图像对齐:MeshFlow: Minimum Latency Online Video Stabilization
MeshFlow: Minimum Latency Online Video Stabilization
文章目录
- MeshFlow: Minimum Latency Online Video Stabilization
-
-
- FAST Features
- Track by KLT
-
- 1D Case
- 2D Case
- RANSAC
- MeanFlow
-
- Motion Propagation
- Median Filters
- Vertex Profiles Generation
- Robust Estimation
- Predicted Adaptive Path Smoothing
-
- Offline Adaptive Smoothing
- Predict λ t \lambda_{t} λt
- Online Smoothing
-
FAST Features
作者引用《Fast Corner Detection》中的角点检测算法,分别检测参考帧、畸变帧的特征点。检测方式如下:
1.以像素点 p p p为中心,取半径为3的Bresenham圆上的16个连续的像素点,如果这16个连续的像素点中有 n n n个连续的像素点的像素值都大于 I ( p ) + t I(p)+t I(p)+t,或者都小于 I ( p ) − t I(p)-t I(p)−t,则像素点 p p p为FAST特征点的候选点,一般 n n n取12, t t t为阈值
2.计算得到像素点 p p p与像素点1、5、9、13之间的像素值差异,如果至少有3个像素点与 p p p间的差值绝对值大于阈值 t t t,则像素点 p p p依旧为FAST特征点
3.一般情况下,为了加速计算,可以先计算第二步,满足第二步的情况下,再计算第一步

Track by KLT
作者引用Takeo Kanade 的论文《An Iterative Image Registration Technique with an Application to Stereo Vision》当中对特征点的跟踪算法,但这篇论文本身论证得比较清楚的是一维数据的匹配问题和相邻两帧之间只有平移变换的匹配问题,任意特征点的匹配在作者CMU的课程报告《Detection and Tracking of Point Features》中有更详细的介绍,为了清晰,下面的关于KLT的内容,一维数据的匹配问题采用《An Iterative Image Registration Technique with an Application to Stereo Vision》中的论述,用于描述作者所提供的方法的物理依据,二维图像的匹配问题采用《Detection and Tracking of Point Features》中的论述,方便厘清如何实现二维图像数据的匹配,另外《Detection and Tracking of Point Features》这篇Report写得比较长,如果想要简单了解KLT的导出过程,也可以阅读Stan Birchfield写的《Derivation of Kanade-Lucas-Tomasi Tracking Equation 》一文。
1D Case
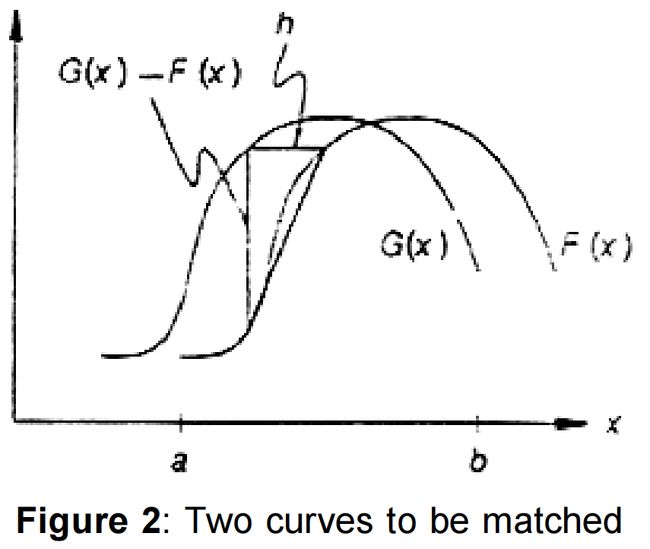
对于一维数据的特征点匹配问题,如下图所示,希望能够找到 G ( x ) 、 F ( x ) G(x)、F(x) G(x)、F(x)间的位移 h h h,如果 h h h足够小,对 F ( x ) F(x) F(x)在点 x x x处做线性近似:
F ′ ≈ F ( x + h ) − F ( x ) h = G ( x ) − F ( x ) h (a.1) F^{'}\approx \frac{F(x+h)-F(x)}{h}=\frac{G(x)-F(x)}{h}\tag{a.1} F′≈hF(x+h)−F(x)=hG(x)−F(x)(a.1)
即:
h ≈ G ( x ) − F ( x ) F ′ ( x ) (a.2) h\approx\frac{G(x)-F(x)}{F^{'}(x)}\tag{a.2} h≈F′(x)G(x)−F(x)(a.2)
通过组合不同的 x x x来达到对 h h h的平滑的目的:
h ≈ ∑ x G ( x ) − F ( x ) F ’ ( x ) ∑ x 1 (a.3) h\approx \frac{ \sum_{x} \frac{G(x)-F(x)}{F^{’}(x)}}{\sum_{x}1}\tag{a.3} h≈∑x1∑xF’(x)G(x)−F(x)(a.3)
在下图中,存在相交的两个点, G ( x ) − F ( x ) = 0 G(x)-F(x)=0 G(x)−F(x)=0,但 G ′ 、 F ′ G^{'}、F^{'} G′、F′间的差异很大,可以用 1 ∣ G ′ − F ′ ∣ \frac{1}{|G^{'}-F^{'}|} ∣G′−F′∣1替换掉上面的权重系数1,即位移 h h h变为:
h ≈ ∑ x w ( x ) G ( x ) − F ( x ) F ’ ( x ) ∑ x w ( x ) ; w ( x ) = 1 ∣ G ′ − F ′ ∣ (a.4) h\approx \frac{ \sum_{x} w(x)\frac{G(x)-F(x)}{F^{’}(x)}}{\sum_{x}w(x)};w(x)=\frac{1}{|G^{'}-F^{'}|}\tag{a.4} h≈∑xw(x)∑xw(x)F’(x)G(x)−F(x);w(x)=∣G′−F′∣1(a.4)
向 h h h所示方向移动 F ( x ) F(x) F(x),并逐步迭代,直至 F ( x ) 、 G ( x ) F(x)、G(x) F(x)、G(x)间的差值小于某阈值 T T T时,认为找到了曲线 F ( x ) F(x) F(x)相对于 G ( x ) G(x) G(x)的位移,即完成了一维数据点 x x x在这两条曲线上的匹配,迭代过程如下:
h 0 = 0 h k + 1 = h k + ∑ x w ( x ) G ( x ) − F ( x ) F ’ ( x ) ∑ x w ( x ) (a.5) h_{0}=0 \\ h_{k+1}=h_{k}+\frac{ \sum_{x} w(x)\frac{G(x)-F(x)}{F^{’}(x)}}{\sum_{x}w(x)}\tag{a.5} h0=0hk+1=hk+∑xw(x)∑xw(x)F’(x)G(x)−F(x)(a.5)
2D Case
针对二维图像的特征点匹配问题,KLT做了一个基本的假设,认为相邻帧当中检测处理的相互匹配的特征点,在以其为中心的某个尺寸的Window当中,Window内的点的像素值相差不大,即是: I ( x , y , t + τ ) = I ( x − ξ , y − η , t ) I(x, y, t+\tau)=I(x-\xi, y-\eta, t) I(x,y,t+τ)=I(x−ξ,y−η,t),其中 t + τ t+\tau t+τ表示下一帧, t t t表示当前帧, d = ( ξ , η ) \mathbf{d}=(\xi,\eta) d=(ξ,η)为对应特征点 x = ( x , y ) \mathbf{x}=(x,y) x=(x,y)在下一帧中的位移。因此,可以同通过最小化特征点在前、后帧中对应Window当中的像素值差值来进行特征点匹配。重新定义 J ( x ) = I ( x , y , t + τ ) J(\mathbf{x})=I(x, y, t+\tau) J(x)=I(x,y,t+τ)为当前帧的特征点, I ( x − d ) = I ( x − ξ , y − η , t ) I(\mathbf{x}-\mathbf{d})=I(x-\xi, y-\eta, t) I(x−d)=I(x−ξ,y−η,t)对应下一帧的特征点,有 J ( x ) = I ( x − d ) + n ( x ) J(\mathbf{x})=I(\mathbf{x-d})+n(\mathbf{x}) J(x)=I(x−d)+n(x),其中 n n n表示噪声,通过最小化特征点在其Window内的残差来求解位移向量 d \mathbf{d} d:
ϵ = ∫ W [ I ( x − d ) − J ( x ) ] 2 w d x (a.6) \epsilon=\int_{\mathcal{W}}[I(\mathbf{x}-\mathbf{d})-J(\mathbf{x})]^{2} w d \mathbf{x}\tag{a.6} ϵ=∫W[I(x−d)−J(x)]2wdx(a.6)
其中 W \mathcal{W} W为Window, w w w为权重函数,常用1或高斯函数。对图像 I I I的亮度信息进行一阶泰勒展开:
I ( x − d ) = I ( x ) − g ⋅ d (a.7) I(\mathbf{x}-\mathbf{d})=I(\mathbf{x})-\mathbf{g} \cdot \mathbf{d}\tag{a.7} I(x−d)=I(x)−g⋅d(a.7)
其中 g \mathbf{g} g为一阶导,重写式(a.6),得:
ϵ = ∫ W [ I ( x ) − g ⋅ d − J ( x ) ] 2 w d x = ∫ W ( h − g ⋅ d ) 2 w d x (a.8) \epsilon=\int_{\mathcal{W}}[I(\mathbf{x})-\mathbf{g} \cdot \mathbf{d}-J(\mathbf{x})]^{2} w d \mathbf{x}=\int_{\mathcal{W}}(h-\mathbf{g} \cdot \mathbf{d})^{2} w d \mathbf{x}\tag{a.8} ϵ=∫W[I(x)−g⋅d−J(x)]2wdx=∫W(h−g⋅d)2wdx(a.8)
其中 h = I ( x ) − J x h=I(\mathbf{x})-J{\mathbf{x}} h=I(x)−Jx。上式是关于 d \mathbf{d} d的二次函数,通过令导数为0进行求解:
∫ W ( h − g ⋅ d ) g w d A = 0 (a.9) \int_{\mathcal{W}}(h-\mathbf{g} \cdot \mathbf{d}) \mathbf{g} w dA=0\tag{a.9} ∫W(h−g⋅d)gwdA=0(a.9)
由于假设Window内的 d \mathbf{d} d是恒定的,且 ( g ⋅ d ) g = ( g g T ) d (\mathbf{g} \cdot \mathbf{d}) \mathbf{g}=\left(\mathbf{g} \mathbf{g}^{T}\right) \mathbf{d} (g⋅d)g=(ggT)d,即是:
( ∫ W g g T w d A ) d = ∫ W h g w d A (a.10) \left(\int_{\mathcal{W}} \mathbf{g g}^{T} w d A\right) \mathbf{d}=\int_{\mathcal{W}} h \mathbf{g} w d A\tag{a.10} (∫WggTwdA)d=∫WhgwdA(a.10)
即是:
G d = e (a.11) G\mathbf{d}=\mathbf{e}\tag{a.11} Gd=e(a.11)
其中系数矩阵 G = ∫ W g g T w d A G=\int_{\mathcal{W}} \mathbf{g g}^{T} w d A G=∫WggTwdA,是一个 2 × 2 2×2 2×2的对称阵; e = ∫ W ( I − J ) g w d A \mathbf{e}=\int_{\mathcal{W}}(I-J) \mathbf{g} w d A e=∫W(I−J)gwdA是一个二维向量。求解方程(a.11)即可解的位移 d \mathbf{d} d,逐步迭代直至帧差 e \mathbf{e} e小于设定阈值 T T T时,认为追踪到角点。
RANSAC
Ransac的原文是《Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography》,下面的内容总结自Milan Sonka的《Image Processing, Analysis, and Machine Vision》一书。
相机位姿变化导致的图像畸变一般的线性的,一般可以通过最小二乘法最小化残差平方和来拟合匹配过后的特征点之间的线性关系。当数据存在某种噪声时,一般性的做法是将数据中相对于拟合模型的残差最大的一些数据点当做异常值,排除这些异常值后重新计算模型,但这种做法做了有关数据本身相关性的假设,这种假设可能并不成立,这是由于误差有典型的两类:
1.测量误差:对应于特征点匹配当中由运动物体带来的特征点本身的移动
2.分类误差:对应于特征点匹配当中的错配
最小二乘建立在使用尽可能多的数据能带来有益的平滑效果的假设基础上的,但这种假设针对特征点匹配的异常点的检出并不是合适的选择,更合适的选择是通过随机抽样一致来拟合。在拟合直线时,两个点就能够定义一条直线,可以在数据集中随机选取两个点并假设连接这两个点的直线就是正确的模型,可以计算在某种程度上接近假设的直线的数据点,称为一致点(Consensus Points)的数目来测试此模型,如果大部分点都是一致点,可以利用一致点集重新拟合得到一个更好的模型,而不是剔除异常值。
1.假设要将 n n n个数据点 X = x 1 . . . . x n X={x_{1}....x_{n}} X=x1....xn拟合为一个由至少 m m m个点决定的模型, m ≤ n m≤n m≤n
2.设迭代次数 k = 1 k=1 k=1,给定偏差 ϵ \epsilon ϵ
3.从 X X X中随机选取 m m m个项并拟合模型
4.计算 X X X中相对于模型的残差在偏差 ϵ \epsilon ϵ内的元素个数,如果元素个数大于阈值 t t t,根据一致点集重新拟合模型,可以利用最小二乘或其变形,终止算法
5. k = k + 1 k=k+1 k=k+1,如果 k k k小于一个事先给定的 K K K,跳至3,否则采用具有最大一致点集的模型,或者算法失败
MeanFlow
Motion Propagation
完成相邻两帧图像间特征点的检测及匹配之后,根据每对特征点 p , p ^ {p,\hat{p}} p,p^的坐标差异,计算运动向量 v p = p − p ^ v_{p}=p-\hat{p} vp=p−p^,将图像划分为 16 × 16 16×16 16×16的均匀网格,每个运动向量传播至以其自身所在网格为中心的 3 × 3 3×3 3×3的网格内
Median Filters
如下图每个网格顶点都将受到其邻域内的多个运动向量的影响,对这些运动向量做一个中值滤波,得到一个更平滑的运动场
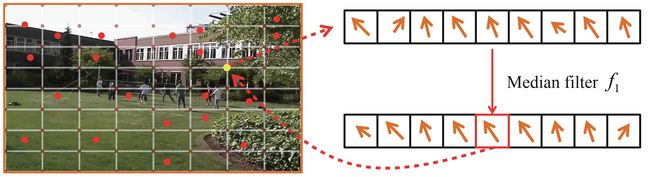
但如下图所示,中值滤波 f 1 f_{1} f1不能滤除网格中比较大的离群点,因此,作者建议再使用一个 3 × 3 3×3 3×3的中值滤波,来去除这些离群点,产生更加平滑的运动场
中值滤波是光流法中的常规操作,但是在本文作者引用的中值滤波的论文《Secrets of Optical Flow Estimation and Their Principles》中有提到两次中值滤波会导致光流法性能的下降。
Vertex Profiles Generation
通过记录每个网格顶点在整个视频图像序列中的运动向量,生成对应顶点的运动轮廓
Robust Estimation
1.Rich Features:在进行特征点检测的时候,一般需要设置一个全局的阈值对特征响应值进行筛选,会造成图像的纹理区域检测到的特征点过少甚至没有,因此在特征点的检测过程中,可以根据网格分块,设置局部阈值,避免部分网格内检测不到合适数量特征点的问题。
2.Outlier Rejection:将图像分成 4 × 4 4×4 4×4的子图,并用RANSAC去除每个子图中因错误匹配、物体运动而造成的离群点
3.Pre-warping:在MehFlow之前,用全部匹配后的特征点计算出一个全局的单应性矩阵 F t F_{t} Ft, F t F_{t} Ft用以表征全图的运动向量 V t V_{t} Vt,并用 F t F_{t} Ft对 p ^ \hat{p} p^的坐标进行预矫正,即该点的局部运动向量为 v ~ p = p − F t p ~ \tilde{v}_{p}=p-F_{t}\tilde{p} v~p=p−Ftp~,该点的全部运动向量为 v p = V t + v ~ p v_{p}=V_{t}+\tilde{v}_{p} vp=Vt+v~p,一些少特征点区域的网格顶点将只受全局运动向量的影响
Predicted Adaptive Path Smoothing
为了在视频后期或者实时处理视频的时候,产生类似于物理防抖(比如陀螺仪)的视频稳定效果,需要在时域上对MeshFlow计算出来的运动向量或者说Warping Map做一个约束,使得展示给视频观看者的视频拥有较好的平滑性。
Offline Adaptive Smoothing
首先,将之前记录下来的每个网格顶点的在整个视频序列中的运动向量看作是一个局部地相机运动路径 C i C_{i} Ci,单帧所用网格顶点的运动向量之和看作时整体的相机运动路径 C C C。期望通过约束相机运动路径的相似性来得到优化后的相机路径 P P P:
O ( P ( t ) ) = ∑ t ( ∥ P ( t ) − C ( t ) ∥ 2 + λ t ∑ r ∈ Ω t w t , r ∥ P ( t ) − P ( r ) ∥ 2 ) (1) \mathcal{O}(\mathbf{P}(t))=\sum_{t}\left(\|\mathbf{P}(t)-\mathbf{C}(t)\|^{2}+\lambda_{t} \sum_{r \in \Omega_{t}} w_{t, r}\|\mathbf{P}(t)-\mathbf{P}(r)\|^{2}\right)\tag{1} O(P(t))=t∑(∥P(t)−C(t)∥2+λtr∈Ωt∑wt,r∥P(t)−P(r)∥2)(1)
其中 C ( t ) = ∑ t v ( t ) C(t)=\sum_{t}\mathbf{v}(t) C(t)=∑tv(t)表示 t t t时刻的相机路径, v ( t ) \mathbf{v}(t) v(t)表示 t t t时刻的MeshFlow, Ω t \Omega_{t} Ωt表示以 t t t时刻在时域上的平滑半径 r r r, w t , r = e − ∣ ∣ r − t ∣ ∣ 2 Ω t 3 w_{t,r}=e^{-\frac{||r-t||^2}{\frac{\Omega_{t}}{3}}} wt,r=e−3Ωt∣∣r−t∣∣2为影响权重, λ t \lambda_{t} λt为两项间的平衡参数,因此,上式的第一项用于约束经平滑后的运动向量 P P P与原运动向量 C C C之间的相似性,上式的第二项是约束当前帧 t t t与其半径为 r r r的时域范围的经优化的运动向量将的相似性,是本方法中的平滑项,上式通过Jacobin迭代求解。
Predict λ t \lambda_{t} λt
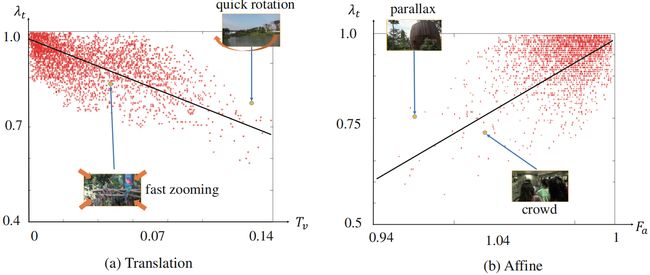
根据当前帧相机的运动来自适应一个合适的参数 λ t \lambda_{t} λt,作者用到了两个经验性的指标:
Translational element T v T_{v} Tv: T v = v x 2 + v y 2 T_{v}=\sqrt{v_{x}^{2}+v_{y}^{2}} Tv=vx2+vy2,其中 v x 、 v y v_{x}、v_{y} vx、vy对应前面计算出来的全局性的单应性矩阵 F F F中的平移分量
Affine component F a F_{a} Fa:单应性矩阵 F F F的仿射变换部分的两个最大特征值的比值
下图为50个快速移动的摄像机拍摄视频计算出来的参数 λ t \lambda_{t} λt和 T v 、 F a T_{v}、F_{a} Tv、Fa之间的关系(没有明白的是这些数据对应的 λ t \lambda_{t} λt是哪里来的),并用这些数据拟合了两个线性模型,如下:
λ t ′ = − 1.93 × T v + 0.95 λ t ′ ′ = 5.83 × F a + 4.88 λ t = m a x ( m i n ( λ t ’ , λ t ′ ′ ) , 0 ) \begin{array}{c} \lambda_{t}^{\prime}=-1.93 \times T_{v}+0.95 \\ \lambda_{t}^{\prime \prime}=5.83 \times F_{a}+4.88\\ \lambda_{t}=max(min(\lambda^{’}_{t},\lambda^{''}_{t}),0) \end{array} λt′=−1.93×Tv+0.95λt′′=5.83×Fa+4.88λt=max(min(λt’,λt′′),0)
Online Smoothing
在线视频稳定相比前面的稳定离线视频的问题的区别主要集中在一下几个方面:①要求速度实时;②只能使用过去帧,不能使用下一帧;③需要在buffer内缓存一定帧数。下图是本文所提在线视频稳定算法的基本框架,当相机开始采集第零帧时,由于没参考帧,第零帧不做稳定处理,且延迟一帧播放,当相机采集第一帧时,用缓存的前一帧数据计算相机运动向量,但此运动向量不作用于图像,直接播放第一帧图像,当相机采集第三帧数据时,计算运动向量,并根据式(1)的约束,计算用于视频稳定的运动向量 P t P_{t} Pt,播放稳定后的第二帧。
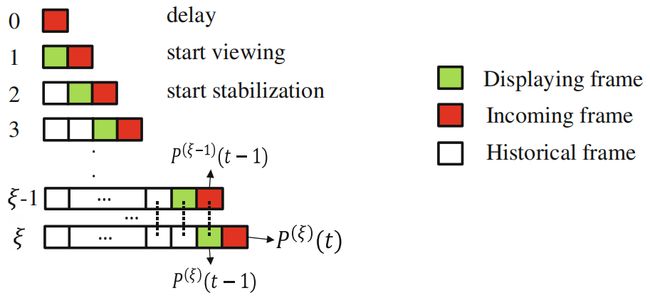
buffer内需要缓存大约1s的历史数据,并且在式(1)中添加历史
O ( P ( ξ ) ( t ) ) = ∑ t ∈ Φ ( ∥ P ( ξ ) ( t ) − C ( t ) ∥ 2 + λ t ∑ t ∈ Φ , r ∈ Ω t w t , r ∥ P ( ξ ) ( t ) − P ( ξ ) ( r ) ∥ 2 ) + β ∑ t ∈ Φ ∥ P ( ξ ) ( t − 1 ) − P ( ξ − 1 ) ( t − 1 ) ∥ 2 (2) \mathcal{O}\left(\mathbf{P}^{(\xi)}(t)\right)=\sum_{t \in \Phi}\left(\left\|\mathbf{P}^{(\xi)}(t)-\mathbf{C}(t)\right\|^{2}+\lambda_{t} \sum_{t \in \Phi, r \in \Omega_{t}} w_{t, r}\left\|\mathbf{P}^{(\xi)}(t)-\mathbf{P}^{(\xi)}(r)\right\|^{2}\right)+\beta \sum_{t \in \Phi}\left\|\mathbf{P}^{(\xi)}(t-1)-\mathbf{P}^{(\xi-1)}(t-1)\right\|^{2}\tag{2} O(P(ξ)(t))=t∈Φ∑⎝⎛∥∥∥P(ξ)(t)−C(t)∥∥∥2+λtt∈Φ,r∈Ωt∑wt,r∥∥∥P(ξ)(t)−P(ξ)(r)∥∥∥2⎠⎞+βt∈Φ∑∥∥∥P(ξ)(t−1)−P(ξ−1)(t−1)∥∥∥2(2)
与(1)不同的是上式的 Φ \Phi Φ表示的式buffer中缓存的数据;其中参数 ξ \xi ξ表示第 ξ \xi ξ次优化。上式第一项用于约束当前帧 P P P经平滑后的运动向量 P P P与原运动向量 C C C之间的相似性;第二项用于约束当前帧 P P P与buffer内缓存的历史帧间的相似性;第三项用于约束当前播放帧在第 ξ \xi ξ次对 P P P的优化过程的结果和第 ξ − 1 \xi -1 ξ−1次对 P P P的优化过程的结果间的相似性。