I3D模型_2017_CVPR
作者的观点:
若在足够大的视频动作识别数据集上训练(Kinetics),是否能提升模型在其他数据集(HMDB-51,UCF-101)上的表现呢?
论文核心内容:
- 对于不同模型,这种方法(见观点)提升性能程度相差很大,于是提出 Two-Stream Inflated 3D ConvNet ( I3D ) 模型
- 实验分析,现有最好的动作识别方法在数据集Kinetics上的表现,其次是在对Kinetics进行预训练之后,对较小的基准数据集的性能有多大提高。
- I3D模型之所以会有如此好的表现,是因为该模型具有很高的时间分辨率。即输入的训练帧数多。(它们以每秒25帧的速度训练64帧视频片段,并在测试时处理所有视频帧,这使得它们可以捕获细粒度的时间动作结构。)
论文主要贡献:
- 提出一种新模型I3D,基于2D卷积网络的增强版。
- 在视频动作识别数据集上训练(Kinetics),获得的网络可以提升模型在其他数据集(HMDB-51,UCF-101)上的表现。
展望/待解决问题:
- 对于其他视频任务(例如语义视频分割,视频对象检测或光流计算)使用Kinetics预训练是否有益仍有待观察。【研究点!!!】
- 作为未来的工作,我们计划使用Kinetics而不是miniKinetics重复所有实验,使用和不使用ImageNet预训练,并探索inflat其他的2D ConvNets
1.Introduction
I3D:以最新的图片分类模型为基础结构,将kernels膨胀(inflate)结合到3D Conv。基于2D卷积网络的增强版。将非常深图片的卷积分类的卷积核与池化核扩展为3D,使得可以从视频中学习无缝的时空特征提取器,同时利用成功的ImageNet架构设计甚至其参数。
2 Action Classification Architectures
2.2 The Old II: 3D ConvNets
在这篇文章中,作者提出一种C3D的变体,它包括8个卷积层,5个池化层和两个全连接层。输入是从视频中截取的大小为112*112共16帧的片段。使用批正则化(batch normalization)的方法。不同于C3D,该方法在第一个池化层使用的temporal strde为2而不是1,这种改进减少内存占用并允许更大批量。
2.3. The Old III: Two-Stream Networks
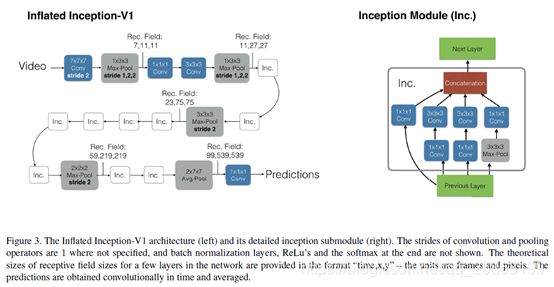
I3D模型也参考了Two-Stream,还结合了 Inception-V1,网络的输入为相隔10帧的5个连续RGB帧,以及相应的光流片段。在Inception-V1的最后一个平均合并层(5×7×7特征网格,对应于时间,x和y维度)之前的空间和运动特征通过具有512个输出通道的3×3×3 3D卷积层, 然后是3×3×3 3D最大池层并通过最终的完全连接层。
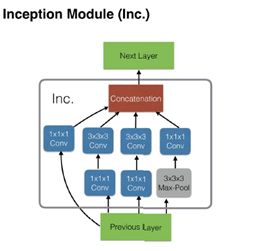
2.4 The New : Two-Stream Inflated 3D ConvNet
3D ConvNets能直接从RGB流中学习时域信息模式,当再加上输入光流,这个性能将进一步提升。
Inflating 2D ConvNets into 3D
简单的将成功的2D分类器扩展为3D卷积。卷积层(N*N)和池化层(N*N)都增加一个时间维度(N*N*N)。
Bootstrapping 3D filters from 2D Filters
3D卷积核的参数可以通过ImageNet模型学习,通过将ImageNet上的2D图片重复叠加成一个连续的视频。
Pacing receptive field growth in space, time and network depth
这个boring video fixed-point使得调整网络变得相当灵活,可以根据时间维度膨胀池化层操作,也可以设置卷积层或池化层的temporal stride。
Two 3D Streams
虽然I3D网络能直接从RGB输入中学习运动特征,但它始终只是执行前馈计算,而光流算法在某种意义上是周期性的计算。所以实验设计,分别在RGB和光流两种输入上训练I3D,最后作平均再预测。
2.5 Implementation Details
除了C3D模型之外,所有模型都使用ImageNet预训练Inception-V1的到基础网络。除了最后一层卷积层外(需计算出全连接层得到分类结果),在模型中的其它卷积层后,紧跟着batch normalization(批处理)和 ReLU激活函数。
3.The Kinetics Human Action Video Dateset
大致介绍Kinetics数据集,本文并没有使用完整的Kinetics进行训练。而是使用其中数据集的小一部分(miniKinetics)。
4.Experimental Comparison of Architectures
实验比较第二部分中的几种结构在不同数据集下的表现。

实验得到几个很有价值的信息:
- 在ImageNet上进行模型预训练,同样会对3D ConvNets有帮助。(在别的视频处理应用中,能否用得上??)
- 实际探究Kinetics数据集发现,其中视频具有更多的摄像机运动,这可能Flow的工作更加困难。所以在miniKinetics上的Flow精度低于RGB精度。

从上图可看出,I3D模型比其他模型在对Flow输入处理时更有优势。(可能是I3D有longer temporal receptive 和更集成的时间特征提取机制)
作者认为,RGB流具有更多的辨别力,相反却很难用自己的眼睛从Flow流(Kinetics数据集)中辨别视频中的动作。这也许是未来研究的一个方向——整合某种形式的运动稳定到这些架构中。
5. Experimental Evaluation of Features
这部分主要内容是,研究Kenetics上训练的网络的泛化能力。
文中设计了两种方法:
(这两种方法的网络都在Kenetics上预训练)
- 通过固定网络的权重,使用网络模型处理UCF-101/HMDB-51数据集,得到结果①。接下来使用UCF-101/HMDB-51的训练集训练网络模型的multi-way soft-max 分类器,然后在测试集上验证。
- 用UCF-101/HMDB-51 微调网络,然后在测试集上评估性能。

以上模型中,除了3D-ConvNet之外,都是基于Inception-v1模块,而且在ImageNet上预训练。
Original:在当前数据上训练,再进行验证。
Full-FT:在miniKinetics上预训练,再在各自处理的数据集上微调。
在mini-Kenetics(固定)预训练后训练模型的最后几层也比直接训练UCF-101和HMDB-51的I3D模型具有更好的性能。
5.1 Comparison with the State-of-the-Art
在UCF-101和HMDB-51上,比较I3D与现有最好的模型的性能,
6.Discussion
本文证明在视频处理方面也能像图片处理一样,进行迁移学习。即在更大的数据集(Kenetics)上预训练,然后提高网络在其他数据集(UFC-101/HMDB-51)上识别性能。对于其他视频任务(例如语义视频分割,视频对象检测或光流计算)使用Kinetics预训练是否有益仍有待观察。【研究点!!!】
作为未来的工作,我们计划使用Kinetics而不是miniKinetics重复所有实验,使用和不使用ImageNet预训练,并探索膨胀其他状态的2D ConvNets
【论文笔记下载地址】
链接: https://pan.baidu.com/s/1sU4lr8mjCCh2llR263_YgQ
提取码: 64mq