使用 mindspore 构建 GoogLeNet 进行图像分类, wandb 进行可视化与超参调优
使用mindspore构建GoogLeNet进行图像分类
-
- 1. GoogLeNet
- 2. 数据读取
-
- 2.1 划分测试集
- 2.2 自定义数据集
- 2.3 创建迭代器
- 3. 训练
-
- 3.1 配置
- 3.2 构建模型
- 3.3 训练结果
- 4. 问题
完整代码: https://github.com/cuiyc2000/mindspore-dogs.vs.cats
训练过程: https://wandb.ai/cugcuiyc/DLFIN/sweeps/hrjlcg1f?workspace=user-cugcuiyc
1. GoogLeNet
官方demo: https://gitee.com/mindspore/models/tree/master/official/cv/googlenet
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""GoogleNet"""
import mindspore.nn as nn
from mindspore.common.initializer import TruncatedNormal, HeNormal
from mindspore.ops import operations as P
def weight_variable():
"""Weight variable."""
# return TruncatedNormal(0.02)
return HeNormal()
def bias_variable():
"""Weight variable."""
return TruncatedNormal(0.02)
# return HeNormal()
class Conv2dBlock(nn.Cell):
"""
Basic convolutional block
Args:
in_channles (int): Input channel.
out_channels (int): Output channel.
kernel_size (int): Input kernel size. Default: 1
stride (int): Stride size for the first convolutional layer. Default: 1.
padding (int): Implicit paddings on both sides of the input. Default: 0.
pad_mode (str): Padding mode. Optional values are "same", "valid", "pad". Default: "same".
Returns:
Tensor, output tensor.
"""
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, pad_mode="same"):
super(Conv2dBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, pad_mode=pad_mode, weight_init=weight_variable())
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
self.relu = nn.ReLU()
def construct(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Inception(nn.Cell):
"""
Inception Block
"""
def __init__(self, in_channels, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes):
super(Inception, self).__init__()
self.b1 = Conv2dBlock(in_channels, n1x1, kernel_size=1)
self.b2 = nn.SequentialCell([Conv2dBlock(in_channels, n3x3red, kernel_size=1),
Conv2dBlock(n3x3red, n3x3, kernel_size=3, padding=0)])
self.b3 = nn.SequentialCell([Conv2dBlock(in_channels, n5x5red, kernel_size=1),
Conv2dBlock(n5x5red, n5x5, kernel_size=3, padding=0)])
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, pad_mode="same")
self.b4 = Conv2dBlock(in_channels, pool_planes, kernel_size=1)
self.concat = P.Concat(axis=1)
def construct(self, x):
branch1 = self.b1(x)
branch2 = self.b2(x)
branch3 = self.b3(x)
cell = self.maxpool(x)
branch4 = self.b4(cell)
return self.concat((branch1, branch2, branch3, branch4))
class GoogLeNet_backbone(nn.Cell):
"""
Googlenet architecture
"""
def __init__(self):
super(GoogLeNet_backbone, self).__init__()
self.conv1 = Conv2dBlock(3, 64, kernel_size=7, stride=2, padding=0)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same")
self.conv2 = Conv2dBlock(64, 64, kernel_size=1)
self.conv3 = Conv2dBlock(64, 192, kernel_size=3, padding=0)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same")
self.block3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.block3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same")
self.block4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.block4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.block4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.block4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.block4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode="same")
self.block5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.block5b = Inception(832, 384, 192, 384, 48, 128, 128)
# self.dropout = nn.Dropout(keep_prob=0.8)
# self.dropout = nn.Dropout(keep_prob=1.)
def construct(self, x):
"""construct"""
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.block3a(x)
x = self.block3b(x)
x = self.maxpool3(x)
x = self.block4a(x)
x = self.block4b(x)
x = self.block4c(x)
x = self.block4d(x)
x = self.block4e(x)
x = self.maxpool4(x)
x = self.block5a(x)
x = self.block5b(x)
return x
class GoogLeNet_head(nn.Cell):
def __init__(self, num_classes):
super(GoogLeNet_head, self).__init__()
self.mean = P.ReduceMean(keep_dims=True)
self.flatten = nn.Flatten()
self.classifier = nn.Dense(1024, num_classes, weight_init=weight_variable(), bias_init=bias_variable())
def construct(self, x):
x = self.mean(x, (2, 3))
x = self.flatten(x)
x = self.classifier(x)
return x
class GoogLeNet(nn.Cell):
def __init__(self, num_classes=2, backbone=None, head=None):
super(GoogLeNet, self).__init__()
if backbone is None:
self.backbone = GoogLeNet_backbone()
else:
self.backbone = backbone
if head is None:
self.head = GoogLeNet_head(num_classes)
else:
self.head = head
def construct(self, x):
x = self.backbone(x)
x = self.head(x)
return x
以上做了点小修改: 将骨干网络和训练头分离, 后续将用 backbone 提取特征, 用 SVM 进行分类.
2. 数据读取
猫狗大战数据集, 下载链接: https://www.kaggle.com/competitions/dogs-vs-cats/data

2.1 划分测试集
官网数据集 test 文件夹是没有真实标签的, 需要用户预测并提交. 因此从 train 文件夹中手动划分出训练测试集.
def gen_dataset(data_path, save_path, test_size=0.2, random_seed=22):
"""
! arc decompress dogs-vs-cats.zip
:param data_path: /root/autodl-tmp/PycharmProjects/code/dataset/train
:param save_path: ../dataset
:param test_size:
:param random_seed:
:return:
"""
cat_list = glob.glob(os.path.join(data_path, "cat*"))
dog_list = glob.glob(os.path.join(data_path, "dog*"))
X = np.append(cat_list, dog_list)
y = np.append(np.ones(len(cat_list)), np.zeros(len(dog_list)))
X_train, X_test, _, _ = train_test_split(X, y, test_size=test_size, random_state=random_seed, stratify=y)
with open(os.path.join(save_path, "train.list"), "w") as f:
f.write("\n".join(X_train))
f.close()
with open(os.path.join(save_path, "test.list"), "w") as f:
f.write("\n".join(X_test))
f.close()
print("train file in ", os.path.join(save_path, "train.list"))
print("test file in ", os.path.join(save_path, "test.list"))
if __name__ == '__main__':
gen_dataset("/root/autodl-tmp/PycharmProjects/code/dataset/train", "../dataset")
train.list 和 test.list 各自保存了训练和测试图片的路径. gen_dataset 第一个参数为 train 文件夹的路径, 第二个参数为train.list 和 test.list 的保存路径. 训练的时候将只用这两个文件.
2.2 自定义数据集
mindspore 在用户自定义数据集类中须要自定义类函数, 见: https://www.mindspore.cn/tutorials/zh-CN/r1.7/advanced/dataset/custom.html
class PetData:
def __init__(self, file_list):
with open(file_list) as f:
self.img_list = f.read().splitlines()
f.close()
def __getitem__(self, item):
img_path = self.img_list[item]
img = Image.open(img_path)
label = 0 if img_path.split("/")[-1].split(".")[0] == "cat" else 1
return img, label
def __len__(self):
return len(self.img_list)
file_list 就是上述train.list 和 test.list
2.3 创建迭代器
定义好数据集的类之后, 需要用mindspore的 ds.GeneratorDataset 传入实例化后的类, 返回类似于 pytorch 中自定义的 DataLoader 的一个迭代器.
def create_dataset(file_list, train=True, batch_size=1, shuffle=True):
dataset_generator = PetData(file_list)
if shuffle:
cores = max(min(multiprocessing.cpu_count(), 8), 1)
dataset = ds.GeneratorDataset(dataset_generator, ["image", "label"], shuffle=True, num_parallel_workers=cores)
else:
dataset = ds.GeneratorDataset(dataset_generator, ["image", "label"], shuffle=False, num_parallel_workers=1)
RGB_mean = [124.479, 116.011, 106.281]
RGB_std = [66.734, 65.031, 65.683]
if train:
trans = [
CV.Resize([256, 256]),
CV.RandomCrop([224, 224]),
CV.Normalize(RGB_mean, RGB_std),
CV.RandomHorizontalFlip(),
CV.HWC2CHW()
]
else:
trans = [
CV.Resize([256, 256]),
CV.Normalize(RGB_mean, RGB_std),
CV.HWC2CHW()
]
typecast_op = C.TypeCast(mstype.int32)
dataset = dataset.map(input_columns='label', operations=typecast_op)
dataset = dataset.map(input_columns='image', operations=trans)
dataset = dataset.batch(batch_size, drop_remainder=False)
return dataset
3. 训练
3.1 配置
使用 yacs 进行训练参数的管理:
from yacs.config import CfgNode as CN
_C = CN()
_C.WANDB = CN()
_C.WANDB.OPEN = True
_C.WANDB.PROJECT_NAME = "DLFIN"
_C.WANDB.ENTITY = "cugcuiyc"
_C.WANDB.RESUME = False
_C.WANDB.LOG_DIR = ""
_C.WANDB.SWEEP_CONFIG = "./config.json"
_C.MODEL = CN()
_C.MODEL.NAME = "GoogLeNet"
_C.DATASET = CN()
_C.DATASET.NAME = "dogs.vs.cats"
_C.TRAIN = CN()
_C.TRAIN.TRAIN_LIST = "./dataset/train.list"
_C.TRAIN.TEST_LIST = "./dataset/test.list"
_C.TRAIN.SAVE_PATH = "./checkpoints"
def get_cfg_defaults():
return _C.clone()
cfg = _C
使用 wandb 进行超参调优和训练可视化, 版本 0.12.16. ./config.json 为 wandb sweep 的配置:
{
"googlenet": {
"sweep_config": {
"method": "grid",
"metric": {
"name": "max test acc",
"goal": "maximize"
},
"parameters": {
"optimizer": {
"values": ["adam", "sgd", "adagrad", "momentum"]
},
"lr": {
"values": [0.001, 0.005, 0.0005, 0.0001]
},
"batch_size": {
"values": [32, 16, 8]
}
}
}
}
}
3.2 构建模型
class GoogLeNetModel:
def __init__(self, opt):
self.opt = opt
self.model_name = "model_{}".format(self.opt.MODEL.NAME)
batch_list = [8, 16, 32]
self.train_set_dict = {i: create_dataset(self.opt.TRAIN.TRAIN_LIST, train=True, batch_size=i, shuffle=False) for i in batch_list}
self.train_set_iter_dict = {k: v.create_dict_iterator() for k, v in self.train_set_dict.items()}
self.eval_train_set = create_dataset(self.opt.TRAIN.TRAIN_LIST, train=False, batch_size=64, shuffle=False)
self.eval_test_set = create_dataset(self.opt.TRAIN.TEST_LIST, train=False, batch_size=64, shuffle=False)
self.eval_train_set_iter = self.eval_train_set.create_dict_iterator()
self.eval_test_iter = self.eval_test_set.create_dict_iterator()
self.net = GoogLeNet(2)
self.global_max_acc = 0
def run_sweep(self):
setup_seed(22)
self.opt.WANDB.LOG_DIR = os.path.join("./logs/", self.model_name)
with wandb.init(name=self.model_name,
config=self.opt,
notes=self.opt.WANDB.LOG_DIR,
resume=self.opt.WANDB.RESUME,
) as run:
config = wandb.config
wandb.run.name = "_".join([self.model_name, config["optimizer"], str(config["lr"]), str(config["batch_size"])])
num_epoch = self.opt.TRAIN.NUM_EPOCH
init_weights_path = './checkpoints/init_{}.ckpt'.format(self.model_name)
if os.path.exists(init_weights_path):
print("loading existed initial weights [ {} ] to net...".format(init_weights_path))
load_checkpoint(init_weights_path, net=self.net)
else:
print("saving initial weights [ {} ] from net...".format(init_weights_path))
save_checkpoint(self.net, init_weights_path)
loss = nn.loss.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
opt = self.build_optim(config["optimizer"], config["lr"])
network = nn.WithLossCell(self.net, loss)
network = nn.TrainOneStepCell(network, opt)
batch_size = config["batch_size"]
assert batch_size in [8, 16, 32]
train_set = self.train_set_dict[batch_size]
train_set_iter = self.train_set_iter_dict[batch_size]
max_acc = 0
for epoch in range(num_epoch):
bar = tqdm(train_set_iter, total=train_set.get_dataset_size(), ncols=100)
for idx, dic in enumerate(bar):
input_img = dic['image']
loss = network(input_img, dic['label'])
if self.opt.WANDB.OPEN:
wandb.log({"loss": loss.asnumpy()})
bar.set_description_str(
"training: epcoh:{}/{}, idx:{}/{}, loss:{:.6f}".format(epoch + 1, num_epoch, idx + 1,
train_set.get_dataset_size(),
loss.asnumpy()))
train_acc = self.eval(self.eval_train_set_iter)
test_acc = self.eval(self.eval_test_iter)
acc = {"epoch": epoch + 1, "train acc": train_acc, "test acc": test_acc}
print(acc)
if test_acc > max_acc:
max_acc = test_acc
print("max test acc: ", max_acc)
if max_acc > self.global_max_acc:
self.global_max_acc = max_acc
print("global max test acc: ", self.global_max_acc)
self.save_checkpoints()
if self.opt.WANDB.OPEN:
wandb.log(acc)
if self.opt.WANDB.OPEN:
wandb.log({"max test acc": max_acc})
def sweep(self):
with open(self.opt.WANDB.SWEEP_CONFIG, encoding="utf-8") as f:
self.sweep_config = json.load(f)
f.close()
sweep_id = wandb.sweep(self.sweep_config["googlenet"]["sweep_config"], project=self.opt.WANDB.PROJECT_NAME)
wandb.agent(sweep_id, self.run_sweep)
def eval(self, data_iter):
y_test, y_pred = [], []
for idx, dic in enumerate(data_iter):
input_img = dic['image']
output = self.net(input_img)
predict = np.argmax(output.asnumpy(), axis=1)
y_test += list(dic['label'].asnumpy())
y_pred += list(predict)
test_acc = accuracy_score(y_pred, y_test)
return test_acc
def build_optim(self, optim, lr):
optimizer = None
if optim == "sgd":
optimizer = nn.SGD(self.net.trainable_params(), lr)
elif optim == "adam":
optimizer = nn.Adam(self.net.trainable_params(), lr)
elif optim == "adagrad":
optimizer = nn.Adagrad(self.net.trainable_params(), lr)
elif optim == "momentum":
optimizer = nn.Momentum(self.net.trainable_params(), lr, momentum=0.9)
return optimizer
def save_checkpoints(self):
save_checkpoint(self.net, os.path.join(self.opt.TRAIN.SAVE_PATH, self.model_name + '_best_param.ckpt'))
save_checkpoint(self.net.backbone, os.path.join(self.opt.TRAIN.SAVE_PATH, self.model_name + '_best_param_backbone.ckpt'))
print("saving param...")
__init__ 中的 opt 为 3.1 中的配置, 因为 batch size 有 8, 16, 32 , 所以直接在初始化时全部创建, 注意不能创建多次, 不然会 OOM . eval 函数在训练集和测试集上进行推理, 返回正确率. build_optim 为根据配置选择构建优化器, save_checkpoints 保存模型, sweep 为 wandb 执行超参调优的操作, run_sweep 为寻优的一次操作. 方法具体见: https://docs.wandb.ai/guides/sweeps
3.3 训练结果
import argparse
from config import get_cfg_defaults
from models.googlenetmodel import GoogLeNetModel
from utils.model_utils import setup_seed
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", "-e", default=20, type=int)
parser.add_argument("--wandb", "-w", default=False, action="store_true")
args = parser.parse_args()
if __name__ == "__main__":
setup_seed(22)
cfg = get_cfg_defaults()
cfg.WANDB.OPEN = args.wandb
cfg.TRAIN.NUM_EPOCH = args.epoch
print(cfg)
print()
assert cfg.MODEL.NAME.lower() in ["googlenet", "softmax"]
trainer = GoogLeNetModel(cfg)
trainer.sweep()
mindspore 版本为 mindspore-gpu 1.6.1 , 执行 python -w -e 20 训练 20 个 epoch:
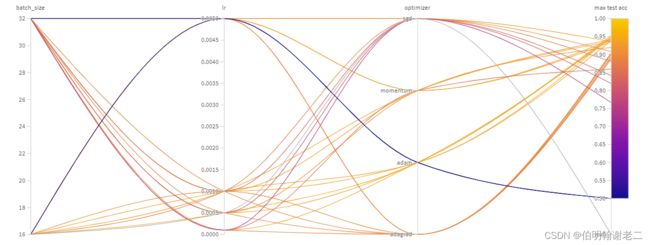
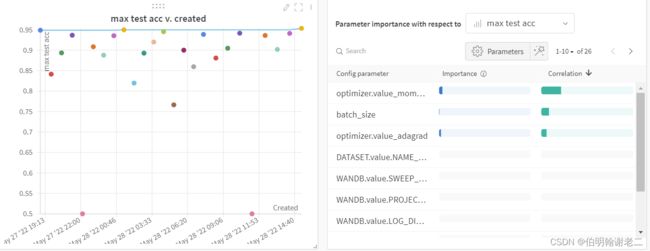

测试集正确率最高能到大约96%
4. 问题
已经固定随机数种子, 参照官网, dropout 没有加, 初始权重保存下来使用, 但是每次运行不能复现上次的结果, 每次运行始终有较大出入, 原因暂时未知.