Pytorch1.7复现PointNet++点云分割(含Open3D可视化)
毕设需要,复现一下PointNet++的对象分类、零件分割和场景分割,找点灵感和思路,做个踩坑记录。
下载代码
https://github.com/yanx27/Pointnet_Pointnet2_pytorch
我的运行环境是pytorch1.7+cuda11.0。
训练
PointNet++代码能实现3D对象分类、对象零件分割和语义场景分割。
对象分类
下载数据集ModelNet40,并存储在文件夹data/modelnet40_normal_resampled/。
## e.g., pointnet2_ssg without normal features
python train_classification.py --model pointnet2_cls_ssg --log_dir pointnet2_cls_ssg
python test_classification.py --log_dir pointnet2_cls_ssg
## e.g., pointnet2_ssg with normal features
python train_classification.py --model pointnet2_cls_ssg --use_normals --log_dir pointnet2_cls_ssg_normal
python test_classification.py --use_normals --log_dir pointnet2_cls_ssg_normal
## e.g., pointnet2_ssg with uniform sampling
python train_classification.py --model pointnet2_cls_ssg --use_uniform_sample --log_dir pointnet2_cls_ssg_fps
python test_classification.py --use_uniform_sample --log_dir pointnet2_cls_ssg_fps
- 主文件夹下运行代码
python train_classification.py --model pointnet2_cls_ssg --log_dir pointnet2_cls_ssg时可能会报错:
ImportError: cannot import name 'PointNetSetAbstraction'
原因是pointnet2_cls_ssg.py文件import时的工作目录时models文件夹,但是实际运行的工作目录时models的上级目录,因此需要在pointnet2_cls_ssg.py里把from pointnet2_utils import PointNetSetAbstraction改成from models.pointnet2_utils import PointNetSetAbstraction。
参考README.md文件,分类不是我的主攻点,这里就略过了。
零件分割
零件分割是将一个物体的各个零件分割出来,比如把椅子的椅子腿分出来。
下载数据集ShapeNet,并存储在文件夹data/shapenetcore_partanno_segmentation_benchmark_v0_normal/。
运行也很简单:
## e.g., pointnet2_msg
python train_partseg.py --model pointnet2_part_seg_msg --normal --log_dir pointnet2_part_seg_msg
python test_partseg.py --normal --log_dir pointnet2_part_seg_msg
shapenet数据集txt文件格式:前三个点是xyz,点云的位置坐标,后三个点是点云的rgb颜色坐标,最后一个点是这个点所属的小类别,即1表示所属50个小类别中的第一个。
写个代码用open3d可视化shapenet数据集的txt文件(随机配色):
import open3d as o3d
import numpy as np
'''
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(ROOT_DIR, 'data_utils'))
'''
txt_path = '/home/lin/CV_AI_learning/Pointnet_Pointnet2_pytorch-master/data/shapenetcore_partanno_segmentation_benchmark_v0_normal/02691156/1b3c6b2fbcf834cf62b600da24e0965.txt'
# 通过numpy读取txt点云
pcd = np.genfromtxt(txt_path, delimiter=" ")
pcd_vector = o3d.geometry.PointCloud()
# 加载点坐标
# txt点云前三个数值一般对应x、y、z坐标,可以通过open3d.geometry.PointCloud().points加载
# 如果有法线或颜色,那么可以分别通过open3d.geometry.PointCloud().normals或open3d.geometry.PointCloud().colors加载
pcd_vector.points = o3d.utility.Vector3dVector(pcd[:, :3])
pcd_vector.colors = o3d.utility.Vector3dVector(pcd[:, 3:6])
o3d.visualization.draw_geometries([pcd_vector])
GPU内存不够减小一下batch_size。
我这里训练了一下,接着代码的best_model.pth继续训练150轮,RTX3080单显卡训练一轮得六七分钟,150轮花了半天多的时间。
网上的代码基本test一下分割的一些参数就结束了,没有做可视化,参考这篇blog做了一下结果的可视化:PointNet++分割预测结果可视化。这篇blog首先用网络将输入图像的预测结果存为txt文件,然后用Matplotlib做可视化,过程有点复杂了,用open3d做可视化比较简洁一点,代码如下:
"传入模型权重文件,读取预测点,生成预测的txt文件"
import tqdm
import matplotlib.pyplot as plt
import matplotlib
import torch
import os
import json
import warnings
import numpy as np
import open3d as o3d
from torch.utils.data import Dataset
warnings.filterwarnings('ignore')
matplotlib.use("Agg")
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
pc = pc / m
return pc
class PartNormalDataset(Dataset):
def __init__(self,root = './data/shapenetcore_partanno_segmentation_benchmark_v0_normal', npoints=2500, class_choice=None, normal_channel=False,path='/home/lin/CV_AI_learning/Pointnet_Pointnet2_pytorch-master/data/shapenetcore_partanno_segmentation_benchmark_v0_normal/02691156/1a04e3eab45ca15dd86060f189eb133.txt'):
self.npoints = npoints # 采样点数
self.root = root # 文件根路径
self.catfile = os.path.join(self.root, 'synsetoffset2category.txt') # 类别和文件夹名字对应的路径
self.cat = {}
self.normal_channel = normal_channel # 是否使用rgb信息
with open(self.catfile, 'r') as f:
for line in f:
ls = line.strip().split()
self.cat[ls[0]] = ls[1]
self.cat = {k: v for k, v in self.cat.items()} #{'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}
self.classes_original = dict(zip(self.cat, range(len(self.cat)))) #{'Airplane': 0, 'Bag': 1, 'Cap': 2, 'Car': 3, 'Chair': 4, 'Earphone': 5, 'Guitar': 6, 'Knife': 7, 'Lamp': 8, 'Laptop': 9, 'Motorbike': 10, 'Mug': 11, 'Pistol': 12, 'Rocket': 13, 'Skateboard': 14, 'Table': 15}
if not class_choice is None: # 选择一些类别进行训练 好像没有使用这个功能
self.cat = {k:v for k,v in self.cat.items() if k in class_choice}
# print(self.cat)
self.datapath = [(list(self.cat.keys())[list(self.cat.values()).index(path.split('/')[-2])],path)]
# 输出的是元组,('Airplane',123.txt)
self.classes = {}
for i in self.cat.keys():
self.classes[i] = self.classes_original[i]
## self.classes 将类别的名称和索引对应起来 例如 飞机 <----> 0
# Mapping from category ('Chair') to a list of int [10,11,12,13] as segmentation labels
"""
shapenet 有16 个大类,然后每个大类有一些部件 ,例如飞机 'Airplane': [0, 1, 2, 3] 其中标签为0 1 2 3 的四个小类都属于飞机这个大类
self.seg_classes 就是将大类和小类对应起来
"""
self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# for cat in sorted(self.seg_classes.keys()):
# print(cat, self.seg_classes[cat])
self.cache = {} # from index to (point_set, cls, seg) tuple
self.cache_size = 20000
def __getitem__(self, index):
fn = self.datapath[0] # 根据索引 拿到训练数据的路径self.datepath是一个元组(类名,路径)
cat = self.datapath[0][0] # 拿到类名
cls = self.classes[cat] # 将类名转换为索引
cls = np.array([cls]).astype(np.int32)
# 读取modelnet40
data = np.loadtxt(fn[1],dtype=np.float32,delimiter=',')
# 读取shapenet
# data = np.loadtxt(fn[1]).astype(np.float32) # size 20488,7 读入这个txt文件,共20488个点,每个点xyz rgb +小类别的标签
if not self.normal_channel: # 判断是否使用rgb信息
point_set = data[:, 0:3]
else:
point_set = data[:, 0:6]
seg = data[:, -1].astype(np.int32) # 拿到小类别的标签
if len(self.cache) < self.cache_size:
self.cache[index] = (point_set, cls, seg)
point_set[:, 0:3] = pc_normalize(point_set[:, 0:3]) # 做一个归一化
choice = np.random.choice(len(seg), self.npoints, replace=True) # 对一个类别中的数据进行随机采样 返回索引,允许重复采样
# resample
point_set = point_set[choice, :] # 根据索引采样
seg = seg[choice]
return point_set, cls, seg # pointset是点云数据,cls十六个大类别,seg是一个数据中,不同点对应的小类别
def __len__(self):
return len(self.datapath)
class S3DISDataset(Dataset):
def __init__(self, split='train', data_root='trainval_fullarea', num_point=4096, test_area=5, block_size=1.0, sample_rate=1.0, transform=None):
super().__init__()
self.num_point = num_point # 4096
self.block_size = block_size # 1.0
self.transform = transform
rooms = sorted(os.listdir(data_root)) # data_root = 'data/s3dis/stanford_indoor3d/'
rooms = [room for room in rooms if 'Area_' in room] # 'Area_1_WC_1.npy' # 'Area_1_conferenceRoom_1.npy'
"rooms里面存放的是之前转换好的npy数据的名字,例如:Area_1_conferenceRoom1.npy....这样的数据"
if split == 'train':
rooms_split = [room for room in rooms if not 'Area_{}'.format(test_area) in room] # area 1,2,3,4,6为训练区域,5为测试区域
else:
rooms_split = [room for room in rooms if 'Area_{}'.format(test_area) in room]
"按照指定的test_area划分为训练集和测试集,默认是将区域5作为测试集"
#创建一些储存数据的列表
self.room_points, self.room_labels = [], [] # 每个房间的点云和标签
self.room_coord_min, self.room_coord_max = [], [] # 每个房间的最大值和最小值
num_point_all = [] # 初始化每个房间点的总数的列表
labelweights = np.zeros(13) # 初始标签权重,后面用来统计标签的权重
#每层初始化数据集的时候会执行以下代码
for room_name in tqdm.tqdm(rooms_split, total=len(rooms_split)):
#每次拿到的room_namej就是之前划分好的'Area_1_WC_1.npy'
room_path = os.path.join(data_root, room_name) #每个小房间的绝对路径,根路径+.npy
room_data = np.load(room_path) # 加载数据 xyzrgbl, (1112933, 7) N*7 room中点云的值 最后一个是标签#
points, labels = room_data[:, 0:6], room_data[:, 6] # xyzrgb, N*6; l, N 将训练数据与标签分开
"前面已经将标签进行了分离,那么这里 np.histogram就是统计每个房间里所有标签的总数,例如,第一个元素就是属于类别0的点的总数"
"将数据集所有点统计一次之后,就知道每个类别占总类别的比例,为后面加权计算损失做准备"
tmp, _ = np.histogram(labels, range(14)) # 统计标签的分布情况 [192039 185764 488740 0 0 0 28008 0 0 0, 0 0 218382]
#也就是有多少个点属于第i个类别
labelweights += tmp # 将它们累计起来
coord_min, coord_max = np.amin(points, axis=0)[:3], np.amax(points, axis=0)[:3] # 获取当前房间坐标的最值
self.room_points.append(points), self.room_labels.append(labels)
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
num_point_all.append(labels.size) # 标签的数量 也就是点的数量
"通过for循环后,所有的房间里类别分布情况和坐标情况都被放入了相应的变量中,后面就是计算权重了"
labelweights = labelweights.astype(np.float32)
labelweights = labelweights / np.sum(labelweights) # 计算标签的权重,每个类别的点云总数/总的点云总数
"感觉这里应该是为了避免有的点数量比较少,计算出训练的iou占miou的比重太大,所以在这里计算一下加权(根据点标签的数量进行加权)"
self.labelweights = np.power(np.amax(labelweights) / labelweights, 1 / 3.0) # 为什么这里还要开三次方???
print('label weight\n')
print(self.labelweights)
sample_prob = num_point_all / np.sum(num_point_all) # 每个房间占总的房间的比例
num_iter = int(np.sum(num_point_all) * sample_rate / num_point) # 如果按 sample rate进行采样,那么每个区域用4096个点 计算需要采样的次数
room_idxs = []
# 这里求的应该就是一个划分房间的索引
for index in range(len(rooms_split)):
room_idxs.extend([index] * int(round(sample_prob[index] * num_iter)))
self.room_idxs = np.array(room_idxs)
print("Totally {} samples in {} set.".format(len(self.room_idxs), split))
def __getitem__(self, idx):
room_idx = self.room_idxs[idx]
points = self.room_points[room_idx] # N * 6 --》 debug 1112933,6
labels = self.room_labels[room_idx] # N
N_points = points.shape[0]
while (True): # 这里是不是对应的就是将一个房间的点云切分为一个区域
center = points[np.random.choice(N_points)][:3] #从该个房间随机选一个点作为中心点
block_min = center - [self.block_size / 2.0, self.block_size / 2.0, 0]
block_max = center + [self.block_size / 2.0, self.block_size / 2.0, 0]
"找到符合要求点的索引(min<=x,y,z<=max),坐标被限制在最小和最大值之间"
point_idxs = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]
"如果符合要求的点至少有1024个,那么跳出循环,否则继续随机选择中心点,继续寻找"
if point_idxs.size > 1024:
break
"这里可以尝试修改一下1024这个参数,感觉采4096个点的话,可能存在太多重复的点"
if point_idxs.size >= self.num_point: # 如果找到符合条件的点大于给定的4096个点,那么随机采样4096个点作为被选择的点
selected_point_idxs = np.random.choice(point_idxs, self.num_point, replace=False)
else:# 如果符合条件的点小于4096 则随机重复采样凑够4096个点
selected_point_idxs = np.random.choice(point_idxs, self.num_point, replace=True) #
# normalize
selected_points = points[selected_point_idxs, :] # num_point * 6 拿到筛选后的4096个点
current_points = np.zeros((self.num_point, 9)) # num_point * 9
current_points[:, 6] = selected_points[:, 0] / self.room_coord_max[room_idx][0] # 选择点的坐标/被选择房间的最大值 做坐标的归一化
current_points[:, 7] = selected_points[:, 1] / self.room_coord_max[room_idx][1]
current_points[:, 8] = selected_points[:, 2] / self.room_coord_max[room_idx][2]
selected_points[:, 0] = selected_points[:, 0] - center[0] # 再将坐标移至随机采样的中心点
selected_points[:, 1] = selected_points[:, 1] - center[1]
selected_points[:, 3:6] /= 255.0 # 颜色信息归一化
current_points[:, 0:6] = selected_points
current_labels = labels[selected_point_idxs]
if self.transform is not None:
current_points, current_labels = self.transform(current_points, current_labels)
return current_points, current_labels, current_labels
def __len__(self):
return len(self.room_idxs)
class Generate_txt_and_3d_img:
def __init__(self,img_root,target_root,num_classes,testDataLoader,model_dict,color_map=None,path='123.txt'):
self.img_root = img_root # 点云数据路径
self.target_root = target_root # 生成txt标签和预测结果路径
self.testDataLoader = testDataLoader
self.num_classes = num_classes
self.color_map = color_map
self.heat_map = False # 控制是否输出heatmap
self.label_path_txt = os.path.join(self.target_root, 'label_txt') # 存放label的txt文件,指标注
self.path=path
self.make_dir(self.label_path_txt)
# 拿到模型 并加载权重
self.model_name = []
self.model = []
self.model_weight_path = []
for k,v in model_dict.items():
self.model_name.append(k)
self.model.append(v[0])
self.model_weight_path.append(v[1])
# 加载权重
self.load_cheackpoint_for_models(self.model_name,self.model,self.model_weight_path)
# 创建文件夹
self.all_pred_image_path = [] # 所有预测结果的路径列表
self.all_pred_txt_path = [] # 所有预测txt的路径列表
for n in self.model_name:
self.make_dir(os.path.join(self.target_root,n+'_predict_txt'))
self.make_dir(os.path.join(self.target_root, n + '_predict_image'))
self.all_pred_txt_path.append(os.path.join(self.target_root,n+'_predict_txt'))
self.all_pred_image_path.append(os.path.join(self.target_root, n + '_predict_image'))
"将模型对应的预测txt结果和img结果生成出来,对应几个模型就在列表中添加几个元素"
self.generate_predict_to_txt() # 生成预测txt
self.o3d_draw_3d_img()
def generate_predict_to_txt(self):
for batch_id, (points, label, target) in tqdm.tqdm(enumerate(self.testDataLoader),
total=len(self.testDataLoader),smoothing=0.9):
#点云数据、整个图像的标签、每个点的标签、 没有归一化的点云数据(带标签)torch.Size([1, 7, 2048])
points = points.transpose(2, 1)
#print('1',target.shape) # 1 torch.Size([1, 2048])
xyz_feature_point = points[:, :6, :]
# 将标签保存为txt文件
point_set_without_normal = np.asarray(torch.cat([points.permute(0, 2, 1),target[:,:,None]],dim=-1)).squeeze(0) # 代标签 没有归一化的点云数据 的numpy形式
np.savetxt(os.path.join(self.label_path_txt,f'{batch_id}_label.txt'), point_set_without_normal, fmt='%.04f') # 将其存储为txt文件
" points torch.Size([16, 2048, 6]) label torch.Size([16, 1]) target torch.Size([16, 2048])"
assert len(self.model) == len(self.all_pred_txt_path) , '路径与模型数量不匹配,请检查'
for n,model,pred_path in zip(self.model_name,self.model,self.all_pred_txt_path):
seg_pred, trans_feat = model(points, self.to_categorical(label, 16))
seg_pred = seg_pred.cpu().data.numpy()
#=================================================
#seg_pred = np.argmax(seg_pred, axis=-1) # 获得网络的预测结果 b n c
if self.heat_map:
out = np.asarray(np.sum(seg_pred,axis=2))
seg_pred = ((out - np.min(out) / (np.max(out) - np.min(out))))
else:
seg_pred = np.argmax(seg_pred, axis=-1) # 获得网络的预测结果 b n c
#=================================================
seg_pred = np.concatenate([np.asarray(xyz_feature_point), seg_pred[:, None, :]],
axis=1).transpose((0, 2, 1)).squeeze(0) # 将点云与预测结果进行拼接,准备生成txt文件
save_path = os.path.join(pred_path, f'{n}_{batch_id}.txt')
np.savetxt(save_path,seg_pred, fmt='%.04f')
def o3d_draw_3d_img(self):
result_path = os.path.join(self.all_pred_txt_path[0], f'PonintNet_0.txt')
pcd = np.genfromtxt(result_path, delimiter=" ")
pcd_vector = o3d.geometry.PointCloud()
print(self.path)
# 加载点坐标
pcd_vector.points = o3d.utility.Vector3dVector(pcd[:, :3])
colors = np.random.randint(255, size=(50,3))/255
pcd_vector.colors = o3d.utility.Vector3dVector(colors[list(map(int,pcd[:, 6])),:])
o3d.visualization.draw_geometries([pcd_vector])
def pc_normalize(self,pc):
l = pc.shape[0]
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
pc = pc / m
return pc
def make_dir(self, root):
if os.path.exists(root):
print(f'{root} 路径已存在 无需创建')
else:
os.mkdir(root)
def to_categorical(self,y, num_classes):
""" 1-hot encodes a tensor """
new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]
if (y.is_cuda):
return new_y.cuda()
return new_y
def load_cheackpoint_for_models(self,name,model,cheackpoints):
assert cheackpoints is not None,'请填写权重文件'
assert model is not None, '请实例化模型'
for n,m,c in zip(name,model,cheackpoints):
print(f'正在加载{n}的权重.....')
weight_dict = torch.load(os.path.join(c,'best_model.pth'))
m.load_state_dict(weight_dict['model_state_dict'])
print(f'{n}权重加载完毕')
if __name__ =='__main__':
import copy
img_root = r'./data/shapenetcore_partanno_segmentation_benchmark_v0_normal' # 数据集路径
target_root = r'./results/444' # 输出结果路径
path='data/shapenetcore_partanno_segmentation_benchmark_v0_normal/03001627/chair_0011.txt'
num_classes = 50 # 填写数据集的类别数 如果是s3dis这里就填13 shapenet这里就填50
choice_dataset = 'ShapeNet' # 预测ShapNet数据集
# 导入模型 部分
"所有的模型以PointNet++为标准 输入两个参数 输出两个参数,如果模型仅输出一个,可以将其修改为多输出一个None!!!!"
#==============================================
from models.pointnet2_part_seg_msg import get_model as pointnet2
model1 = pointnet2(num_classes=num_classes,normal_channel=True).eval()
#============================================
# 实例化数据集
"Dataset同理,都按ShapeNet格式输出三个变量 point_set, cls, seg # pointset是点云数据,cls十六个大类别,seg是一个数据中,不同点对应的小类别"
"不是这个格式的话就手动添加一个"
if choice_dataset == 'ShapeNet':
print('实例化ShapeNet')
TEST_DATASET = PartNormalDataset(root=img_root, npoints=2048, normal_channel=True,path=path)
testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=1, shuffle=False, num_workers=0,
drop_last=True)
color_map = {idx: i for idx, i in enumerate(np.linspace(0, 0.9, num_classes))}
else:
TEST_DATASET = S3DISDataset(split='test', data_root=img_root, num_point=4096, test_area=5,
block_size=1.0, sample_rate=1.0, transform=None)
testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True, drop_last=True)
color_maps = [(152, 223, 138), (174, 199, 232), (255, 127, 14), (91, 163, 138), (255, 187, 120), (188, 189, 34),
(140, 86, 75)
, (255, 152, 150), (214, 39, 40), (197, 176, 213), (196, 156, 148), (23, 190, 207), (112, 128, 144)]
color_map = []
for i in color_maps:
tem = ()
for j in i:
j = j / 255
tem += (j,)
color_map.append(tem)
print('实例化S3DIS')
model_dict = {'PonintNet': [model1,r'./log/part_seg/pointnet2_part_seg_msg/checkpoints']}
c = Generate_txt_and_3d_img(img_root,target_root,num_classes,testDataLoader,model_dict,color_map,path=path)
把之前的代码改成了针对单个点云预测的可视化,目前仅针对shapenet数据集,懒得优化代码了,可能有些代码有点臃肿,就是看看效果。这里要注意如果训练的时候选择了--normal,那么normal_channel要改成True。零件分割是在已知零件种类的情况下对零件进行分割,因此预测的时候需要载入零件的类型,由于我比较懒,如果要用上面代码进行预测,可以将预测点云的txt文件放入shapenet文件夹对应种类的文件夹中,然后改下path路径就能用来预测其他文件了。
看下训练效果,我这里在modelnet40里把chair的一个文件丢到了shapenet对应文件夹里进行预测。
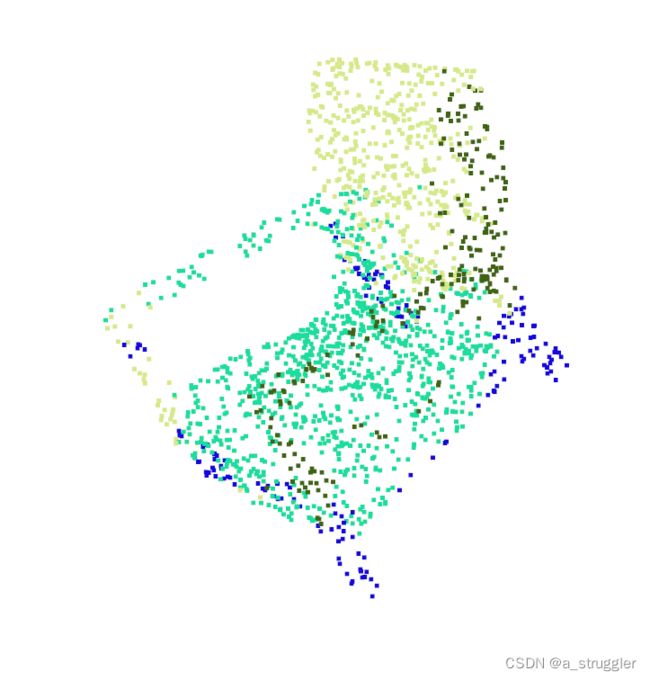


可以看到这个椅子大致是分成了四块,但是椅子靠背、腿分割地挺好的,就是扶手有一部分分割到了坐垫那里了。modelnet40数据集只是用来分类,并没有分割的标注,所以这里可视化了一下shapenet里标注好的椅子点云,看看椅子各个部位的分割(并非上面的椅子)。


这里就比较显而易见地看出椅子分为靠背、扶手、坐垫、腿四个部分。
初步观察到效果以后可以开始尝试自己制作数据集进行训练了,这里就先略过了,之后补上。
场景分割
零件分割网络可以很容易地扩展到语义场景分割,点标记成为语义对象类而不是目标零件标记。
在 Stanford 3D语义分析数据集上进行实验。该数据集包含来自Matterport扫描仪的6个区域的3D扫描,包括271个房间。扫描中的每个点都用13个类别(椅子、桌子、地板、墙壁等加上杂物)中的一个语义标签进行注释。
先把文件下载过来: S3DIS ,存到文件夹data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/.
处理数据,数据会存到data/stanford_indoor3d/。
cd data_utils
python collect_indoor3d_data.py
运行:
## Check model in ./models
## e.g., pointnet2_ssg
python train_semseg.py --model pointnet2_sem_seg --test_area 5 --log_dir pointnet2_sem_seg
python test_semseg.py --log_dir pointnet2_sem_seg --test_area 5 --visual
上面的操作走完以后会在log/sem_seg/pointnet2_sem_seg/visual/生成预测结果的obj文件,可以用open3d进行可视化,就是不能用o3d.io.read_triangle_mesh函数来可视化obj文件,因为这里生成的obj文件还带了颜色信息用来表示语义信息,所以得读取成列表数据然后定义成o3d.geometry.PointCloud()变量显示,代码如下:
import copy
import numpy as np
import open3d as o3d
import os
objFilePath = 'log/sem_seg/pointnet2_sem_seg/visual/Area_5_office_8_gt.obj'
with open(objFilePath) as file:
points = []
while 1:
line = file.readline()
if not line:
break
strs = line.split(" ")
if strs[0] == "v":
points.append(np.array(strs[1:7],dtype=float))
if strs[0] == "vt":
break
# points原本为列表,需要转变为矩阵,方便处理
pcd = np.array(points)
pcd_vector = o3d.geometry.PointCloud()
pcd_vector.points = o3d.utility.Vector3dVector(pcd[:, :3])
pcd_vector.colors = o3d.utility.Vector3dVector(pcd[:,3:6])
o3d.visualization.draw_geometries([pcd_vector])
康康Area_5里office_8的效果:
原图:


ground truth:

predict:


OK,大致算是把这个PointNet++复现完了,分类比较简单就懒得深究了,主要是目前用不到,着重做了下点云分割,给毕设做准备。总的来讲,训练和预测的过程并不难,为了康康效果,可视化的部分倒是花了挺长时间。零件分割和场景分割本质上讲其实是一回事,就是在代码里面这两个分割用了不同的模型来训练。之后打算自己制作数据集来训练一下,先拿零件分割的模型来做,毕竟场景分割做成S3DIS形式的数据集有点麻烦。文章可能有些理解错误,我还没读过原论文。。。但跟着走肯定是能跑通PointNet++的。