PyTorch 11—简单图像定位
常见图像处理的任务
(1)分类
给定一幅图像,我们用计算机模型预测图片中有什么对象 。

(2)分类加定位
不仅需要我们知道图片中的对象是什么,还要在对象的附近画一个边框,确定该对象所处的位置。

(3)语义分割
区分到图中每一个像素点,而不仅仅是矩形框框住。
(4)目标检测
目标检测简单来说就是回答图片里面有什么?分别在哪里?(把它们用矩形框框住)。
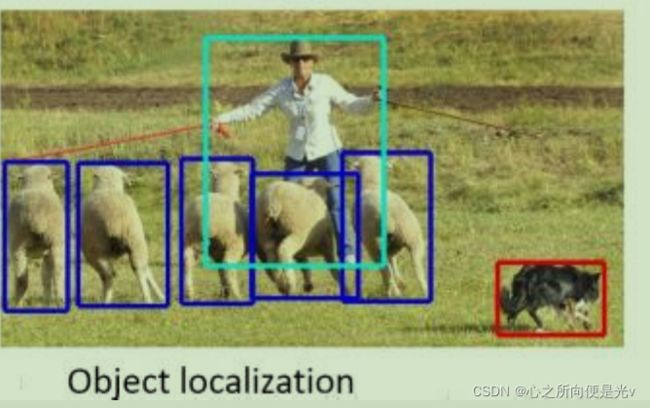
(5)实例分割
实例分割是目标检测和语义分割的结合。相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体。

图像定位
对于单纯的分类问题,比较容易理解,给定一幅图片,我们输出一个标签类别,我们已经跟熟悉。
而定位有点复杂,需要输出四个数字(x,y,w,h),图像中某一个点的坐标(x,y),以及图像的宽度和高度,有了这四个数字,我们可以很容易地找到物体的边框。
简单定位网络架构
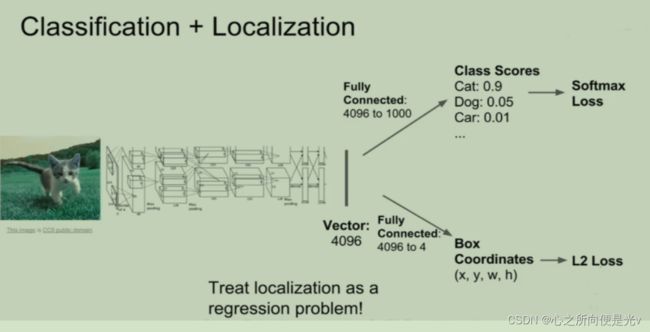
本质是回归问题,使用L2损失进行优化。
Oxford-IIIT数据集
The Oxford-IIIT Pet Dataset是一个宠物图像数据集,包含37种宠物,每种宠物200张左右宠物图片,该数据集同时包含宠物分类、头部轮廓标注和语义分割信息。

代码实战
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import data
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
import os
from lxml import etree # etree网页解析模块
from matplotlib.patches import Rectangle # Rectangle画矩形
import glob # 获取所有路径
from PIL import Image # 读取图像单张图片演示
BATCH_SIZE = 8
print('一、图片解析演示')
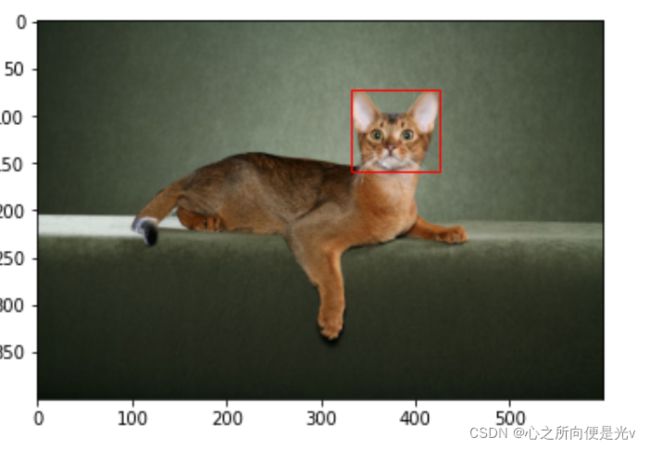
pil_img = Image.open(r'dataset/images/Abyssinian_1.jpg')
np_img = np.array(pil_img) # 转换成ndarray形式
print(np_img.shape)
plt.imshow(np_img)
plt.show()
# 打开对应的xml图像定位信息文件
xml = open(r'dataset/annotations/xmls/Abyssinian_1.xml').read()
# 使用Etree库解析xml文件
sel = etree.HTML(xml) # 首先创建一个解析对象
width = sel.xpath('//size/width/text()')[0] # 使用xpath方法获取它的位置。
# //表示从根目录查找,width/text()表示查找width标签里的文本,返回对象是一个列表,所以要切片处理
height = sel.xpath('//size/height/text()')[0]
print(width,' ',height)
# 查找头部所在的像素位置
xmin = sel.xpath('//bndbox/xmin/text()')[0]
ymin = sel.xpath('//bndbox/ymin/text()')[0]
xmax = sel.xpath('//bndbox/xmax/text()')[0]
ymax = sel.xpath('//bndbox/ymax/text()')[0]
# 将获取到的文本转换成整数。
#转换数据类型,因为matplotlib只能接受整形标注它的位置
width = int(width)
height = int(height)
xmin = int(xmin)
ymin = int(ymin)
xmax = int(xmax)
ymax = int(ymax)
plt.imshow(np_img)
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='blue') # 实例化Rectangle对象,需要标注它的一些位置
# 参数1是xy,即最小值所在的点;第二、三个参数是width、height;fill=False表示不需要填充矩形。
ax = plt.gca() # 获取当前坐标系
ax.axes.add_patch(rect) # 在当前坐标系上添加矩形框。
plt.show()
在原始数据集中,各张图片大小不一,我们在输入模型时,想要把它变成固定的大小。但是,图像改变尺寸后,对应的xmin和ymin就不对了,因为xmin和ymin是相对于原先图片的大小。实际上,我们可以将它转换为一个比值就可以了。
# 例如:
img = pil_img.resize((224,224))
xmin = (xmin/width)*224
ymin = (ymin/height)*224
xmax = (xmax/width)*224
ymax = (ymax/height)*224
plt.imshow(img)
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')
ax = plt.gca() # 获取当前坐标系
ax.axes.add_patch(rect) # 在当前坐标系上添加矩形框。
plt.show()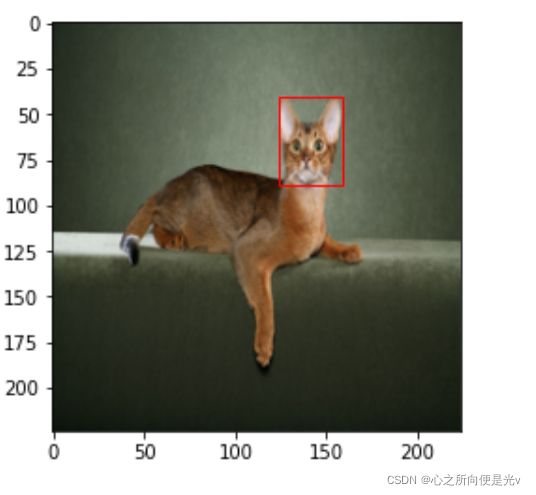
输出是比值,使用比值作为目标值。
创建输入
images = glob.glob('dataset/images/*.jpg') # 返回类型是列表。返回在images目录下所有以 jpg 结尾的文件的路径
xmls = glob.glob('dataset/annotations/xmls/*.xml')
len(images) #7390
len(xmls) # 3686
# 这说明了数据集并没有对全部的图片进行标注
"""
我们不知道对哪些图片做了标注,为了取出标注的图片;
我们要将这些被标注数据的文件名 ;
也即'dataset/annotations/xmls\\Abyssinian_1.xml'中的Abyssinian_1取出来;
然后使用文件名对原有的图片进行一个筛选。
"""
xmls_names = [x.split('\\')[-1].split('.xml')[0] for x in xmls] # 获取到了所有被标注图片的文件名
# xmls_names = [x.split('\\')[-1].replace('.xml','') for x in xmls] 这种办法和上面的效果一样
len(xmls_names) # 3686
# 根据标注图片的文件名对所有图片进行一个筛选
imgs = [img for img in images if
img.split('\\')[-1].split('.jpg')[0] in xmls_names]
len(imgs) #3686
# 在创建输入之前,要保证图片和标注信息是一一对应的
print('len(imgs)==len(xmls_names)?:',len(imgs)==len(xmls_names))
print('imgs[:5]:\n',imgs[:5])
print('xmls[:5]:\n',xmls[:5])将xml文件转换成标签的格式:下面我们需要将xml文件给它转换成标签的形式,在转换之前,我们首先要明确一点,我们的目标值不再是xmin这个实际的值,因为每一张图片的大小都是不一的,这个时候我们只是取出它的一个比例值。我们的预测值是头部宽高度所占的比值。
# 为了将xml列表文件里的数值解析出来,我们专门定义一个toLabel函数
def to_labels(path):
xml = open(r'{}'.format(path)).read() # 用格式化形式,加r,防止转义。
sel = etree.HTML(xml) # 创建选择器
width = int(sel.xpath('//size/width/text()')[0])
height = int(sel.xpath('//size/height/text()')[0])
xmin = int(sel.xpath('//bndbox/xmin/text()')[0])
ymin = int(sel.xpath('//bndbox/ymin/text()')[0])
xmax = int(sel.xpath('//bndbox/xmax/text()')[0])
ymax = int(sel.xpath('//bndbox/ymax/text()')[0])
return [xmin/width, ymin/height, xmax/width, ymax/height]labels = [to_labels(path) for path in xmls]
labels[0],type(labels)
![]()
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
out1_label, out2_label, out3_label, out4_label = list(zip(*labels))
len(out1_label), len(out2_label), len(out3_label), len(out4_label)

划分数据集
index = np.random.permutation(len(imgs))
# img和label都是一一对应的,但是顺序乱序了。
images = np.array(imgs)[index]
labels = np.array(labels)[index]
out1_label = np.array(out1_label).astype(np.float32).reshape(-1, 1)[index]
out2_label = np.array(out2_label).astype(np.float32).reshape(-1, 1)[index]
out3_label = np.array(out3_label).astype(np.float32).reshape(-1, 1)[index]
out4_label = np.array(out4_label).astype(np.float32).reshape(-1, 1)[index]
labels = labels.astype(np.float32) # 由于之前做了除法,最好转换成浮点型数据,这样有利于模型不报错
labels.shape # (3686,4)
"""
out1_label = out1_label.astype(np.float32)
out2_label = out2_label.astype(np.float32)
out3_label = out3_label.astype(np.float32)
out4_label = out4_label.astype(np.float32)
"""
i = int(len(imgs)*0.8) # 训练集比例
train_images = images[:i]
train_labels = labels[:i]
out1_train_label = out1_label[:i]
out2_train_label = out2_label[:i]
out3_train_label = out3_label[:i]
out4_train_label = out4_label[:i]
test_images = images[i:]
test_labels = labels[i:]
out1_test_label = out1_label[i: ]
out2_test_label = out2_label[i: ]
out3_test_label = out3_label[i: ]
out4_test_label = out4_label[i: ]
创建输入模型
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 创建一个DataSet类
class Oxford_dataset(data.Dataset):
def __init__(self, img_paths, out1_label, out2_label,
out3_label, out4_label, transform):
self.imgs = img_paths
self.out1_label = out1_label
self.out2_label = out2_label
self.out3_label = out3_label
self.out4_label = out4_label
self.transforms = transform
def __getitem__(self, index):
img = self.imgs[index] # 切出来是一条路径
out1_label = self.out1_label[index]
out2_label = self.out2_label[index]
out3_label = self.out3_label[index]
out4_label = self.out4_label[index]
pil_img = Image.open(img)
imgs_data = np.asarray(pil_img, dtype=np.uint8)
if len(imgs_data.shape) == 2: # 如果不是rgb图像,就多增加一个维度
imgs_data = np.repeat(imgs_data[:, :, np.newaxis], 3, axis=2)
img_tensor = self.transforms(Image.fromarray(imgs_data))
else:
img_tensor = self.transforms(pil_img)
return (img_tensor,
out1_label,
out2_label,
out3_label,
out4_label)
def __len__(self):
return len(self.imgs)
train_dataset = Oxford_dataset(train_images, out1_train_label,
out2_train_label, out3_train_label,
out4_train_label, transform)
test_dataset = Oxford_dataset(test_images, out1_test_label,
out2_test_label, out3_test_label,
out4_test_label, transform)
train_dl = data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
)
test_dl = data.DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
)
(imgs_batch,
out1_batch,
out2_batch,
out3_batch,
out4_batch) = next(iter(train_dl))
imgs_batch.shape, out1_batch.shape![]()
plt.figure(figsize=(12, 8))
for i,(img, label1, label2,
label3,label4,) in enumerate(zip(imgs_batch[:2],
out1_batch[:2],
out2_batch[:2],
out3_batch[:2],
out4_batch[:2])):
img = (img.permute(1,2,0).numpy() + 1)/2 # permute交换维度。
plt.subplot(2, 3, i+1)
plt.imshow(img)
xmin, ymin, xmax, ymax = label1*224, label2*224, label3*224, label4*224,
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')
ax = plt.gca()
ax.axes.add_patch(rect)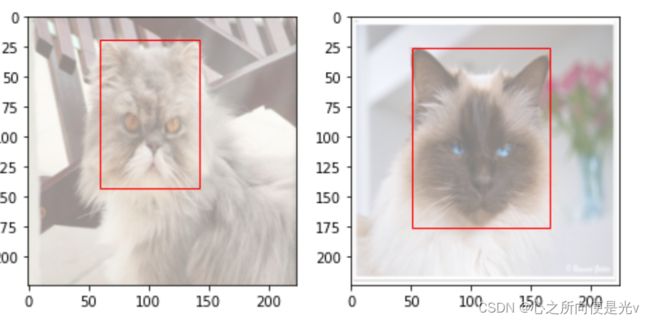
创建定位模型
resnet = torchvision.models.resnet101(pretrained=True) # 使用卷积基提取特征。使用预训练参数作为初始化参数
"""
resnet101里面包含很多层,conv、batch.........
最后是avgpool和fc全连接层。
avgpool之前的层都是我们需要的
"""
in_f = resnet.fc.in_features # 全连接层的输入
print(in_f) #2048
resnet.children() # 会返回所有层的生成器
list(resnet.children()) # 使用list将它返回
print(len(list(resnet.children()))) # 一共包含10个子层
print(list(resnet.children())[-1]) # 看看最后一层
list(resnet.children())[:-1] # 这些层才是我们需要的,帮助我们提取特征。
conv_base = nn.Sequential(*list(resnet.children())) # *代表解包。这样相当于每一层都列在了Sequential里面
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() # 继承父类属性
self.conv_base = nn.Sequential(*list(resnet.children())[:-1])
# 使用全连接模型。分别输出4个坐标值
self.fc1 = nn.Linear(in_f, 1) # 输出是1,因为我们要输出一个标量值。
self.fc2 = nn.Linear(in_f, 1)
self.fc3 = nn.Linear(in_f, 1)
self.fc4 = nn.Linear(in_f, 1)
def forward(self, x):
x = self.conv_base(x) # 提取特征
x = x.view(x.size(0), -1)
x1 = self.fc1(x)
x2 = self.fc2(x)
x3 = self.fc3(x)
x4 = self.fc4(x)
return x1, x2, x3, x4
model = Net()
if torch.cuda.is_available():
model.to('cuda')
loss_fn = nn.MSELoss() # 回归问题,并不是分类问题。误差函数取平均绝对误差,MSE损失函数
from torch.optim import lr_scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) #每次间隔7步,学习速率衰减0.1
def fit(epoch, model, trainloader, testloader):
total = 0
running_loss = 0
model.train()
for x, y1, y2, y3, y4 in trainloader:
if torch.cuda.is_available():
x, y1, y2, y3, y4 = (x.to('cuda'),
y1.to('cuda'), y2.to('cuda'),
y3.to('cuda'), y4.to('cuda'))
y_pred1, y_pred2, y_pred3, y_pred4 = model(x)
loss1 = loss_fn(y_pred1, y1)
loss2 = loss_fn(y_pred2, y2)
loss3 = loss_fn(y_pred3, y3)
loss4 = loss_fn(y_pred4, y4)
loss = loss1 + loss2 + loss3 + loss4
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
running_loss += loss.item()
exp_lr_scheduler.step()
epoch_loss = running_loss / len(trainloader.dataset)
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y1, y2, y3, y4 in testloader:
if torch.cuda.is_available():
x, y1, y2, y3, y4 = (x.to('cuda'),
y1.to('cuda'), y2.to('cuda'),
y3.to('cuda'), y4.to('cuda'))
y_pred1, y_pred2, y_pred3, y_pred4 = model(x)
loss1 = loss_fn(y_pred1, y1)
loss2 = loss_fn(y_pred2, y2)
loss3 = loss_fn(y_pred3, y3)
loss4 = loss_fn(y_pred4, y4)
loss = loss1 + loss2 + loss3 + loss4
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'test_loss: ', round(epoch_test_loss, 3),
)
return epoch_loss, epoch_test_loss开始训练
epochs = 10 # 总共训练十次
train_loss = []
test_loss = []
for epoch in range(epochs):
epoch_loss, epoch_test_loss = fit(epoch, model, train_dl, test_dl)
train_loss.append(epoch_loss)
test_loss.append(epoch_test_loss)
plt.figure()
plt.plot(range(1, len(train_loss)+1), train_loss, 'r', label='Training loss')
plt.plot(range(1, len(train_loss)+1), test_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.legend()
plt.show()
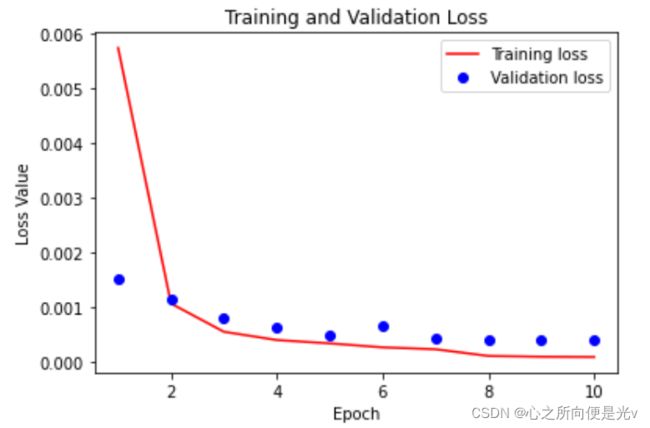
模型保存
PATH = 'location_model.pth'
torch.save(model.state_dict(), PATH) # 保存的是权重,可训练参数。
plt.figure(figsize=(8, 24))
imgs, _, _, _, _ = next(iter(test_dl)) # _占位符。意思是我不需要你实际的位置,我们要自己去预测。
imgs = imgs.to('cuda') # 将图片添加到显卡
out1, out2, out3, out4 = model(imgs) # 进行预测,返回四个坐标值(头部位置)
for i in range(6):
plt.subplot(6, 1, i+1)
plt.imshow(imgs[i].permute(1,2,0).cpu().numpy()) # 放到cpu上
xmin, ymin, xmax, ymax = (out1[i].item()*224, # out[i]代表第i个batch的第一个位置
out2[i].item()*224,
out3[i].item()*224,
out4[i].item()*224)
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')
ax = plt.gca()
ax.axes.add_patch(rect)
plt.show()
