jieba&hanlp(分词、命名实体识别、词性标注)
jieba
分词:按照字序列的一定顺序重新组合
作用:帮助人更好的理解文字的意思
jieba通常有三种用法:精确模式, 全模式, 搜索引擎模式
import jieba
# jieba.cutl如果不给参数,默认是精确模式
content = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"
# jieba.cut(content, cut_all=False)
# 返回一个生成器对象,cut_all=False是精确模式
print(jieba.lcut(content, cut_all=False))
['工信处', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换机', '等', '技术性', '器件', '的', '安装', '工作']
# cut_all=True 全模式,里面所有能作为词的汉字组合全被提取出来,全模式里面的词有一些并不是必须要的。
print(jieba.lcut(content, cut_all=True))
['工信处', '处女', '女干事', '干事', '每月', '月经', '经过', '下属', '科室', '都', '要', '亲口', '口交', '交代', '24', '口交', '交换', '交换机', '换机', '等', '技术', '技术性', '性器', '器件', '的', '安装', '安装工', '装工', '工作']
# 搜索引擎模式,相对于全模式,只会切分比较长的词
jieba.cut_for_search(content)
print(jieba.lcut_for_search(content))
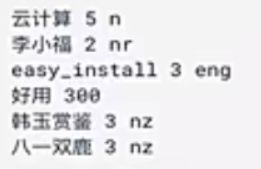
['工信处', '干事', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换', '换机', '交换机', '等', '技术', '技术性', '器件', '的', '安装', '工作']对于一些专用名词,例如默写专业领域的词,jieba通常无法识别分割,我们可以自定义词典,将自定义的词典写进userdict.txt中。
格式:词语 词频(可省略) 词性 (可省略),用空格隔开
顺序不能颠倒

hanlp做分词
tokenizer = hanlp.load('CTB6_CONVSEG')
print(tokenizer("工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"))
tokenizer=hanlp.utils.rules.tokenizer_english
print(tokenizer("Open your books and turn to page 20"))用hanlp做命名实体识别
命名实体:各种名词。人名、地名、机构名等等
例如:周杰伦,朝花夕拾,苹果公司等等。
命名实体识别(NER):就是识别出一段文本中可能存在的命名实体。
实体识别,用hanlp工具输入必须是用列表切分的单个字符
# 命名实体识别
import hanlp
recognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)
# 中文命名实体识别,用hanlp工具输入必须是用列表切分的单个字符
print(recognizer(list("上海华安工业(集团)公司董事长谭旭光和秘书长张晚霞来到美国纽约现代艺术博物馆参观")))
# 英文命名实体识别
recognizer1 = hanlp.load(hanlp.pretrained.ner.CONLL03_NER_BERT_BASE_CASED_EN)
print(recognizer1(["President", "Obama", "is", "speaking", "at", "the", "white", "House"]))
使用jieba做词性标注
常见的词性有14中,如名词,动词,形容词等等。
此行标注以分词为基础,是对文本语言的另一个角度的理解,因此也常常成为AI解决NLP领域高阶任务的重要基础环节。
词性标注:不仅把词分开,还要标注词性。
import jieba.posseg as pseg
print(pseg.lcut('我爱北京天安门'))
# [pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]tagger = hanlp.load(hanlp.pretrained.pos.CTB5_POS_RNN_FASTTEXT_ZH)
print(tagger(["我", "的", "希望", "是", "希望", "和平"]))