文件。这就是第二步。这里调用的主要方法是 loadSegmentFiles。
private def loadSegmentFiles(): Unit = {
// load segments in ascending order because transactional data from one segment may depend on the
// segments that come before it
// 按照日志段文件名中的位移值正序排列,然后遍历每个文件
for (file <- dir.listFiles.sortBy(_.getName) if file.isFile) {
if (isIndexFile(file)) { // 如果是索引文件
// if it is an index file, make sure it has a corresponding .log file
val offset = offsetFromFile(file)
val logFile = Log.logFile(dir, offset)
if (!logFile.exists) { // 确保存在对应的日志文件,否则记录一个警告,并删除该索引文件
warn(s"Found an orphaned index file ${file.getAbsolutePath}, with no corresponding log file.")
Files.deleteIfExists(file.toPath)
}
} else if (isLogFile(file)) { // 如果是日志文件
// if it's a log file, load the corresponding log segment
val baseOffset = offsetFromFile(file)
val timeIndexFileNewlyCreated = !Log.timeIndexFile(dir, baseOffset).exists()
// 创建对应的LogSegment对象实例,并加入segments中
val segment = LogSegment.open(dir = dir,
baseOffset = baseOffset,
config,
time = time,
fileAlreadyExists = true)
try segment.sanityCheck(timeIndexFileNewlyCreated)
catch {
case _: NoSuchFileException =>
error(s"Could not find offset index file corresponding to log file ${segment.log.file.getAbsolutePath}, " +
"recovering segment and rebuilding index files...")
recoverSegment(segment)
case e: CorruptIndexException =>
warn(s"Found a corrupted index file corresponding to log file ${segment.log.file.getAbsolutePath} due " +
s"to ${e.getMessage}}, recovering segment and rebuilding index files...")
recoverSegment(segment)
}
addSegment(segment)
}
}
}
第三步是处理第一步返回的有效.swap 文件集合。completeSwapOperations 方法就是做这件事的:
private def completeSwapOperations(swapFiles: Set[File]): Unit = {
// 遍历所有有效.swap文件
for (swapFile <- swapFiles) {
val logFile = new File(CoreUtils.replaceSuffix(swapFile.getPath, SwapFileSuffix, ""))
val baseOffset = offsetFromFile(logFile) // 拿到日志文件的起始位移值
// 创建对应的LogSegment实例
val swapSegment = LogSegment.open(swapFile.getParentFile,
baseOffset = baseOffset,
config,
time = time,
fileSuffix = SwapFileSuffix)
info(s"Found log file ${swapFile.getPath} from interrupted swap operation, repairing.")
// 执行日志段恢复操作
recoverSegment(swapSegment)
// We create swap files for two cases:
// (1) Log cleaning where multiple segments are merged into one, and
// (2) Log splitting where one segment is split into multiple.
//
// Both of these mean that the resultant swap segments be composed of the original set, i.e. the swap segment
// must fall within the range of existing segment(s). If we cannot find such a segment, it means the deletion
// of that segment was successful. In such an event, we should simply rename the .swap to .log without having to
// do a replace with an existing segment.
// 确认之前删除日志段是否成功,是否还存在老的日志段文件
val oldSegments = logSegments(swapSegment.baseOffset, swapSegment.readNextOffset).filter { segment =>
segment.readNextOffset > swapSegment.baseOffset
}
// 将生成的.swap文件加入到日志中,删除掉swap之前的日志段
replaceSegments(Seq(swapSegment), oldSegments.toSeq, isRecoveredSwapFile = true)
}
}
最后一步是 recoverLog 操作:
private[log] def recoverLog(): Long = {
/** return the log end offset if valid */
def deleteSegmentsIfLogStartGreaterThanLogEnd(): Option[Long] = {
// 这些都做完之后,如果日志段集合不为空
if (logSegments.nonEmpty) {
val logEndOffset = activeSegment.readNextOffset
if (logEndOffset >= logStartOffset) // 验证分区日志的LEO值不能小于Log Start Offset值,否则删除这些日志段对象
Some(logEndOffset)
else {
warn(s"Deleting all segments because logEndOffset ($logEndOffset) is smaller than logStartOffset ($logStartOffset). " +
"This could happen if segment files were deleted from the file system.")
removeAndDeleteSegments(logSegments, asyncDelete = true, LogRecovery)
leaderEpochCache.foreach(_.clearAndFlush())
producerStateManager.truncateFullyAndStartAt(logStartOffset)
None
}
} else None
}
// if we have the clean shutdown marker, skip recovery
// 如果不存在以.kafka_cleanshutdown结尾的文件。通常都不存在
if (!hadCleanShutdown) {
val unflushed = logSegments(this.recoveryPoint, Long.MaxValue).iterator
var truncated = false
while (unflushed.hasNext && !truncated) { // 遍历这些unflushed日志段
val segment = unflushed.next()
info(s"Recovering unflushed segment ${segment.baseOffset}")
val truncatedBytes =
try {
recoverSegment(segment, leaderEpochCache) // 执行恢复日志段操作
} catch {
case _: InvalidOffsetException =>
val startOffset = segment.baseOffset
warn("Found invalid offset during recovery. Deleting the corrupt segment and " +
s"creating an empty one with starting offset $startOffset")
segment.truncateTo(startOffset)
}
if (truncatedBytes > 0) { // 如果有无效的消息导致被截断的字节数不为0,直接删除剩余的日志段对象
// we had an invalid message, delete all remaining log
warn(s"Corruption found in segment ${segment.baseOffset}, truncating to offset ${segment.readNextOffset}")
removeAndDeleteSegments(unflushed.toList,
asyncDelete = true,
reason = LogRecovery)
truncated = true
}
}
}
val logEndOffsetOption = deleteSegmentsIfLogStartGreaterThanLogEnd()
// 这些都做完之后,如果日志段集合为空了
if (logSegments.isEmpty) {
// no existing segments, create a new mutable segment beginning at logStartOffset
// 至少创建一个新的日志段,以logStartOffset为日志段的起始位移,并加入日志段集合中
addSegment(LogSegment.open(dir = dir,
baseOffset = logStartOffset,
config,
time = time,
initFileSize = this.initFileSize,
preallocate = config.preallocate))
}
// Update the recovery point if there was a clean shutdown and did not perform any changes to
// the segment. Otherwise, we just ensure that the recovery point is not ahead of the log end
// offset. To ensure correctness and to make it easier to reason about, it's best to only advance
// the recovery point in flush(Long). If we advanced the recovery point here, we could skip recovery for
// unflushed segments if the broker crashed after we checkpoint the recovery point and before we flush the
// segment.
(hadCleanShutdown, logEndOffsetOption) match {
case (true, Some(logEndOffset)) =>
recoveryPoint = logEndOffset
logEndOffset
case _ =>
val logEndOffset = logEndOffsetOption.getOrElse(activeSegment.readNextOffset)
recoveryPoint = Math.min(recoveryPoint, logEndOffset) // 更新上次恢复点属性
logEndOffset
}
}
2.3 日志段加载总结
重点介绍 Kafka 的 Log 源码,主要包括:
- Log 文件的源码结构:你可以看下下面的导图,它展示了 Log 类文件的架构组成,你要重点掌握 Log 类及其相关方法。
- 加载日志段机制:我结合源码重点分析了日志在初始化时是如何加载日志段的。前面说过了,日志是日志段的容器,弄明白如何加载日志段是后续学习日志段管理的前提条件。

我一般习惯把 Log 的常见操作分为 4 大部分。
- 高水位管理操作:高水位的概念在 Kafka 中举足轻重,对它的管理,是 Log 最重要的功能之一。
- 日志段管理:Log 是日志段的容器。高效组织与管理其下辖的所有日志段对象,是源码要解决的核心问题。
- 关键位移值管理:日志定义了很多重要的位移值,比如 Log Start Offset 和 LEO 等。确保这些位移值的正确性,是构建消息引擎一致性的基础。
- 读写操作:所谓的操作日志,大体上就是指读写日志。读写操作的作用之大,不言而喻。
2.4 高水位管理操作
在介绍高水位管理操作之前,我们先来了解一下高水位的定义。源码中日志对象定义高水位的语句只有一行:
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
这行语句传达了两个重要的事实:
-
高水位值是 volatile(易变型)的。因为多个线程可能同时读取它,因此需要设置成 volatile,保证内存可见性。另外,由于高水位值可能被多个线程同时修改,因此源码使用 Java Monitor 锁来确保并发修改的线程安全。
-
高水位值的初始值是 Log Start Offset 值。上节课我们提到,每个 Log 对象都会维护一个 Log Start Offset 值。当首次构建高水位时,它会被赋值成 Log Start Offset 值。
你可能会关心 LogOffsetMetadata 是什么对象。因为它比较重要,我们一起来看下这个类的定义:
case class LogOffsetMetadata(messageOffset: Long,
segmentBaseOffset: Long = Log.UnknownOffset,
relativePositionInSegment: Int = LogOffsetMetadata.UnknownFilePosition) {
它就是一个 POJO 类,里面保存了三个重要的变量。
- messageOffset:消息位移值,这是最重要的信息。我们总说高水位值,其实指的就是这个变量的值。
- segmentBaseOffset:保存该位移值所在日志段的起始位移。日志段起始位移值辅助计算两条消息在物理磁盘文件中位置的差值,即两条消息彼此隔了多少字节。这个计算有个前提条件,即两条消息必须处在同一个日志段对象上,不能跨日志段对象。否则它们就位于不同的物理文件上,计算这个值就没有意义了。这里的 segmentBaseOffset,就是用来判断两条消息是否处于同一个日志段的。
- relativePositionSegment:保存该位移值所在日志段的物理磁盘位置。这个字段在计算两个位移值之间的物理磁盘位置差值时非常有用。你可以想一想,Kafka 什么时候需要计算位置之间的字节数呢?答案就是在读取日志的时候。假设每次读取时只能读 1MB 的数据,那么,源码肯定需要关心两个位移之间所有消息的总字节数是否超过了 1MB。
LogOffsetMetadata 类的所有方法,都是围绕这 3 个变量展开的工具辅助类方法,非常容易理解。我会给出一个方法的详细解释,剩下的你可以举一反三。
def onSameSegment(that: LogOffsetMetadata): Boolean = {
if (messageOffsetOnly)
throw new KafkaException(s"$this cannot compare its segment info with $that since it only has message offset info")
this.segmentBaseOffset == that.segmentBaseOffset
}
这个方法就是用来判断给定的两个 LogOffsetMetadata 对象是否处于同一个日志段的。判断方法很简单,就是比较两个 LogOffsetMetadata 对象的 segmentBaseOffset 值是否相等。
我们接着说回高水位,你要重点关注下获取和设置高水位值、更新高水位值,以及读取高水位值的方法。获取和设置高水位值
2.5 日志段管理
日志是日志段的容器
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
可以看到,源码使用 Java 的 ConcurrentSkipListMap 类来保存所有日志段对象。ConcurrentSkipListMap 有 2 个明显的优势。
-
它是线程安全的,这样 Kafka 源码不需要自行确保日志段操作过程中的线程安全;
-
它是键值(Key)可排序的 Map。Kafka 将每个日志段的起始位移值作为 Key,这样一来,我们就能够很方便地根据所有日志段的起始位移值对它们进行排序和比较,同时还能快速地找到与给定位移值相近的前后两个日志段。
所谓的日志段管理,无非是增删改查。接下来,我们就从这 4 个方面一一来看下。
- 增加
Log 对象中定义了添加日志段对象的方法:addSegment。
def addSegment(segment: LogSegment): LogSegment = this.segments.put(segment.baseOffset, segment)
很简单吧,就是调用 Map 的 put 方法将给定的日志段对象添加到 segments 中。
- 删除
删除操作相对来说复杂一点。我们知道 Kafka 有很多留存策略,包括基于时间维度的、基于空间维度的和基于 Log Start Offset 维度的。那啥是留存策略呢?其实,它本质上就是根据一定的规则决定哪些日志段可以删除。从源码角度来看,Log 中控制删除操作的总入口是 deleteOldSegments 无参方法:
def deleteOldSegments(): Int = {
if (config.delete) {
deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments()
} else {
deleteLogStartOffsetBreachedSegments()
}
}
下面这张图展示了 Kafka 当前的三种日志留存策略,以及底层涉及到日志段删除的所有方法:

从图中我们可以知道,上面 3 个留存策略方法底层都会调用带参数版本的 deleteOldSegments 方法,而这个方法又相继调用了 deletableSegments 和 deleteSegments 方法。下面,我们来深入学习下这 3 个方法的代码。
首先是带参数版的 deleteOldSegments 方法:
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean,
reason: SegmentDeletionReason): Int = {
lock synchronized {
val deletable = deletableSegments(predicate)
if (deletable.nonEmpty)
deleteSegments(deletable, reason)
else
0
}
}
该方法只有两个步骤:
- 使用传入的函数计算哪些日志段对象能够被删除;
- 调用 deleteSegments 方法删除这些日志段。
接下来是 deletableSegments 方法,我用注释的方式来解释下主体代码含义:
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = {
if (segments.isEmpty) { // 如果当前压根就没有任何日志段对象,直接返回
Seq.empty
} else {
val deletable = ArrayBuffer.empty[LogSegment]
var segmentEntry = segments.firstEntry
// 从具有最小起始位移值的日志段对象开始遍历,直到满足以下条件之一便停止遍历:
// 1. 测定条件函数predicate = false
// 2. 扫描到包含Log对象高水位值所在的日志段对象
// 3. 最新的日志段对象不包含任何消息
// 最新日志段对象是segments中Key值最大对应的那个日志段,也就是我们常说的Active Segment。完全为空的Active Segment如果被允许删除,后面还要重建它,故代码这里不允许删除大小为空的Active Segment。
// 在遍历过程中,同时不满足以上3个条件的所有日志段都是可以被删除的!
while (segmentEntry != null) {
val segment = segmentEntry.getValue
val nextSegmentEntry = segments.higherEntry(segmentEntry.getKey)
val (nextSegment, upperBoundOffset, isLastSegmentAndEmpty) = if (nextSegmentEntry != null)
(nextSegmentEntry.getValue, nextSegmentEntry.getValue.baseOffset, false)
else
(null, logEndOffset, segment.size == 0)
if (highWatermark >= upperBoundOffset && predicate(segment, Option(nextSegment)) && !isLastSegmentAndEmpty) {
deletable += segment
segmentEntry = nextSegmentEntry
} else {
segmentEntry = null
}
}
deletable
}
}
最后是 deleteSegments 方法,这个方法执行真正的日志段删除操作。
private def deleteSegments(deletable: Iterable[LogSegment], reason: SegmentDeletionReason): Int = {
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
val numToDelete = deletable.size
if (numToDelete > 0) {
// we must always have at least one segment, so if we are going to delete all the segments, create a new one first
// 不允许删除所有日志段对象。如果一定要做,先创建出一个新的来,然后再把前面N个删掉
if (segments.size == numToDelete)
roll()
lock synchronized {
checkIfMemoryMappedBufferClosed()
// remove the segments for lookups
// 删除给定的日志段对象以及底层的物理文件
removeAndDeleteSegments(deletable, asyncDelete = true, reason)
// 尝试更新日志的Log Start Offset值
maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset, SegmentDeletion)
}
}
numToDelete
}
}
这里我稍微解释一下,为什么要在删除日志段对象之后,尝试更新 Log Start Offset 值。Log Start Offset 值是整个 Log 对象对外可见消息的最小位移值。如果我们删除了日志段对象,很有可能对外可见消息的范围发生了变化,自然要看一下是否需要更新 Log Start Offset 值。这就是 deleteSegments 方法最后要更新 Log Start Offset 值的原因。
- 修改
说完了日志段删除,接下来我们来看如何修改日志段对象
其实,源码里面不涉及修改日志段对象,所谓的修改或更新也就是替换而已,用新的日志段对象替换老的日志段对象。举个简单的例子。segments.put(1L, newSegment) 语句在没有 Key=1 时是添加日志段,否则就是替换已有日志段。
- 查询
最后再说下查询日志段对象。源码中需要查询日志段对象的地方太多了,但主要都是利用了 ConcurrentSkipListMap 的现成方法。
- segments.firstEntry:获取第一个日志段对象;
- segments.lastEntry:获取最后一个日志段对象,即 Active Segment;
- segments.higherEntry:获取第一个起始位移值≥给定 Key 值的日志段对象;
- segments.floorEntry:获取最后一个起始位移值≤给定 Key 值的日志段对象。
2.6 关键位移值管理
Log 对象维护了一些关键位移值数据,比如 Log Start Offset、LEO 等。其实,高水位值也算是关键位移值,只不过它太重要了,所以,我单独把它拎出来作为独立的一部分来讲了。
还记得我上节课给你说的那张标识 LEO 和 Log Start Offset 的图吗?我再来借助这张图说明一下这些关键位移值的区别:
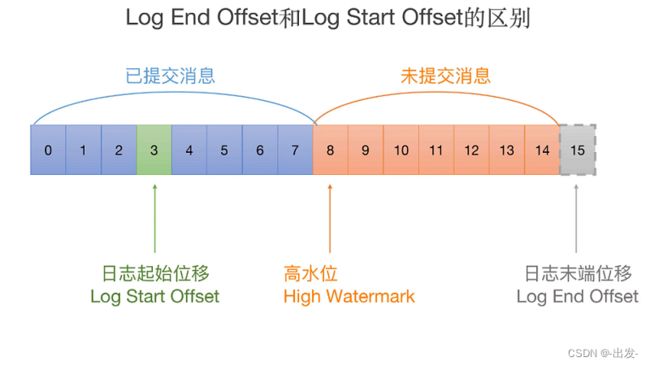
请注意这张图中位移值 15 的虚线方框。这揭示了一个重要的事实:Log 对象中的 LEO 永远指向下一条待插入消息,也就是说,LEO 值上面是没有消息的!源码中定义 LEO 的语句很简单:
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
这里的 nextOffsetMetadata 就是我们所说的 LEO,它也是 LogOffsetMetadata 类型的对象。Log 对象初始化的时候,源码会加载所有日志段对象,并由此计算出当前 Log 的下一条消息位移值。之后,Log 对象将此位移值赋值给 LEO,代码片段如下:
locally {
// 创建日志路径,保存Log对象磁盘文件
Files.createDirectories(dir.toPath)
// 初始化Leader Epoch缓存
initializeLeaderEpochCache()
// 加载所有日志段对象,并返回该Log对象下一条消息的位移值
val nextOffset = loadSegments()
// 初始化LEO元数据对象,LEO值为上一步获取的位移值,起始位移值是Active Segment的起始位移值,日志段大小是Active Segment的大小
nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)
// 更新Leader Epoch缓存,去除LEO值之上的所有无效缓存项
leaderEpochCache.foreach(
_.truncateFromEnd(nextOffsetMetadata.messageOffset))
......
}
当然,代码中单独定义了更新 LEO 的 updateLogEndOffset 方法:
private def updateLogEndOffset(offset: Long): Unit = {
nextOffsetMetadata = LogOffsetMetadata(offset, activeSegment.baseOffset, activeSegment.size)
if (highWatermark >= offset) {
updateHighWatermarkMetadata(nextOffsetMetadata)
}
if (this.recoveryPoint > offset) {
this.recoveryPoint = offset
}
}
如果在更新过程中发现新 LEO 值小于高水位值,那么 Kafka 还要更新高水位值,因为对于同一个 Log 对象而言,高水位值是不能越过 LEO 值的。这一点一定要切记!
实际上,LEO 对象被更新的时机有 4 个。
- Log 对象初始化时:当 Log 对象初始化时,我们必须要创建一个 LEO 对象,并对其进行初始化。
- 写入新消息时:这个最容易理解。以上面的图为例,当不断向 Log 对象插入新消息时,LEO 值就像一个指针一样,需要不停地向右移动,也就是不断地增加。
- Log 对象发生日志切分(Log Roll)时:日志切分是啥呢?其实就是创建一个全新的日志段对象,并且关闭当前写入的日志段对象。这通常发生在当前日志段对象已满的时候。一旦发生日志切分,说明 Log 对象切换了 Active Segment,那么,LEO 中的起始位移值和段大小数据都要被更新,因此,在进行这一步操作时,我们必须要更新 LEO 对象。
- **日志截断(Log Truncation)时:**这个也是显而易见的。日志中的部分消息被删除了,自然可能导致 LEO 值发生变化,从而要更新 LEO 对象。
说完了 LEO,我再跟你说说 Log Start Offset。其实,就操作的流程和原理而言,源码管理 Log Start Offset 的方式要比 LEO 简单,因为 Log Start Offset 不是一个对象,它就是一个长整型的值而已。代码定义了专门的 updateLogStartOffset 方法来更新它。该方法很简单,我就不详细说了,你可以自己去学习下它的实现。
现在,我们再来思考一下,Kafka 什么时候需要更新 Log Start Offset 呢?我们一一来看下。
- Log 对象初始化时:和 LEO 类似,Log 对象初始化时要给 Log Start Offset 赋值,一般是将第一个日志段的起始位移值赋值给它。
- 日志截断时:同理,一旦日志中的部分消息被删除,可能会导致 Log Start Offset 发生变化,因此有必要更新该值。
- Follower 副本同步时:一旦 Leader 副本的 Log 对象的 Log Start Offset 值发生变化。为了维持和 Leader 副本的一致性,Follower 副本也需要尝试去更新该值。
- 删除日志段时:这个和日志截断是类似的。凡是涉及消息删除的操作都有可能导致 Log Start Offset 值的变化。
- 删除消息时:严格来说,这个更新时机有点本末倒置了。在 Kafka 中,删除消息就是通过抬高 Log Start Offset 值来实现的,因此,删除消息时必须要更新该值。
2.7 读写操作
最后,我重点说说针对 Log 对象的读写操作。
- 写操作
在 Log 中,涉及写操作的方法有 3 个:appendAsLeader、appendAsFollower 和 append。它们的调用关系如下图所示:
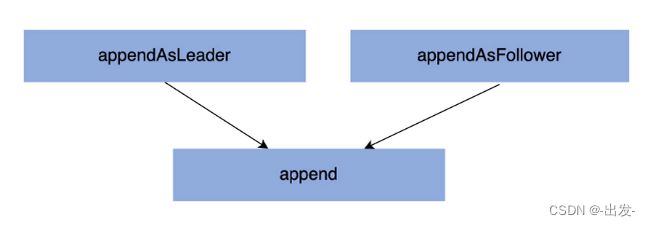
appendAsLeader 是用于写 Leader 副本的,appendAsFollower 是用于 Follower 副本同步的。它们的底层都调用了 append 方法。
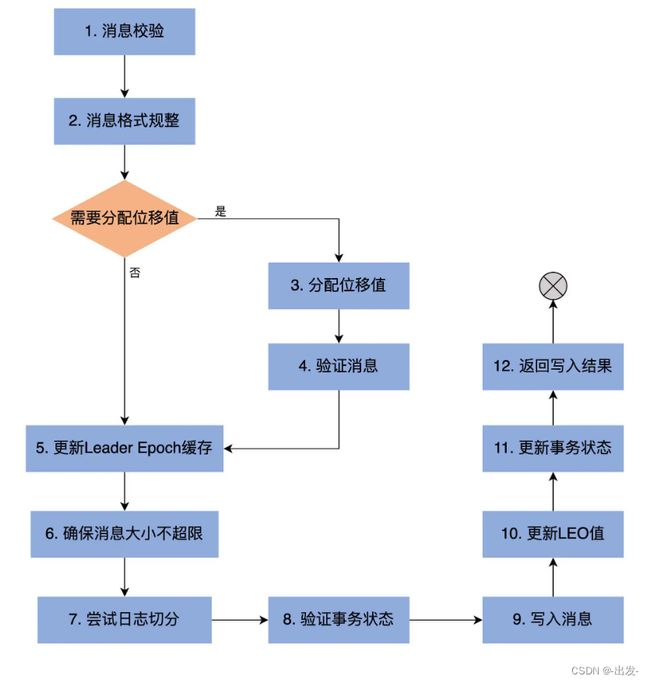
我们重点学习下 append 方法。下图是 append 方法的执行流程:
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
validateAndAssignOffsets: Boolean,
leaderEpoch: Int,
ignoreRecordSize: Boolean): LogAppendInfo = {
// We want to ensure the partition metadata file is written to the log dir before any log data is written to disk.
// This will ensure that any log data can be recovered with the correct topic ID in the case of failure.
maybeFlushMetadataFile()
// 第1步:分析和验证待写入消息集合,并返回校验结果
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize, leaderEpoch)
// return if we have no valid messages or if this is a duplicate of the last appended entry
// 如果压根就不需要写入任何消息,直接返回即可
if (appendInfo.shallowCount == 0) appendInfo
else {
// trim any invalid bytes or partial messages before appending it to the on-disk log
// 第2步:消息格式规整,即删除无效格式消息或无效字节
var validRecords = trimInvalidBytes(records, appendInfo)
// they are valid, insert them in the log
lock synchronized {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
checkIfMemoryMappedBufferClosed() // 确保Log对象未关闭
if (validateAndAssignOffsets) { // 需要分配位移
// assign offsets to the message set
// 第3步:使用当前LEO值作为待写入消息集合中第一条消息的位移值
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(LogOffsetMetadata(offset.value))
val now = time.milliseconds
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
origin,
interBrokerProtocolVersion,
brokerTopicStats)
} catch {
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
}
// 更新校验结果对象类LogAppendInfo
validRecords = validateAndOffsetAssignResult.validatedRecords
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1
appendInfo.recordConversionStats = validateAndOffsetAssignResult.recordConversionStats
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
appendInfo.logAppendTime = now
// re-validate message sizes if there's a possibility that they have changed (due to re-compression or message
// format conversion)
// 第4步:验证消息,确保消息大小不超限
if (!ignoreRecordSize && validateAndOffsetAssignResult.messageSizeMaybeChanged) {
validRecords.batches.forEach { batch =>
if (batch.sizeInBytes > config.maxMessageSize) {
// we record the original message set size instead of the trimmed size
// to be consistent with pre-compression bytesRejectedRate recording
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException(s"Message batch size is ${batch.sizeInBytes} bytes in append to" +
s"partition $topicPartition which exceeds the maximum configured size of ${config.maxMessageSize}.")
}
}
}
} else {
// we are taking the offsets we are given
// 直接使用给定的位移值,无需自己分配位移值
if (!appendInfo.offsetsMonotonic) // 确保消息位移值的单调递增性
throw new OffsetsOutOfOrderException(s"Out of order offsets found in append to $topicPartition: " +
records.records.asScala.map(_.offset))
if (appendInfo.firstOrLastOffsetOfFirstBatch < nextOffsetMetadata.messageOffset) {
// we may still be able to recover if the log is empty
// one example: fetching from log start offset on the leader which is not batch aligned,
// which may happen as a result of AdminClient#deleteRecords()
val firstOffset = appendInfo.firstOffset match {
case Some(offsetMetadata) => offsetMetadata.messageOffset
case None => records.batches.asScala.head.baseOffset()
}
val firstOrLast = if (appendInfo.firstOffset.isDefined) "First offset" else "Last offset of the first batch"
throw new UnexpectedAppendOffsetException(
s"Unexpected offset in append to $topicPartition. $firstOrLast " +
s"${appendInfo.firstOrLastOffsetOfFirstBatch} is less than the next offset ${nextOffsetMetadata.messageOffset}. " +
s"First 10 offsets in append: ${records.records.asScala.take(10).map(_.offset)}, last offset in" +
s" append: ${appendInfo.lastOffset}. Log start offset = $logStartOffset",
firstOffset, appendInfo.lastOffset)
}
}
// update the epoch cache with the epoch stamped onto the message by the leader
// 第5步:更新Leader Epoch缓存
validRecords.batches.forEach { batch =>
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {
maybeAssignEpochStartOffset(batch.partitionLeaderEpoch, batch.baseOffset)
} else {
// In partial upgrade scenarios, we may get a temporary regression to the message format. In
// order to ensure the safety of leader election, we clear the epoch cache so that we revert
// to truncation by high watermark after the next leader election.
leaderEpochCache.filter(_.nonEmpty).foreach { cache =>
warn(s"Clearing leader epoch cache after unexpected append with message format v${batch.magic}")
cache.clearAndFlush()
}
}
}
// check messages set size may be exceed config.segmentSize
// 第6步:确保消息大小不超限
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException(s"Message batch size is ${validRecords.sizeInBytes} bytes in append " +
s"to partition $topicPartition, which exceeds the maximum configured segment size of ${config.segmentSize}.")
}
// maybe roll the log if this segment is full
// 第7步:执行日志切分。当前日志段剩余容量可能无法容纳新消息集合,因此有必要创建一个新的日志段来保存待写入的所有消息
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// now that we have valid records, offsets assigned, and timestamps updated, we need to
// validate the idempotent/transactional state of the producers and collect some metadata
// 第8步:验证事务状态
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
maybeDuplicate match {
case Some(duplicate) =>
appendInfo.firstOffset = Some(LogOffsetMetadata(duplicate.firstOffset))
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
case None =>
// Before appending update the first offset metadata to include segment information
appendInfo.firstOffset = appendInfo.firstOffset.map { offsetMetadata =>
offsetMetadata.copy(segmentBaseOffset = segment.baseOffset, relativePositionInSegment = segment.size)
}
// 第9步:执行真正的消息写入操作,主要调用日志段对象的append方法实现
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// Increment the log end offset. We do this immediately after the append because a
// write to the transaction index below may fail and we want to ensure that the offsets
// of future appends still grow monotonically. The resulting transaction index inconsistency
// will be cleaned up after the log directory is recovered. Note that the end offset of the
// ProducerStateManager will not be updated and the last stable offset will not advance
// if the append to the transaction index fails.
// 第10步:更新LEO对象,其中,LEO值是消息集合中最后一条消息位移值+1
// 前面说过,LEO值永远指向下一条不存在的消息
updateLogEndOffset(appendInfo.lastOffset + 1)
// update the producer state
// 第11步:更新事务状态
updatedProducers.values.foreach(producerAppendInfo => producerStateManager.update(producerAppendInfo))
// update the transaction index with the true last stable offset. The last offset visible
// to consumers using READ_COMMITTED will be limited by this value and the high watermark.
completedTxns.foreach { completedTxn =>
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
segment.updateTxnIndex(completedTxn, lastStableOffset)
producerStateManager.completeTxn(completedTxn)
}
// always update the last producer id map offset so that the snapshot reflects the current offset
// even if there isn't any idempotent data being written
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// update the first unstable offset (which is used to compute LSO)
maybeIncrementFirstUnstableOffset()
trace(s"Appended message set with last offset: ${appendInfo.lastOffset}, " +
s"first offset: ${appendInfo.firstOffset}, " +
s"next offset: ${nextOffsetMetadata.messageOffset}, " +
s"and messages: $validRecords")
// 是否需要手动落盘。一般情况下我们不需要设置Broker端参数log.flush.interval.messages
// 落盘操作交由操作系统来完成。但某些情况下,可以设置该参数来确保高可靠性
if (unflushedMessages >= config.flushInterval) flush()
}
// 第12步:返回写入结果
appendInfo
}
}
}
}
这些步骤里有没有需要你格外注意的呢?我希望你重点关注下第 1 步,即 Kafka 如何校验消息,重点是看针对不同的消息格式版本,Kafka 是如何做校验的。
说起消息校验,你还记得上一讲我们提到的 LogAppendInfo 类吗?它就是一个普通的 POJO 类,里面几乎保存了待写入消息集合的所有信息。我们来详细了解一下。
case class LogAppendInfo(var firstOffset: Option[Long],
var lastOffset: Long, // 消息集合最后一条消息的位移值
var maxTimestamp: Long, // 消息集合最大消息时间戳
var offsetOfMaxTimestamp: Long, // 消息集合最大消息时间戳所属消息的位移值
var logAppendTime: Long, // 写入消息时间戳
var logStartOffset: Long, // 消息集合首条消息的位移值
// 消息转换统计类,里面记录了执行了格式转换的消息数等数据
var recordConversionStats: RecordConversionStats,
sourceCodec: CompressionCodec, // 消息集合中消息使用的压缩器(Compressor)类型,比如是Snappy还是LZ4
targetCodec: CompressionCodec, // 写入消息时需要使用的压缩器类型
shallowCount: Int, // 消息批次数,每个消息批次下可能包含多条消息
validBytes: Int, // 写入消息总字节数
offsetsMonotonic: Boolean, // 消息位移值是否是顺序增加的
lastOffsetOfFirstBatch: Long, // 首个消息批次中最后一条消息的位移
recordErrors: Seq[RecordError] = List(), // 写入消息时出现的异常列表
errorMessage: String = null) { // 错误码
......
}
大部分字段的含义很明确,这里我稍微提一下 lastOffset 和 lastOffsetOfFirstBatch。
Kafka 消息格式经历了两次大的变迁,目前是 0.11.0.0 版本引入的 Version 2 消息格式。我们没有必要详细了解这些格式的变迁,你只需要知道,在 0.11.0.0 版本之后,lastOffset 和 lastOffsetOfFirstBatch 都是指向消息集合的最后一条消息即可。它们的区别主要体现在 0.11.0.0 之前的版本。
append 方法调用 analyzeAndValidateRecords 方法对消息集合进行校验,并生成对应的 LogAppendInfo 对象,其流程如下:
private def analyzeAndValidateRecords(records: MemoryRecords,
origin: AppendOrigin,
ignoreRecordSize: Boolean,
leaderEpoch: Int): LogAppendInfo = {
var shallowMessageCount = 0
var validBytesCount = 0
var firstOffset: Option[LogOffsetMetadata] = None
var lastOffset = -1L
var lastLeaderEpoch = RecordBatch.NO_PARTITION_LEADER_EPOCH
var sourceCodec: CompressionCodec = NoCompressionCodec
var monotonic = true
var maxTimestamp = RecordBatch.NO_TIMESTAMP
var offsetOfMaxTimestamp = -1L
var readFirstMessage = false
var lastOffsetOfFirstBatch = -1L
records.batches.forEach { batch =>
if (origin == RaftLeader && batch.partitionLeaderEpoch != leaderEpoch) {
throw new InvalidRecordException("Append from Raft leader did not set the batch epoch correctly")
}
// we only validate V2 and higher to avoid potential compatibility issues with older clients
// 消息格式Version 2的消息批次,起始位移值必须从0开始
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2 && origin == AppendOrigin.Client && batch.baseOffset != 0)
throw new InvalidRecordException(s"The baseOffset of the record batch in the append to $topicPartition should " +
s"be 0, but it is ${batch.baseOffset}")
// update the first offset if on the first message. For magic versions older than 2, we use the last offset
// to avoid the need to decompress the data (the last offset can be obtained directly from the wrapper message).
// For magic version 2, we can get the first offset directly from the batch header.
// When appending to the leader, we will update LogAppendInfo.baseOffset with the correct value. In the follower
// case, validation will be more lenient.
// Also indicate whether we have the accurate first offset or not
if (!readFirstMessage) {
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2)
firstOffset = Some(LogOffsetMetadata(batch.baseOffset)) // 更新firstOffset字段
lastOffsetOfFirstBatch = batch.lastOffset // 更新lastOffsetOfFirstBatch字段
readFirstMessage = true
}
// check that offsets are monotonically increasing
// 一旦出现当前lastOffset不小于下一个batch的lastOffset,说明上一个batch中有消息的位移值大于后面batch的消息
// 这违反了位移值单调递增性
if (lastOffset >= batch.lastOffset)
monotonic = false
// update the last offset seen
// 使用当前batch最后一条消息的位移值去更新lastOffset
lastOffset = batch.lastOffset
lastLeaderEpoch = batch.partitionLeaderEpoch
// Check if the message sizes are valid.
// 检查消息批次总字节数大小是否超限,即是否大于Broker端参数max.message.bytes值
val batchSize = batch.sizeInBytes
if (!ignoreRecordSize && batchSize > config.maxMessageSize) {
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException(s"The record batch size in the append to $topicPartition is $batchSize bytes " +
s"which exceeds the maximum configured value of ${config.maxMessageSize}.")
}
// check the validity of the message by checking CRC
// 执行消息批次校验,包括格式是否正确以及CRC校验
if (!batch.isValid) {
brokerTopicStats.allTopicsStats.invalidMessageCrcRecordsPerSec.mark()
throw new CorruptRecordException(s"Record is corrupt (stored crc = ${batch.checksum()}) in topic partition $topicPartition.")
}
// 更新maxTimestamp字段和offsetOfMaxTimestamp
if (batch.maxTimestamp > maxTimestamp) {
maxTimestamp = batch.maxTimestamp
offsetOfMaxTimestamp = lastOffset
}
// 累加消息批次计数器以及有效字节数,更新shallowMessageCount字段
shallowMessageCount += 1
validBytesCount += batchSize
// 从消息批次中获取压缩器类型
val messageCodec = CompressionCodec.getCompressionCodec(batch.compressionType.id)
if (messageCodec != NoCompressionCodec)
sourceCodec = messageCodec
}
// Apply broker-side compression if any
// 获取Broker端设置的压缩器类型,即Broker端参数compression.type值。
// 该参数默认值是producer,表示sourceCodec用的什么压缩器,targetCodec就用什么
val targetCodec = BrokerCompressionCodec.getTargetCompressionCodec(config.compressionType, sourceCodec)
val lastLeaderEpochOpt: Option[Int] = if (lastLeaderEpoch != RecordBatch.NO_PARTITION_LEADER_EPOCH)
Some(lastLeaderEpoch)
else
None
// 最后生成LogAppendInfo对象并返回
LogAppendInfo(firstOffset, lastOffset, lastLeaderEpochOpt, maxTimestamp, offsetOfMaxTimestamp, RecordBatch.NO_TIMESTAMP, logStartOffset,
RecordConversionStats.EMPTY, sourceCodec, targetCodec, shallowMessageCount, validBytesCount, monotonic, lastOffsetOfFirstBatch)
}
- 读取操作
说完了 append 方法,下面我们聊聊 read 方法。read 方法的流程相对要简单一些,首先来看它的方法签名:
def read(startOffset: Long,
maxLength: Int,
isolation: FetchIsolation,
minOneMessage: Boolean): FetchDataInfo = {
...
}
它接收 4 个参数,含义如下:
-
startOffset,即从 Log 对象的哪个位移值开始读消息。
-
maxLength,即最多能读取多少字节。
-
isolation,设置读取隔离级别,主要控制能够读取的最大位移值,多用于 Kafka 事务。
-
minOneMessage,即是否允许至少读一条消息。设想如果消息很大,超过了 maxLength,正常情况下 read 方法永远不会返回任何消息。但如果设置了该参数为 true,read 方法就保证至少能够返回一条消息。
read 方法的返回值是 FetchDataInfo 类,也是一个 POJO 类,里面最重要的数据就是读取的消息集合,其他数据还包括位移等元数据信息。
下面我们来看下 read 方法的流程。
def read(startOffset: Long,
maxLength: Int,
isolation: FetchIsolation,
minOneMessage: Boolean): FetchDataInfo = {
maybeHandleIOException(s"Exception while reading from $topicPartition in dir ${dir.getParent}") {
trace(s"Reading maximum $maxLength bytes at offset $startOffset from log with " +
s"total length $size bytes")
val includeAbortedTxns = isolation == FetchTxnCommitted
// Because we don't use the lock for reading, the synchronization is a little bit tricky.
// We create the local variables to avoid race conditions with updates to the log.
// 读取消息时没有使用Monitor锁同步机制,因此这里取巧了,用本地变量的方式把LEO对象保存起来,避免争用(race condition)
val endOffsetMetadata = nextOffsetMetadata
val endOffset = endOffsetMetadata.messageOffset
// 找到startOffset值所在的日志段对象。注意要使用floorEntry方法
var segmentEntry = segments.floorEntry(startOffset)
// return error on attempt to read beyond the log end offset or read below log start offset
// 满足以下条件之一将被视为消息越界,即你要读取的消息不在该Log对象中:
// 1. 要读取的消息位移超过了LEO值
// 2. 没找到对应的日志段对象
// 3. 要读取的消息在Log Start Offset之下,同样是对外不可见的消息
if (startOffset > endOffset || segmentEntry == null || startOffset < logStartOffset)
throw new OffsetOutOfRangeException(s"Received request for offset $startOffset for partition $topicPartition, " +
s"but we only have log segments in the range $logStartOffset to $endOffset.")
// 查看一下读取隔离级别设置。
// 普通消费者能够看到[Log Start Offset, 高水位值)之间的消息
// 事务型消费者只能看到[Log Start Offset, Log Stable Offset]之间的消息。Log Stable Offset(LSO)是比LEO值小的位移值,为Kafka事务使用
// Follower副本消费者能够看到[Log Start Offset,LEO)之间的消息
val maxOffsetMetadata = isolation match {
case FetchLogEnd => endOffsetMetadata
case FetchHighWatermark => fetchHighWatermarkMetadata
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
if (startOffset == maxOffsetMetadata.messageOffset)
emptyFetchDataInfo(maxOffsetMetadata, includeAbortedTxns)
else if (startOffset > maxOffsetMetadata.messageOffset) // 如果要读取的起始位置超过了能读取的最大位置,返回空的消息集合,因为没法读取任何消息
emptyFetchDataInfo(convertToOffsetMetadataOrThrow(startOffset), includeAbortedTxns)
else {
// Do the read on the segment with a base offset less than the target offset
// but if that segment doesn't contain any messages with an offset greater than that
// continue to read from successive segments until we get some messages or we reach the end of the log
var done = segmentEntry == null
var fetchDataInfo: FetchDataInfo = null
while (!done) { // 开始遍历日志段对象,直到读出东西来或者读到日志末尾
val segment = segmentEntry.getValue
val maxPosition =
// Use the max offset position if it is on this segment; otherwise, the segment size is the limit.
if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) maxOffsetMetadata.relativePositionInSegment
else segment.size
// 调用日志段对象的read方法执行真正的读取消息操作
fetchDataInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchDataInfo != null) {
if (includeAbortedTxns)
fetchDataInfo = addAbortedTransactions(startOffset, segmentEntry, fetchDataInfo)
} else segmentEntry = segments.higherEntry(segmentEntry.getKey) // 如果没有返回任何消息,去下一个日志段对象试试
done = fetchDataInfo != null || segmentEntry == null
}
if (fetchDataInfo != null) fetchDataInfo
else {
// okay we are beyond the end of the last segment with no data fetched although the start offset is in range,
// this can happen when all messages with offset larger than start offsets have been deleted.
// In this case, we will return the empty set with log end offset metadata
// 已经读到日志末尾还是没有数据返回,只能返回空消息集合
FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY)
}
}
}
}
2.9 LOG常见操作总结
讲解了 Kafka 的 Log 对象以及常见的操作。
- 高水位管理:Log 对象定义了高水位对象以及管理它的各种操作,主要包括更新和读取。
- 日志段管理:作为日志段的容器,Log 对象保存了很多日志段对象。你需要重点掌握这些日志段对象被组织在一起的方式以及 Kafka Log 对象是如何对它们进行管理的。
- 关键位移值管理:主要涉及对 Log Start Offset 和 LEO 的管理。这两个位移值是 Log 对象非常关键的字段。比如,副本管理、状态机管理等高阶功能都要依赖于它们。
- 读写操作:日志读写是实现 Kafka 消息引擎基本功能的基石。虽然你不需要掌握每行语句的含义,但你至少要明白大体的操作流程。
讲到这里,Kafka Log 部分的源码我就介绍完了。建议特别关注下高水位管理和读写操作部分的代码(特别是后者)。

3 索引:改进的二分查找算法在Kafka索引的应用
Kafka 的索引组件中应用了二分查找算法,而且社区还针对 Kafka 自身的特点对其进行了改良。
3.1 索引类图及源文件组织架构
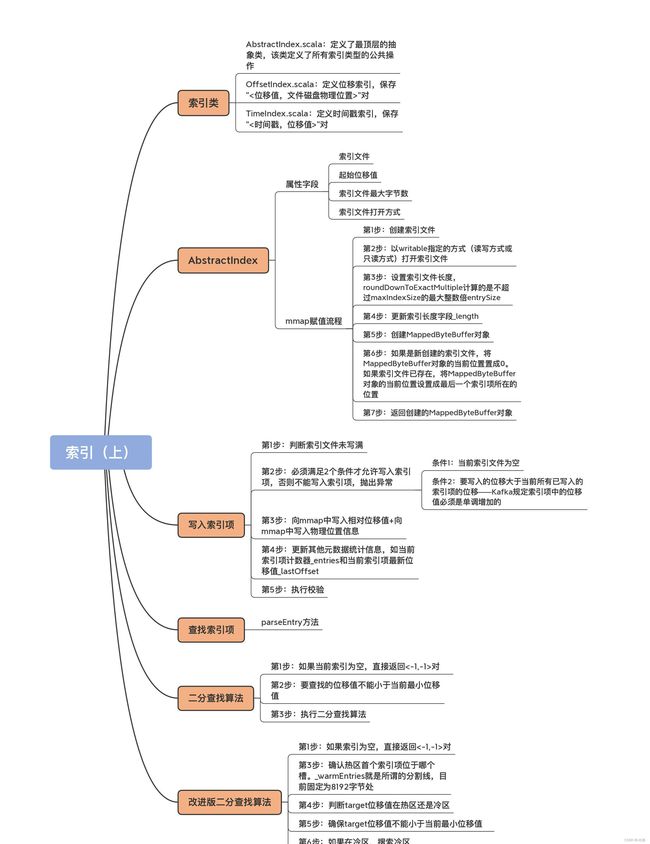
在 Kafka 源码中,跟索引相关的源码文件有 5 个,它们都位于 core 包的 /src/main/scala/kafka/log 路径下。
- AbstractIndex.scala:它定义了最顶层的抽象类,这个类封装了所有索引类型的公共操作。
- LazyIndex.scala:它定义了 AbstractIndex 上的一个包装类,实现索引项延迟加载。这个类主要是为了提高性能。
- OffsetIndex.scala:定义位移索引,保存“< 位移值,文件磁盘物理位置 >”对。
- TimeIndex.scala:定义时间戳索引,保存“< 时间戳,位移值 >”对。
- TransactionIndex.scala:定义事务索引,为已中止事务(Aborted Transcation)保存重要的元数据信息。只有启用 Kafka 事务后,这个索引才有可能出现。
这些类的关系如下图所示:

其中,OffsetIndex、TimeIndex 和 TransactionIndex 都继承了 AbstractIndex 类,而上层的 LazyIndex 仅仅是包装了一个 AbstractIndex 的实现类,用于延迟加载。就像我之前说的,LazyIndex 的作用是为了提升性能,并没有什么功能上的改进。
abstract class AbstractIndex(@volatile private var _file: File, val baseOffset: Long, val maxIndexSize: Int = -1,
val writable: Boolean) extends Closeable {
...
}
AbstractIndex 定义了 4 个属性字段。由于是一个抽象基类,它的所有子类自动地继承了这 4 个字段。也就是说,Kafka 所有类型的索引对象都定义了这些属性。我先给你解释下这些属性的含义。
- 索引文件(_file)。每个索引对象在磁盘上都对应了一个索引文件。你可能注意到了,这个字段是 var 型,说明它是可以被修改的。难道索引对象还能动态更换底层的索引文件吗?是的。自 1.1.0 版本之后,Kafka 允许迁移底层的日志路径,所以,索引文件自然要是可以更换的。
- 起始位移值(baseOffset)。索引对象对应日志段对象的起始位移值。举个例子,如果你查看 Kafka 日志路径的话,就会发现,日志文件和索引文件都是成组出现的。比如说,如果日志文件是 00000000000000000123.log,正常情况下,一定还有一组索引文件 00000000000000000123.index、00000000000000000123.timeindex 等。这里的“123”就是这组文件的起始位移值,也就是 baseOffset 值。
- 索引文件最大字节数(maxIndexSize)。它控制索引文件的最大长度。Kafka 源码传入该参数的值是 Broker 端参数 segment.index.bytes 的值,即 10MB。这就是在默认情况下,所有 Kafka 索引文件大小都是 10MB 的原因。
- 索引文件打开方式(writable)。“True”表示以“读写”方式打开,“False”表示以“只读”方式打开。
AbstractIndex 是抽象的索引对象类。可以说,它是承载索引项的容器,而每个继承它的子类负责定义具体的索引项结构。比如,OffsetIndex 的索引项是 < 位移值,物理磁盘位置 > 对,TimeIndex 的索引项是 < 时间戳,位移值 > 对。基于这样的设计理念,AbstractIndex 类中定义了一个抽象方法 entrySize 来表示不同索引项的大小,如下所示:
protected def entrySize: Int
子类实现该方法时需要给定自己索引项的大小,对于 OffsetIndex 而言,该值就是 8;对于 TimeIndex 而言,该值是 12,如下所示:
// OffsetIndex
override def entrySize = 8
// TimeIndex
override def entrySize = 12
在 OffsetIndex 中,位移值用 4 个字节来表示,物理磁盘位置也用 4 个字节来表示,所以总共是 8 个字节。你可能会说,位移值不是长整型吗,应该是 8 个字节才对啊。还记得 AbstractIndex 已经保存了 baseOffset 了吗?这里的位移值,实际上是相对于 baseOffset 的相对位移值,即真实位移值减去 baseOffset 的值。下节课我会给你重点讲一下它,这里你只需要知道使用相对位移值能够有效地节省磁盘空间就行了。而 Broker 端参数 log.segment.bytes 是整型,这说明,Kafka 中每个日志段文件的大小不会超过 2^32,即 4GB,这就说明同一个日志段文件上的位移值减去 baseOffset 的差值一定在整数范围内。因此,源码只需要 4 个字节保存就行了。
同理,TimeIndex 中的时间戳类型是长整型,占用 8 个字节,位移依然使用相对位移值,占用 4 个字节,因此总共需要 12 个字节。
如果有人问你,Kafka 中的索引底层的实现原理是什么?你可以大声地告诉他:内存映射文件,即 Java 中的 MappedByteBuffer。
使用内存映射文件的主要优势在于,它有很高的 I/O 性能,特别是对于索引这样的小文件来说,由于文件内存被直接映射到一段虚拟内存上,访问内存映射文件的速度要快于普通的读写文件速度。
另外,在很多操作系统中(比如 Linux),这段映射的内存区域实际上就是内核的页缓存(Page Cache)。这就意味着,里面的数据不需要重复拷贝到用户态空间,避免了很多不必要的时间、空间消耗。
在 AbstractIndex 中,这个 MappedByteBuffer 就是名为 mmap 的变量。接下来,我用注释的方式,带你深入了解下这个 mmap 的主要流程。
@volatile
protected var mmap: MappedByteBuffer = {
// 第1步:创建索引文件
val newlyCreated = file.createNewFile()
// 第2步:以writable指定的方式(读写方式或只读方式)打开索引文件
val raf = if (writable) new RandomAccessFile(file, "rw") else new RandomAccessFile(file, "r")
try {
if(newlyCreated) {
if(maxIndexSize < entrySize) // 预设的索引文件大小不能太小,如果连一个索引项都保存不了,直接抛出异常
throw new IllegalArgumentException("Invalid max index size: " + maxIndexSize)
// 第3步:设置索引文件长度,roundDownToExactMultiple计算的是不超过maxIndexSize的最大整数倍entrySize
// 比如maxIndexSize=1234567,entrySize=8,那么调整后的文件长度为1234560
raf.setLength(roundDownToExactMultiple(maxIndexSize, entrySize))
}
// 第4步:更新索引长度字段_length
_length = raf.length()
// 第5步:创建MappedByteBuffer对象
val idx = {
if (writable)
raf.getChannel.map(FileChannel.MapMode.READ_WRITE, 0, _length)
else
raf.getChannel.map(FileChannel.MapMode.READ_ONLY, 0, _length)
}
/* set the position in the index for the next entry */
// 第6步:如果是新创建的索引文件,将MappedByteBuffer对象的当前位置置成0
// 如果索引文件已存在,将MappedByteBuffer对象的当前位置设置成最后一个索引项所在的位置
if(newlyCreated)
idx.position(0)
else
idx.position(roundDownToExactMultiple(idx.limit(), entrySize))
// 第7步:返回创建的MappedByteBuffer对象
idx
} finally {
CoreUtils.swallow(raf.close(), AbstractIndex) // 关闭打开索引文件句柄
}
}
这些代码最主要的作用就是创建 mmap 对象。要知道,AbstractIndex 其他大部分的操作都是和 mmap 相关。我举两个简单的小例子。
例 1:如果我们要计算索引对象中当前有多少个索引项,那么只需要执行下列计算即可:
protected var _entries: Int = mmap.position() / entrySize
例 2:如果我们要计算索引文件最多能容纳多少个索引项,只要定义下面的变量就行了:
private[this] var _maxEntries: Int = mmap.limit() / entrySize
再进一步,有了这两个变量,我们就能够很容易地编写一个方法,来判断当前索引文件是否已经写满:
def isFull: Boolean = _entries >= _maxEntries
总之,AbstractIndex 中最重要的就是这个 mmap 变量了。事实上,AbstractIndex 继承类实现添加索引项的主要逻辑,也就是向 mmap 中添加对应的字段。
3.2 写入索引项
下面这段代码是 OffsetIndex 的 append 方法,用于向索引文件中写入新索引项。
def append(offset: Long, position: Int): Unit = {
inLock(lock) {
// 第1步:判断索引文件未写满
require(!isFull, "Attempt to append to a full index (size = " + _entries + ").")
// 第2步:必须满足以下条件之一才允许写入索引项:
// 条件1:当前索引文件为空
// 条件2:要写入的位移大于当前所有已写入的索引项的位移——Kafka规定索引项中的位移值必须是单调增加的
if (_entries == 0 || offset > _lastOffset) {
trace(s"Adding index entry $offset => $position to ${file.getAbsolutePath}")
mmap.putInt(relativeOffset(offset)) // 第3步A:向mmap中写入相对位移值
mmap.putInt(position) // 第3步B:向mmap中写入物理位置信息
// 第4步:更新其他元数据统计信息,如当前索引项计数器_entries和当前索引项最新位移值_lastOffset
_entries += 1
_lastOffset = offset
// 第5步:执行校验。写入的索引项格式必须符合要求,即索引项个数*单个索引项占用字节数匹配当前文件物理大小,否则说明文件已损坏
require(_entries * entrySize == mmap.position(), entries + " entries but file position in index is " + mmap.position() + ".")
} else {
// 如果第2步中两个条件都不满足,不能执行写入索引项操作,抛出异常
throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to position $entries no larger than" +
s" the last offset appended (${_lastOffset}) to ${file.getAbsolutePath}.")
}
}
}

3.3 查找索引项
索引项的写入逻辑并不复杂,难点在于如何查找索引项。AbstractIndex 定义了抽象方法 parseEntry 用于查找给定的索引项,如下所示:
protected def parseEntry(buffer: ByteBuffer, n: Int): IndexEntry
这里的“n”表示要查找给定 ByteBuffer 中保存的第 n 个索引项(在 Kafka 中也称第 n 个槽)。IndexEntry 是源码定义的一个接口,里面有两个方法:indexKey 和 indexValue,分别返回不同类型索引的
OffsetIndex 实现 parseEntry 的逻辑如下:
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {
OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))
}
OffsetPosition 是实现 IndexEntry 的实现类,Key 就是之前说的位移值,而 Value 就是物理磁盘位置值。所以,这里你能看到代码调用了 relativeOffset(buffer, n) + baseOffset 计算出绝对位移值,之后调用 physical(buffer, n) 计算物理磁盘位置,最后将它们封装到一起作为一个独立的索引项返回。
建议去看下 relativeOffset 和 physical 方法的实现,看看它们是如何计算相对位移值和物理磁盘位置信息的。
有了 parseEntry 方法,我们就能够根据给定的 n 来查找索引项了。但是,这里还有个问题需要解决,那就是,我们如何确定要找的索引项在第 n 个槽中呢?其实本质上,这是一个算法问题,也就是如何从一组已排序的数中快速定位符合条件的那个数。
3.4 二分查找算法
到目前为止,从已排序数组中寻找某个数字最快速的算法就是二分查找了,它能做到 O(lgN) 的时间复杂度。Kafka 的索引组件就应用了二分查找算法。
我先给出原版的实现算法代码。
private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchEntity): (Int, Int) = {
// 第1步:如果当前索引为空,直接返回<-1,-1>对
if(_entries == 0)
return (-1, -1)
// 第2步:要查找的位移值不能小于当前最小位移值
if(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
// binary search for the entry
// 第3步:执行二分查找算法
var lo = 0
var hi = _entries - 1
while(lo < hi) {
val mid = ceil(hi/2.0 + lo/2.0).toInt
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if(compareResult > 0)
hi = mid - 1
else if(compareResult < 0)
lo = mid
else
return (mid, mid)
}
(lo, if (lo == _entries - 1) -1 else lo + 1)
这段代码的核心是,第 3 步的二分查找算法。熟悉 Binary Search 的话,你对这段代码一定不会感到陌生。
讲到这里,似乎一切很完美:Kafka 索引应用二分查找算法快速定位待查找索引项位置,之后调用 parseEntry 来读取索引项。不过,这真的就是无懈可击的解决方案了吗?
3.5 改进版二分查找算法
显然不是!我前面说过了,大多数操作系统使用页缓存来实现内存映射,而目前几乎所有的操作系统都使用 LRU(Least Recently Used)或类似于 LRU 的机制来管理页缓存。
Kafka 写入索引文件的方式是在文件末尾追加写入,而几乎所有的索引查询都集中在索引的尾部。这么来看的话,LRU 机制是非常适合 Kafka 的索引访问场景的。但,这里有个问题是,当 Kafka 在查询索引的时候,原版的二分查找算法并没有考虑到缓存的问题,因此很可能会导致一些不必要的缺页中断(Page Fault)。此时,Kafka 线程会被阻塞,等待对应的索引项从物理磁盘中读出并放入到页缓存中。下面我举个例子来说明一下这个情况。假设 Kafka 的某个索引占用了操作系统页缓存 13 个页(Page),如果待查找的位移值位于最后一个页上,也就是 Page 12,那么标准的二分查找算法会依次读取页号 0、6、9、11 和 12,具体的推演流程如下所示:

通常来说,一个页上保存了成百上千的索引项数据。随着索引文件不断被写入,Page #12 不断地被填充新的索引项。如果此时索引查询方都来自 ISR 副本或 Lag 很小的消费者,那么这些查询大多集中在对 Page #12 的查询,因此,Page #0、6、9、11、12 一定经常性地被源码访问。也就是说,这些页一定保存在页缓存上。后面当新的索引项填满了 Page #12,页缓存就会申请一个新的 Page 来保存索引项,即 Page #13。
现在,最新索引项保存在 Page #13 中。如果要查找最新索引项,原版二分查找算法将会依次访问 Page #0、7、10、12 和 13。此时,问题来了:Page 7 和 10 已经很久没有被访问过了,它们大概率不在页缓存中,因此,一旦索引开始征用 Page #13,就会发生 Page Fault,等待那些冷页数据从磁盘中加载到页缓存。根据国外用户的测试,这种加载过程可能长达 1 秒。
显然,这是一个普遍的问题,即每当索引文件占用 Page 数发生变化时,就会强行变更二分查找的搜索路径,从而出现不在页缓存的冷数据必须要加载到页缓存的情形,而这种加载过程是非常耗时的。
基于这个问题,社区提出了改进版的二分查找策略,也就是缓存友好的搜索算法。总体的思路是,代码将所有索引项分成两个部分:热区(Warm Area)和冷区(Cold Area),然后分别在这两个区域内执行二分查找算法,如下图所示:

这个改进版算法的最大好处在于,查询最热那部分数据所遍历的 Page 永远是固定的,因此大概率在页缓存中,从而避免无意义的 Page Fault。
下面我们来看实际的代码。
private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchEntity): (Int, Int) = {
// 第1步:如果索引为空,直接返回<-1,-1>对
if(_entries == 0)
return (-1, -1)
// 封装原版的二分查找算法
def binarySearch(begin: Int, end: Int) : (Int, Int) = {
// binary search for the entry
var lo = begin
var hi = end
while(lo < hi) {
val mid = (lo + hi + 1) >>> 1
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if(compareResult > 0)
hi = mid - 1
else if(compareResult < 0)
lo = mid
else
return (mid, mid)
}
(lo, if (lo == _entries - 1) -1 else lo + 1)
}
// 第3步:确认热区首个索引项位于哪个槽。_warmEntries就是所谓的分割线,目前固定为8192字节处
// 如果是OffsetIndex,_warmEntries = 8192 / 8 = 1024,即第1024个槽
// 如果是TimeIndex,_warmEntries = 8192 / 12 = 682,即第682个槽
val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)
// 第4步:判断target位移值在热区还是冷区
if(compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {
return binarySearch(firstHotEntry, _entries - 1) // 如果在热区,搜索热区
}
// 第5步:确保target位移值不能小于当前最小位移值
if(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
// 第6步:如果在冷区,搜索冷区
binarySearch(0, firstHotEntry)
3.6 二分法查找索引总结
今天学习了 Kafka 中的索引机制,以及社区如何应用二分查找算法实现快速定位索引项。有两个重点。
- AbstractIndex:这是 Kafka 所有类型索引的抽象父类,里面的 mmap 变量是实现索引机制的核心。
- 改进版二分查找算法:社区在标准原版的基础上,对二分查找算法根据实际访问场景做了定制化的改进。你需要特别关注改进版在提升缓存性能方面做了哪些努力。改进版能够有效地提升页缓存的使用率,从而在整体上降低物理 I/O,缓解系统负载瓶颈。你最好能够从索引这个维度去思考社区在这方面所做的工作。
前面说过,Kafka 索引类型有三大类:位移索引、时间戳索引和已中止事务索引。相比于最后一类索引,前两类索引的出镜率更高一些。在 Kafka 的数据路径下,你肯定看到过很多.index 和.timeindex 后缀的文件。不知你是否有过这样的疑问:“这些文件是用来做什么的呢?” 现在我可以明确告诉你:.index 文件就是 Kafka 中的位移索引文件,而.timeindex 文件则是时间戳索引文件。
那么,位移索引和时间戳索引到底是做什么用的呢?它们之间的区别是什么?今天,我就为你揭晓这些问题的答案。
3.7 位移索引
在学习 Kafka 的任何一类索引的时候,我们都要关注两个问题:
- 索引中的索引项是如何定义的?
- 如何向索引写入新的索引项?
(1)索引项的定义
位移索引也就是所谓的 OffsetIndex,它可是一个老资历的组件了。每当 Consumer 需要从主题分区的某个位置开始读取消息时,Kafka 就会用到 OffsetIndex 直接定位物理文件位置,从而避免了因为从头读取消息而引入的昂贵的 I/O 操作。
不同索引类型保存不同的
这里我来具体解释一下相对位移的含义。还记得 AbstractIndex 类中的抽象方法 entrySize 吗?它定义了单个
override def entrySize = 8
为什么是 8 呢?相对位移是一个整型(Integer),占用 4 个字节,物理文件位置也是一个整型,同样占用 4 个字节,因此总共是 8 个字节。
那相对位移是什么值呢?我们知道,Kafka 中的消息位移值是一个长整型(Long),应该占用 8 个字节才对。在保存 OffsetIndex 的
举个简单的例子。假设一个索引文件保存了 1000 个索引项,使用相对位移值就能节省大约 4MB 的空间,这是不是一件很划算的事情呢?
AbstractIndex 定义了专门的方法,用于将一个 Long 型的位移值转换成相对位移,如下所示:
def relativeOffset(offset: Long): Int = {
val relativeOffset = toRelative(offset)
if (relativeOffset.isEmpty)
// 如果无法转换成功(比如差值超过了整型表示范围),则抛出异常
throw new IndexOffsetOverflowException(s"Integer overflow for offset: $offset (${file.getAbsoluteFile})")
relativeOffset.get
}
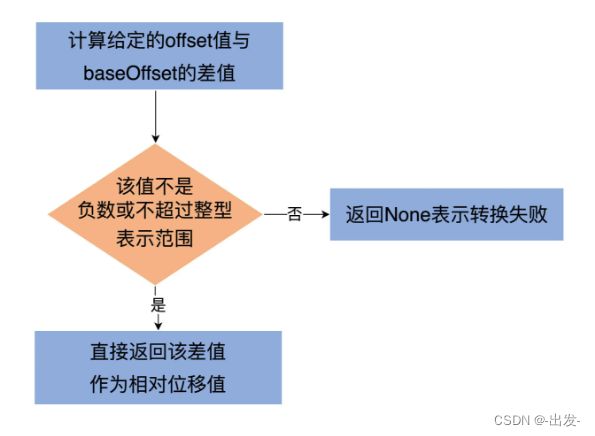
private def toRelative(offset: Long): Option[Int] = {
val relativeOffset = offset - baseOffset
if (relativeOffset < 0 || relativeOffset > Int.MaxValue)
None
else
Some(relativeOffset.toInt)
}
逻辑很简单:第一步是计算给定的 offset 值与 baseOffset 的差值;第二步是校验该差值不能是负数或不能超过整型表示范围。如果校验通过,就直接返回该差值作为相对位移值,否则就返回 None 表示转换失败。
当读取 OffsetIndex 时,源码还需要将相对位移值还原成之前的完整位移。这个是在 parseEntry 方法中实现的。
我来给你解释下具体的实现方法。
这个方法返回一个 OffsetPosition 类型。该类有两个方法,分别返回索引项的 Key 和 Value。
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {
OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))
}
这个方法返回一个 OffsetPosition 类型。该类有两个方法,分别返回索引项的 Key 和 Value。
这里的 parseEntry 方法,就是要构造 OffsetPosition 所需的 Key 和 Value。Key 是索引项中的完整位移值,代码使用 baseOffset + relativeOffset(buffer, n) 的方式将相对位移值还原成完整位移值;Value 是这个位移值上消息在日志段文件中的物理位置,代码调用 physical 方法计算这个物理位置并把它作为 Value。
最后,parseEntry 方法把 Key 和 Value 封装到一个 OffsetPosition 实例中,然后将这个实例返回。
由于索引文件的总字节数就是索引项字节数乘以索引项数,因此,代码结合 entrySize 和 buffer.getInt 方法能够轻松地计算出第 n 个索引项所处的物理文件位置。这就是 physical 方法做的事情。
(2)写入索引项
看下 OffsetIndex 中写入索引项 append 方法的实现。
def append(offset: Long, position: Int): Unit = {
inLock(lock) {
// 索引文件如果已经写满,直接抛出异常
require(!isFull, "Attempt to append to a full index (size = " + _entries + ").")
// 要保证待写入的位移值offset比当前索引文件中所有现存的位移值都要大
// 这主要是为了维护索引的单调增加性
if (_entries == 0 || offset > _lastOffset) {
trace(s"Adding index entry $offset => $position to ${file.getAbsolutePath}")
mmap.putInt(relativeOffset(offset)) // 向mmap写入相对位移值
mmap.putInt(position) // 向mmap写入物理文件位置
_entries += 1 // 更新索引项个数
_lastOffset = offset // 更新当前索引文件最大位移值
// 确保写入索引项格式符合要求
require(_entries * entrySize == mmap.position(), s"$entries entries but file position in index is ${mmap.position()}.")
} else {
throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to position $entries no larger than" +
s" the last offset appended (${_lastOffset}) to ${file.getAbsolutePath}.")
}
}
}
ppend 方法接收两个参数:Long 型的位移值和 Integer 型的物理文件位置。该方法最重要的两步,就是分别向 mmap 写入相对位移值和物理文件位置。
除了 append 方法,索引还有一个常见的操作:截断操作(Truncation)。截断操作是指,将索引文件内容直接裁剪掉一部分。比如,OffsetIndex 索引文件中当前保存了 100 个索引项,我想只保留最开始的 40 个索引项。源码定义了 truncateToEntries 方法来实现这个需求:
private def truncateToEntries(entries: Int): Unit = {
inLock(lock) {
_entries = entries
mmap.position(_entries * entrySize)
_lastOffset = lastEntry.offset
debug(s"Truncated index ${file.getAbsolutePath} to $entries entries;" +
s" position is now ${mmap.position()} and last offset is now ${_lastOffset}")
}
}
这个方法接收 entries 参数,表示要截取到哪个槽,主要的逻辑实现是调用 mmap 的 position 方法。源码中的 _entries * entrySize 就是 mmap 要截取到的字节处。
下面,我来说说 OffsetIndex 的使用方式。
既然 OffsetIndex 被用来快速定位消息所在的物理文件位置,那么必然需要定义一个方法执行对应的查询逻辑。这个方法就是 lookup。
def lookup(targetOffset: Long): OffsetPosition = {
maybeLock(lock) {
val idx = mmap.duplicate // 使用私有变量复制出整个索引映射区
// largestLowerBoundSlotFor方法底层使用了改进版的二分查找算法寻找对应的槽
val slot = largestLowerBoundSlotFor(idx, targetOffset, IndexSearchType.KEY)
// 如果没找到,返回一个空的位置,即物理文件位置从0开始,表示从头读日志文件
// 否则返回slot槽对应的索引项
if(slot == -1)
OffsetPosition(baseOffset, 0)
else
parseEntry(idx, slot)
}
}
3.8 时间戳索
引说完了 OffsetIndex,我们来看另一大类索引:时间戳索引,即 TimeIndex。与 OffsetIndex 类似,我们重点关注 TimeIndex 中索引项的定义,以及如何写入 TimeIndex 索引项。
(1)索引项的定义
与 OffsetIndex 不同的是,TimeIndex 保存的是 < 时间戳,相对位移值 > 对。时间戳需要一个长整型来保存,相对位移值使用 Integer 来保存。因此,TimeIndex 单个索引项需要占用 12 个字节。这也揭示了一个重要的事实:在保存同等数量索引项的基础上,TimeIndex 会比 OffsetIndex 占用更多的磁盘空间。
(2)写入索引项
TimeIndex 也有 append 方法,只不过它叫作 maybeAppend。我们来看下它的实现逻辑。
def maybeAppend(timestamp: Long, offset: Long, skipFullCheck: Boolean = false): Unit = {
inLock(lock) {
if (!skipFullCheck)
// 如果索引文件已写满,抛出异常
require(!isFull, "Attempt to append to a full time index (size = " + _entries + ").")
// 确保索引单调增加性
if (_entries != 0 && offset < lastEntry.offset)
throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to slot ${_entries} no larger than" +
s" the last offset appended (${lastEntry.offset}) to ${file.getAbsolutePath}.")
// 确保时间戳的单调增加性
if (_entries != 0 && timestamp < lastEntry.timestamp)
throw new IllegalStateException(s"Attempt to append a timestamp ($timestamp) to slot ${_entries} no larger" +
s" than the last timestamp appended (${lastEntry.timestamp}) to ${file.getAbsolutePath}.")
if (timestamp > lastEntry.timestamp) {
trace(s"Adding index entry $timestamp => $offset to ${file.getAbsolutePath}.")
mmap.putLong(timestamp) // 向mmap写入时间戳
mmap.putInt(relativeOffset(offset)) // 向mmap写入相对位移值
_entries += 1 // 更新索引项个数
_lastEntry = TimestampOffset(timestamp, offset) // 更新当前最新的索引项
require(_entries * entrySize == mmap.position(), s"${_entries} entries but file position in index is ${mmap.position()}.")
}
}
}
和 OffsetIndex 类似,向 TimeIndex 写入索引项的主体逻辑,是向 mmap 分别写入时间戳和相对位移值。只不过,除了校验位移值的单调增加性之外,TimeIndex 还会确保顺序写入的时间戳也是单调增加的。
区别
最后,用一张表格汇总下 OffsetIndex 和 TimeIndex 的特点和区别。
| 区分项 | OffsetIndex | TimeIndex |
|---|---|---|
| 文件后缀名 | .index | .timeindex |
| 用途 | 根据位移值快速查找消息所在文件位置 | 根据时间戳快速查找特定消息的位移值 |
| 索引项 | <相对位移值,物理文件位置>对 | <>时间戳,相对位移值>对 |
| 索引项字节数 | 8 | 12 |
| Broker端参数 | log.index.size.max.bytes | log.index.size.max.bytes |
3.9 位移索引和时间戳索引总结
今天详细分析了 OffsetIndex 和 TimeIndex,以及它们的不同之处。虽然 OffsetIndex 和 TimeIndex 是不同类型的索引,但 Kafka 内部是把二者结合使用的。通常的流程是,先使用 TimeIndex 寻找满足时间戳要求的消息位移值,然后再利用 OffsetIndex 去定位该位移值所在的物理文件位置。因此,它们其实是合作的关系。
最后,提醒你一点:不要对索引文件做任何修改!我碰到过因用户擅自重命名索引文件,从而导致 Broker 崩溃无法启动的场景。另外,虽然 Kafka 能够重建索引,但是随意地删除索引文件依然是一个很危险的操作。在生产环境中,我建议你尽量不要执行这样的操作。