文本特征抽取
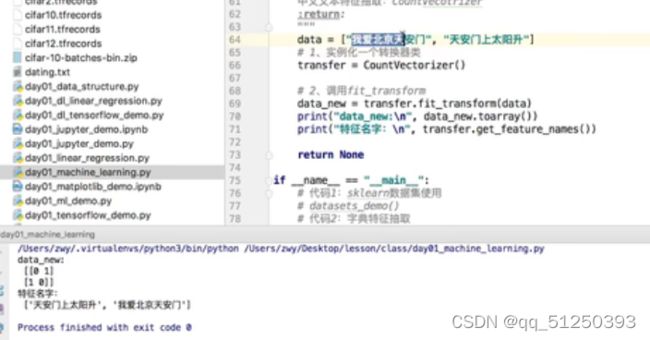
注意中文一整句话会被认为一个feature_name,应该用空格隔开
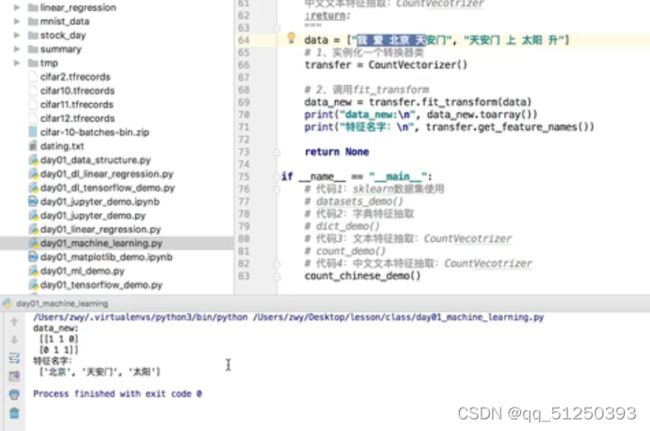
#设置停用词stop_words可以将某个feature_name去掉
停用词表中的词会自动不出现在feature_names特征列表中
(34条消息) 最全英文停用词表整理(891个)_以家为家,以乡为乡,以国为国,以天下为天下-CSDN博客_英文停用词表
(34条消息) 中文停用词词表_BigDiaos的博客-CSDN博客
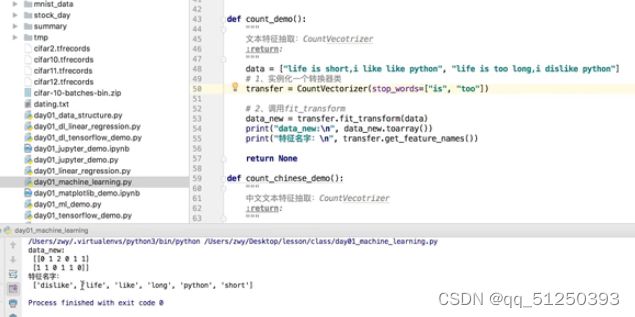
def count_demo():
data = ["life is short,i like like python", "life is too long,i dislike python"]
transfer=CountVectorizer()
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new)#sparse矩阵自带toarray()函数
print("data_new:\n",data_new.toarray())
print("特征名字:\n",transfer.get_feature_names())
if __name__=="__main__":
count_demo()data_new:
(0, 2) 1
(0, 1) 1
(0, 6) 1
(0, 3) 2
(0, 5) 1
(1, 2) 1
(1, 1) 1
(1, 5) 1
(1, 7) 1
(1, 4) 1
(1, 0) 1
data_new:
[[0 1 1 2 0 1 1 0]
[1 1 1 0 1 1 0 1]]
特征名字:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']注意单个字母如i或者单个汉字如我不会被列入featrue_names
![]()
![]()
生成一个生成器
![]()

![]()

def count_chinese_demo():
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new=[]
for sent in data:
print("\n",sent)
if __name__=="__main__":
count_chinese_demo()结果:
一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。
我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。
如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。
def cut_word(text):
text=" ".join(list(jieba.cut(text)))
return text
def count_chinese_demo():
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new=[]
for sent in data:
data_new.append(cut_word(sent))
transfer=CountVectorizer()#设置停用词可以将某个feature_name去掉
data_final=transfer.fit_transform(data_new)
print("data_new:\n",data_final.toarray())
print("特征名字:\n",transfer.get_feature_names())
if __name__=="__main__":
count_chinese_demo()结果:
data_new:
[[2 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 1
0]
[0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 0
1]
[1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0
0]]
C:\Users\34935\PycharmProjects\pythonProject1\venv\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
warnings.warn(msg, category=FutureWarning)
特征名字:
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '还是', '这样']
def tfidf_demo():
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new=[]
for sent in data:
data_new.append(cut_word(sent))
transfer=TfidfVectorizer()#设置停用词可以将某个feature_name去掉
data_final=transfer.fit_transform(data_new)
print("data_new:\n",data_final.toarray())
print("特征名字:\n",transfer.get_feature_names())
if __name__=="__main__":
tfidf_demo()结果:
data_new:
[[0.30847454 0. 0.20280347 0. 0. 0.
0.40560694 0. 0. 0. 0. 0.
0.20280347 0. 0.20280347 0. 0. 0.
0. 0.20280347 0.20280347 0. 0.40560694 0.
0.20280347 0. 0.40560694 0.20280347 0. 0.
0. 0.20280347 0.20280347 0. 0. 0.20280347
0. ]
[0. 0. 0. 0.2410822 0. 0.
0. 0.2410822 0.2410822 0.2410822 0. 0.
0. 0. 0. 0. 0. 0.2410822
0.55004769 0. 0. 0. 0. 0.2410822
0. 0. 0. 0. 0.48216441 0.
0. 0. 0. 0. 0.2410822 0.
0.2410822 ]
[0.12001469 0.15780489 0. 0. 0.63121956 0.47341467
0. 0. 0. 0. 0.15780489 0.15780489
0. 0.15780489 0. 0.15780489 0.15780489 0.
0.12001469 0. 0. 0.15780489 0. 0.
0. 0.15780489 0. 0. 0. 0.31560978
0.15780489 0. 0. 0.15780489 0. 0.
0. ]]
特征名字:
C:\Users\34935\PycharmProjects\pythonProject1\venv\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '还是', '这样']
warnings.warn(msg, category=FutureWarning)值越大说明越重要
def minmax_demo():
data=pd.read_csv("dating.txt")
data=data.iloc[:,:3]
transfer=MinMaxScaler()
data_new=transfer.fit_transform(data)
print(data_new)
return None
结果:
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]
注意中文一整句话会被认为一个feature_name,应该用空格隔开