Data mining数据挖掘——FPTree
Data mining数据挖掘——FPTree
定义就不解释了,这里只说思路和代码。
以下是我对FPtree算法的个人见解,欢迎指正,共勉。
思路
FPtree是为了解决apriori频繁访问数据库的缺点,它主要有两个过程:1、build-FPtree、2、growth-FPtree
以一个例子来介绍它的思想,事务库初始如下,最小支持度的阈值是2:
a b e
b d
b c
a b d
a c
b c
a c
a b c e
a b c
一、build-FPtree
准备工作:
1、首先我们对出现的每个item进行统计其支持度(相当于频繁1-项目集),并删除小于阈值的item,最后对其进行排序:
b=====>7
c=====>6
a=====>6
e=====>2
d=====>2
2、利用1)的结果对原始数据做两点操作:删除非频繁1-项目集元素和按照支持度重新对每条事务进行排序:
排序整理后的项目集:
b a e
b d
b c
b a d
c a
b c
c a
b c a e
b c a
建FPtree
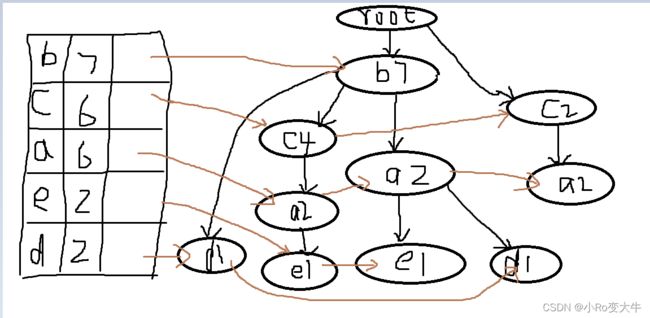
总的一条就是共前缀!例如bae和bad就可以共ba,这样它们的计数为b2、a2、d1;但是bca和ca就不能共前缀!!!
二、growth-FPtree
核心思想:
FP-growth(tree,a)
{
if(tree只包含单个路径){
对于路径中的所有结点,找到它们组合的所有情况,对于每种情况(B),将a并入到其中,此时每种情况就是一个频繁项目,它的支持度为B中结点的最小支持度,将每个B(含有a的B)加入到频繁项目集中
}
else{
if(a(后缀式)!=null){
将a与分别与此时项头表中的每个元素进行组合,并加入到频繁项目集中,其支持度为项头表中元素的支持度
}
for each ai 在FP-tree的项表头(倒序) do begin
{
(1)产生一个模式B=(ai并a),a为null,则将它视为空字符串
(2)构造B的条件模式基,然后构造B的条件FP-tree TreeB
(3)if TreeB != null
{
FP-growth(TreeB,B)
}
}
}
}
初看会觉得很复杂难懂,将下面例子看完后,再来看这个伪代码,会有意外收获!
1、第一次调用growth-FPtree的时候,后缀式a为空,于是找到项头表的最后一个元素d,找到它的条件模式基,所谓的条件模式基,就是沿着每个d结点,往上找,直到root结点,其中路径经过的结点组合在一起就为d的一个条件模式基(不含d),这个条件模式基(不含d)的support就是d的support,本例题d的条件模式基为:{(ba,1)(b,1)}
构建d的条件FPtree,这个过程相当于将条件模式基看成一个新的事务库,对其进行build-FPtree过程,先删除非频繁项目集a,只有一个元素b所以就不用排序,得到:

再对其进行growth-FPtree过程(此时的后缀式为元素d),由于它是单路径的,所以根据伪代码,将单路径仅有的元素b与后缀式组合得到一个频繁项目,(bd)
2、处理表头项的倒数第二个元素e,此时还是属于第一次调用growth-FPtree的时候,后缀式还是空;
找到e的条件模式基:{(ba,1)(bca,1)}
构造条件FPtree:

再对其进行growth-FPtree过程(此时的后缀式为元素d),由于它是单路径的,所以根据伪代码,将单路径上的所有结点进行组合(b、a、ba)并分别再与后缀式组合得到频繁项目集,{ be ae bae}
3、处理表头项的倒数第三个元素a,此时还是属于第一次调用growth-FPtree的时候,后缀式还是空;
找到a的条件模式基:{(b,2)(c,2)(bc,2)}
构造条件FPtree:

再对其进行growth-FPtree过程(此时的后缀式为元素a),它不是单路径并且后缀式不为空,根据伪代码,将后缀式a与项表头的每个元素进行组合(ba、ca),并将其加入到频繁项目集中;
此时这部分并没有结束,还得对上项表头中的元素进行build-FPtree过程,
1)找到c的条件模式基{(b,2) },构建FPtree:

对其进行growth-FPtree,(此时的后缀式为ca),它是单路径且后缀式不为空,根据伪代码,得到组合(bca,2),将其加入到频繁项目集中;
2)找到b的条件模式基{ },发现它为空,不做处理;
4、…
…
注意:后面的d、e与b、c类似。a才是重点,理解了a的处理过程才是对FPtree算法的真正理解!!!还有最重要的一点,表头项顺序不一样(支持度相等的元素的顺序),过程结果会有差异,但是最后的频繁项目集几乎都是一样的!!!!!!!!!!!!!!!!!!!!!
代码
本代码用java编写,输入方式采用的是读文件的形式,本菜鸟编码能力有限,可能繁化了一些操作,(最后我也不想再对代码进行优化了…个人觉得这个算法的编码还是有点难度的!!!肝了我五六个小时,这也足以证明我有多菜了吧哈哈)
package myDataMining;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.*;
public class myFPtree {
// 每个结点的信息,自定义的数据结构
public static class TreeNode{
// 节点类别名称
private String name;
// 计数数量
private Integer count;
// 父亲节点
private TreeNode parentNode;
// 孩子节点,可以为多个
private ArrayList<TreeNode> childNodes=new ArrayList<>();
private TreeNode left;
public TreeNode(){
}
public TreeNode(String name,int count){
this.name=name;
this.count=count;
}
}
//定义的一些全局变量
// 记录所有的事务
public static List<List<String>> record=new ArrayList<List<String>>();
// 事物总条数
public static Integer totalT;
// 最小支持数的阈值
public static double MIN_SUPPORT;
// 记录每个item出现的次数,以便得到orderedRecord
public static Map<String,Integer> ItemsCount =new HashMap<String,Integer>();
// 排序后的项目集
// 项表头
public static List<TreeNode> form;
// 记录过程中产生的频繁集
public static Map<String,Integer> frequentSet=new HashMap<>();
//
private static List<List<String>> orderedRecord;
//从文件夹读数据,每次读一行存储
public static List<List<String>> getRecord(String url){
List<List<String>> record = new ArrayList<List<String>>();
try {
String encoding = "UTF-8";
File file = new File(url);
if (file.isFile() && file.exists()) {
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTXT = null;
int t=0;
while ((lineTXT = bufferedReader.readLine()) != null) {//读一行文件
t++;
String[] lineString = lineTXT.split(" ");
List<String> lineList = new ArrayList<String>();
for (int i = 0; i < lineString.length; i++) {
lineList.add(lineString[i]);
if(ItemsCount.containsKey(lineString[i])){
Integer count = ItemsCount.get(lineString[i]);
ItemsCount.put(lineString[i],++count);
}
else {
ItemsCount.put(lineString[i],1);
}
}
record.add(lineList);
}
totalT=t;
read.close();
} else {
System.out.println("找不到指定的文件!");
}
} catch (Exception e) {
System.out.println("读取文件内容操作出错");
e.printStackTrace();
}
return record;
}
public static void main(String[] args){
// C:\Users\LUOJUN\Desktop\test
System.out.println("请输入最小支持度:");
Scanner scanner = new Scanner(System.in);
MIN_SUPPORT=scanner.nextDouble();
System.out.println("请输入待处理的文件地址:");
String url = scanner.next();
record = getRecord(url);
if(record.isEmpty())
{
System.out.println("程序结束!!!");
return;
}else {
System.out.println("读取数据成功!!!!!!!!!总共有"+totalT+"条数据");
for (List<String> stringList : record) {
for (String s : stringList) {
System.out.print(s+" ");
}
System.out.println();
}
System.out.println("当前最小支持度的阈值为"+MIN_SUPPORT+";现在对小于阈值的item进行处理,结果如下");
Iterator<Map.Entry<String, Integer>> iterator = ItemsCount.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
if(next.getValue()<MIN_SUPPORT){
iterator.remove();
}
}
for(Map.Entry<String,Integer> entry:ItemsCount.entrySet()){
System.out.println(entry.getKey()+"===>"+entry.getValue());
}
// 排序整理后的项目集
TreeNode root=new TreeNode();
form= buildFPtree(root,record,ItemsCount);
System.out.println("下面对出现过的item进行排序:");
for (TreeNode treeNode : form) {
System.out.println(treeNode.name+"=====>"+treeNode.count);
}
System.out.println("排序整理后的项目集:");
for (List<String> stringList : orderedRecord) {
for (String s : stringList) {
System.out.print(s+" ");
}
System.out.println();
}
FPgrowth(root,null,form);
System.out.print("频繁项目集为:{");
for(Map.Entry<String,Integer> entry:frequentSet.entrySet()){
System.out.print(" "+entry.getKey());
}
System.out.println("}");
System.out.println("======================================");
}
}
private static void FPgrowth(TreeNode root, String o,List<TreeNode> form) {
// 如果tree只有一条路径,则将form表头项中的所有元素与o组合加入到频繁项目集中
if(TreeOnlyOnePath(root)){
System.out.print("后缀式"+o+"的频繁项目集有:{");
ArrayList<String> strings = new ArrayList<>();
String s="";
for(int i=0;i<form.size();i++){
s=s+form.get(i).name;
}
String s1="";
strings.add(s1);
for(int i=0;i<s.length();i++){
int size = strings.size();
for(int j=0;j<size;j++){
String s2 = strings.get(j);
strings.add(s2+s.charAt(i));
}
}
strings.remove(0);
for (String string : strings) {
int last = string.length() - 1;
String c = String.valueOf(string.charAt(last));
int count=0;
for (TreeNode treeNode : form) {
if(treeNode.name.equals(c)){
count=treeNode.count;
}
}
System.out.print(" "+string+o);
frequentSet.put(string+o,count);
}
System.out.println("}");
System.out.println("======================================");
}
// 如果tree不是单路径
else {
if(o==null){
// 第一次进入这个方法没有后缀式
o="";
}
else {
// 有后缀式,并将其与form表头项中的元素组合加入到频繁集中
System.out.print("后缀式"+o+"的频繁项目集有:{");
for (TreeNode treeNode : form) {
frequentSet.put(treeNode.name+o,treeNode.count);
System.out.print(" "+treeNode.name+o);
}
System.out.println("}");
}
// tree有多路径,所以需要继续挖掘,条件模式相当于源数据,基于条件模式要继续建树,直到tree为单路径
for(int i=form.size()-1;i>=0;i--){
TreeNode formNode = form.get(i);
TreeNode p=formNode.left;
Map<ArrayList<String>,Integer> conditionPatternSet = new HashMap<>();
while (p!=null){
ArrayList<String> list = new ArrayList<>();
TreeNode q=p.parentNode;
Stack<String> stack = new Stack<>();
while (q.parentNode!=null){
stack.push(q.name);
q=q.parentNode;
}
while (!stack.isEmpty()){
list.add(stack.pop());
}
if(list.size()!=0)
conditionPatternSet.put(list,p.count);
p=p.left;
}
HashMap<String, Integer> itemcount = new HashMap<String, Integer>();
System.out.println("=====================================================");
System.out.print("元素"+form.get(i).name+o+"的条件模式基为:{");
for(Map.Entry<ArrayList<String>,Integer> entry:conditionPatternSet.entrySet()){
ArrayList<String> key = entry.getKey();
System.out.print("(");
for (String s : key) {
if(itemcount.containsKey(s)){
Integer integer = itemcount.get(s);
itemcount.put(s,integer+entry.getValue());
}else {
itemcount.put(s, entry.getValue());
}
System.out.print(s);
}
System.out.print(","+entry.getValue()+")");
}
System.out.println("}");
// 构造条件FPtree
// 删除小于min——support的item
System.out.println("当前最小支持度的阈值为"+MIN_SUPPORT+";现在对小于阈值的item进行处理,结果如下");
Iterator<Map.Entry<String, Integer>> iterator = itemcount.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
if(next.getValue()<MIN_SUPPORT){
iterator.remove();
}
}
for(Map.Entry<String,Integer> entry:itemcount.entrySet()){
System.out.println(entry.getKey()+"===>"+entry.getValue());
}
List<List<String>> orderedRecord= new ArrayList<List<String>>();
Iterator<Map.Entry<ArrayList<String>, Integer>> iterator1 = conditionPatternSet.entrySet().iterator();
while (iterator1.hasNext()){
Map.Entry<ArrayList<String>, Integer> next = iterator1.next();
Iterator<String> iterator2 = next.getKey().iterator();
while (iterator2.hasNext()){
String next1 = iterator2.next();
if(!itemcount.containsKey(next1)){
iterator2.remove();
}
}
}
for(Map.Entry<ArrayList<String>,Integer> entry:conditionPatternSet.entrySet()){
Integer j = entry.getValue();
for(int k=1;k<=j;k++){
orderedRecord.add(entry.getKey());
}
}
TreeNode root1=new TreeNode();
List<TreeNode> formNodes = buildFPtree(root1, orderedRecord, itemcount);
if (formNodes.size()==0){
System.out.println("项目"+form.get(i).name+o+"的条件FPtree为空!!");
// System.out.println("======================================");
}
else {
FPgrowth(root1,form.get(i).name+o,formNodes);
}
}
}
}
// 判断是不是单路经树
private static boolean TreeOnlyOnePath(TreeNode root) {
TreeNode p=root;
while (p!=null){
if(p.childNodes.size()!=1){
return false;
}
p=p.childNodes.get(0);
if(p.childNodes.size()==0)
break;
}
return true;
}
//建FPtree
private static List<TreeNode> buildFPtree(TreeNode root, List<List<String>> record, Map<String, Integer> itemsCount) {
ArrayList<TreeNode> curForm = new ArrayList<>();
for(Map.Entry<String,Integer> entry:itemsCount.entrySet()){
TreeNode treeNode = new TreeNode();
treeNode.name=entry.getKey();
treeNode.count=entry.getValue();
curForm.add(treeNode);
}
for(int i=0;i< curForm.size()-1;i++){
for(int j=i+1;j<curForm.size();j++){
if(curForm.get(j).count>=curForm.get(i).count){
TreeNode t=curForm.get(j);
curForm.set(j,curForm.get(i));
curForm.set(i,t);
}
}
}
List<List<String>> orderedRecord= getOrderedRecord(record,curForm);
myFPtree.orderedRecord=orderedRecord;
for (List<String> strings : orderedRecord) {
TreeNode p=root;
if(root.childNodes.size()==0){
for (String string : strings) {
TreeNode node= new TreeNode(string,1);
TreeNode formNode= query(curForm,node);
formNode.left=node;
node.parentNode=p;
p.childNodes.add(node);
p=node;
}
}
else {
for (String string : strings) {
TreeNode a= childNodesHasString(p,string);
if(a==null){
TreeNode b= new TreeNode(string,1);
TreeNode query = query(curForm, b);
if(query.left!=null){
while (query.left!=null){
query=query.left;
}
}
query.left=b;
b.parentNode=p;
p.childNodes.add(b);
p=b;
}else {
Integer count = a.count;
a.count=count+1;
p=a;
}
}
}
}
return curForm;
}
//判断string是否在结点p中的孩子结点中
private static TreeNode childNodesHasString(TreeNode p, String string) {
ArrayList<TreeNode> childNodes = p.childNodes;
for (TreeNode childNode : childNodes) {
if(childNode.name.equals(string)){
return childNode;
}
}
return null;
}
// 返回的是项头表中与node的name相同的结点
private static TreeNode query(ArrayList<TreeNode> curForm, TreeNode node) {
TreeNode p=node;
for (TreeNode treeNode : curForm) {
if(treeNode.name.equals(node.name)){
p= treeNode;
}
}
return p;
}
//将事务根据item的频繁数进行排序
private static List<List<String>> getOrderedRecord(List<List<String>> record, ArrayList<TreeNode> curForm) {
List<List<String>> orderedRecord= new ArrayList<List<String>>();
for (List<String> strings : record) {
for(int i=0;i<strings.size()-1;i++){
for(int j=0;j<strings.size()-1-i;j++){
if(getFormIndex(curForm,strings.get(j+1))<getFormIndex(curForm,strings.get(j))){
String s= strings.get(j);
strings.set(j, strings.get(j+1));
strings.set(j+1,s);
}
}
}
}
for (List<String> strings : record) {
ArrayList<String> list = new ArrayList<>();
for (String string : strings) {
if(curFormHas(curForm,string)){
list.add(string);
}
}
orderedRecord.add(list);
}
return orderedRecord;
}
private static boolean curFormHas(ArrayList<TreeNode> curForm, String string) {
for (TreeNode treeNode : curForm) {
if(treeNode.name.equals(string)){
return true;
}
}
return false;
}
private static int getFormIndex(ArrayList<TreeNode> curForm, String s) {
for (TreeNode treeNode : curForm) {
if(treeNode.name.equals(s)){
return curForm.indexOf(treeNode);
}
}
return 0;
}
}
// a b e
// b d
// b c
// a b d
// a c
// b c
// a c
// a b c e
// a b c
urForm, String string) {
for (TreeNode treeNode : curForm) {
if(treeNode.name.equals(string)){
return true;
}
}
return false;
}
private static int getFormIndex(ArrayList<TreeNode> curForm, String s) {
for (TreeNode treeNode : curForm) {
if(treeNode.name.equals(s)){
return curForm.indexOf(treeNode);
}
}
return 0;
}
}
// a b e
// b d
// b c
// a b d
// a c
// b c
// a c
// a b c e
// a b c