人脸识别模型评价指标:完整梳理
文章目录
- 1. 人脸识别模式
- 2. 二分类常用指标
-
- 2.1 四个基础指标
- 2.2 全项指标
- 2.3 行指标
- 2.4 列指标
- 2.5 综合指标
- 2.6 指标曲线
- 3. 人脸识别指标
-
- 3.1 人脸验证(Verification)
- 3.2 Verification的指标
- 3.3 人脸识别(Identification)
- 3.4 Identification指标
- 4. 后续
-
- 4.1 公式汇总
- 疑问
- 结论(以下适用于1:1Verification)
1. 人脸识别模式
首先,我们得弄清楚人脸识任务的常见两种模式:
-
1:1模式——face verification (人脸验证)
Verification is the process of asking “are you who you say you are?”
face verification (1:1)的意思是,用户声明自己的身份可以被设备或系统识别,设备或系统去验证这个说法是真是假。简单来说,就是比较两张照片(底库数量为1),判断是不是同一个人。
-
1:N模式——face identification (人脸识别)
identification is asking “who are you”
face identification (1:N)的意思是把一个人同数据库里的其他可能的身份进行比对,目的是匹配和发现这个人的身份。实际上,可理解为底库数量为N的1:1,需要回答N次“are you who you say you are?”
具体可以参考:
1、Identification vs Verification: What’s the Difference?
2、人脸识别工作流程
更全面的人脸识别综述可以参考:
人脸识别长篇研究
人脸识别长篇研究2
2. 二分类常用指标
需要注意下图是标准的混淆矩阵,是以样本的正负来划分,
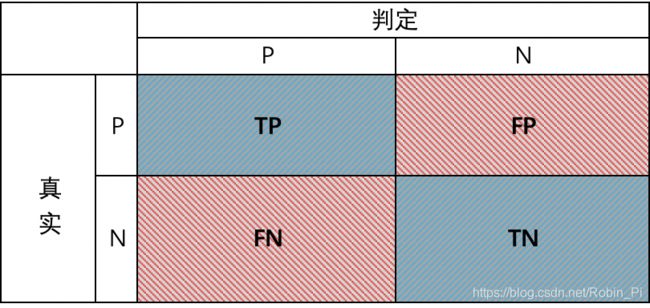

2.1 四个基础指标
- TP
- FP
- FN
- TN
 这四个基础指标的线性组合可以得到其它所有指标。
这四个基础指标的线性组合可以得到其它所有指标。
2.2 全项指标
- 准确率(accuracy) : A c c = T P + T N T P + F N + F P + T N Acc = \frac{TP+TN}{TP+FN+FP+TN} Acc=TP+FN+FP+TNTP+TN
- 错误率(error rate): E r r = F P + F N T P + F N + F P + T N Err = \frac{FP+FN}{TP+FN+FP+TN} Err=TP+FN+FP+TNFP+FN
ACC + ERR = 1
这两项指标很简单,用的也不多。
2.3 行指标
- TP/(TP + FN) = TPR = 召回率(Recall) = 查全率 = TAR
- FP/(FP + TN) = FPR = 误识率 = 误诊率(医学)= FAR
以上两个指标最为常用,除此之外的另外两个行指标:
- FN/(TP+FN) = 1-TPR = 漏检率 = 漏诊率(医学) = FRR,即TPR的互补指标
- TN/(FP+TN ) =1-FPR = TRR,即FPR的互补指标
2.4 列指标
常见的列指标只有一个:
- TP/(TP+FP) = PRE(precision)、查准率
2.5 综合指标
行列综合指标:
-
F1-score
1 F 1 = 1 / 2 ∗ ( 1 P R E + 1 R E C ) \frac{1}{F1}=1/2*(\frac{1}{PRE}+\frac{1}{REC}) F11=1/2∗(PRE1+REC1)
$F1 = 2PREREC/(PRE+REC)
2.6 指标曲线
- PR曲线
- ROC曲线
- DET曲线
- K-S曲线
3. 人脸识别指标
人脸识别的指标离不开标准的二分类指标,但是还是有一些不同,新手很容易掉坑里,理解不清晰。
3.1 人脸验证(Verification)
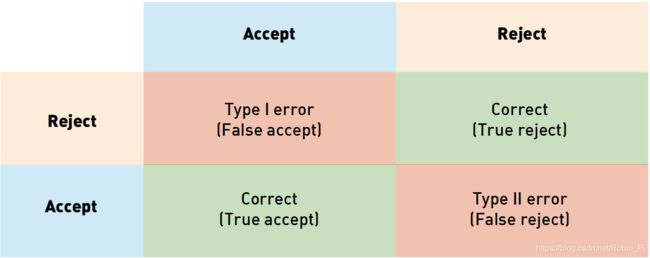
和上面的二分类混淆矩阵一样,列表示算法的判定结果,行表示实际情况。其中,红色部分表示两种出现错误的情况,我们分别用 false accept rate (FAR) 和 false reject rate (FRR) 来表示,计算的方法是:相应错误的数量/数据集大小。而且这两种错误有着很大的不同:
在安防案例中,
- false positive 表示让一个错误的人进入
- false negative 表示拒绝一个已经被授权的人进入
3.2 Verification的指标
总的来说,verification是1:1的比对,比较一对人脸是否属于同一个人。一对人脸,属于同一个人的是P/A,即正样本/接受,属于不同人的是N/R,即负样本/拒绝。在这里用的指标术语是FMR(False Match Rate)和FNMR(False Non-Match Rate)。
3.3 人脸识别(Identification)
根据目标人是否在数据集中,人脸识别可以分为两小类:
- closed-set identification (“闭集”人脸识别):目标人在数据集中
- open-set identification (“开集”人脸识别):目标可能在或者不在数据集中
对于“闭集”人脸识别,一个可靠的、可解释的度量指标就是准确率(Accuracy)。简而言之,准确率测量了目标人在搜寻结果中出现的平均次数。
举例来说,针对一个可以最高展示10个搜索结果的网页,我们应该计算对的人出现在这10个结果中的次数,这被称作 Top-N accuracy,在这里 N=10 。

在上图中的例子中,目标人像出现在第二个位置,所以Top-1准确率是0,而Top-2以及超过Top-2的其它Top准确率则是1。
“开集”人脸识别可以被看作是闭集人脸识别和人脸验证的叠加,并且所有的评估人脸验证任务的讨论在这里也适用。
参考:Notes on Evaluating Face Recognition Software
3.4 Identification指标
真的有很少人讲清楚人脸识别(Identification)的指标,而且很多人都直接用的人脸验证(Verification)的指标!
人脸识别,可以看做是1:N的检索,可以参考:
1、verification(1:1)指标与identification(1:N)指标的关系
2、人脸识别性能指标——很强!
4. 后续
4.1 公式汇总
人脸识别常用的算法评价指标:
- FAR(false acceptance rate)误识率/误检率
- FRR(false rejection rate)拒识率/漏检率
- ROC曲线
- 速度
我们发现:FAR和FRR,它们代表的就是两种错误,也就是混淆矩阵中我标红的部分。
如何理解和区分这两种错误?:
误识率(FAR)= 本 该 匹 配 失 败 却 被 判 为 匹 配 成 功 的 次 数 类 间 总 的 匹 配 失 败 次 数 \frac{本该匹配失败却被判为匹配成功的次数}{类间总的匹配失败次数} 类间总的匹配失败次数本该匹配失败却被判为匹配成功的次数
拒识率(FRR)= 本 该 匹 配 成 功 却 被 判 为 匹 配 失 败 的 次 数 类 内 总 的 匹 配 成 功 次 数 \frac{本该匹配成功却被判为匹配失败的次数}{类内总的匹配成功次数} 类内总的匹配成功次数本该匹配成功却被判为匹配失败的次数
或者更具体的来说:
误识率(FAR) = 非 同 人 比 较 分 数 > 阈 值 T 的 次 数 非 同 人 比 较 的 次 数 \frac{非同人比较分数>阈值T的次数}{非同人比较的次数} 非同人比较的次数非同人比较分数>阈值T的次数
拒识率(FRR)= 同 人 比 较 分 数 < 阈 值 T 的 次 数 同 人 比 较 的 次 数 \frac{同人比较分数<阈值T的次数}{同人比较的次数} 同人比较的次数同人比较分数<阈值T的次数
公式:(参考:错误接受率 (FAR), 错误拒绝率(FRR), 等错误率(EER))
FAR = nontarget_is_target / ( target_is_target + nontarget_is_target )
FRR = target_is_nontarget / ( target_is_nontarget + nontarget_is_nontarget )
更多:EER(等概率错误)
FRR = FP/(TP+FP)
表示 正样本中 被错误识别为负样本的概率
FAR = FN/(TN+FN)
表示 负样本中 被错误识别为正样本的概率
疑问
1、TPR和TAR是一回事么?
2、上面的两种计算公式是一回事么?比如FAR = nontarget_is_target / (target_is_target + nontarget_is_target )= ?=FAR = FN/(TN+FN)
3、所谓”类内“和“类间”具体是怎么计算的?
看了这么多参考的文章,发现很多人把二分类指标FPR和人脸识别指标FAR当做是一样的,也有区别开来的(比如:Face recognition algorithm evaluation --TAR, FAR, FRR, ERR),但是很少能把具体的计算过程讲清楚的。
如何理解误识率(FAR)拒识率(FRR),TPR,FPR以及ROC曲线这一篇中提到了,”类内“和“类间”的具体计算,理解后我做了一个总结(解决了公式中的分母部分):
参数:
- 人数:n
- 类别数:m
计算公式:
- (类内)同类总的比较次数: n ∗ A m 2 n * A^2_m n∗Am2,即每个人下,类别之间的比较(有顺序)
- (类间)非同类总的比较次数: n ∗ m ∗ ( n − 1 ) ∗ m n * m * (n-1) * m n∗m∗(n−1)∗m ,即所有的情况 x 除去自己之外的所有情况
最后,参照一篇比较全的知乎帖子,人脸识别数据集及评估协议(尚未完成),完成下面的总结:
结论(以下适用于1:1Verification)
-
TAR

-
FAR
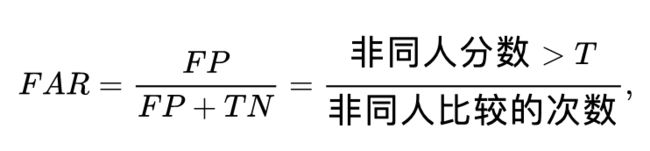
至于这种说法:FAR = nontarget_is_target / ( target_is_target + nontarget_is_target ),我暂时觉得不正确,不应是FAR = nontarget_is_target / ( nontarget_is_target + nontarget_is_nontarget)么? -
FRR
 至于这种说法:FRR = target_is_nontarget / ( target_is_nontarget + nontarget_is_nontarget ),我暂时觉得不正确,不应是FRR = nontarget_is_target / ( nontarget_is_target + target_is_target)么?
至于这种说法:FRR = target_is_nontarget / ( target_is_nontarget + nontarget_is_nontarget ),我暂时觉得不正确,不应是FRR = nontarget_is_target / ( nontarget_is_target + target_is_target)么? -
EER
EER (Equal Error Rate) 表示等误率。EER为取某个T值时,使得FAR=FRR时,FAR或者FRR的值。一般画两条曲线,求交点。
参考:
- Identification vs Verification: What’s the Difference?
- 人脸识别工作流程
- 人脸识别长篇研究
- 人脸识别长篇研究2
- 一文说透机器学习的主流评价指标
- 如何理解误识率(FAR)拒识率(FRR),TPR,FPR以及ROC曲线
- 人脸识别算法评价指标——TAR,FAR,FRR,ERR
- 图像识别中的FAR,FRR,ERR总结
- 如何理解误识率(FAR)拒识率(FRR),TPR,FPR以及ROC曲线
- Notes on Evaluating Face Recognition Software
- 错误接受率 (FAR), 错误拒绝率(FRR), 等错误率(EER)
- Face recognition algorithm evaluation --TAR, FAR, FRR, ERR
- 人脸识别数据集及评估协议(尚未完成)
- verification(1:1)指标与identification(1:N)指标的关系