《《《翻译》》》SUN RGB-D数据集
参考网址:http://rgbd.cs.princeton.edu
http://www0.cs.ucl.ac.uk/staff/M.Firman/RGBDdatasets/
原文名称:SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite
摘要
虽然rgb-d传感器已经为一些视觉任务(如3D重建)带来了重大突破,但我们在高级场景理解方面还没有达到同样的成功水平。其中一个主要原因可能是缺乏一个大型的3D标注基准和3D评估指标。在本文中,我们引入了一个rgb-d基准套件,以提高所有主要场景理解任务的技术水平。我们的数据集由四个不同的传感器捕获,包含10335个rgb-d图像,其规模与pascal voc相似。整个数据集都有密集的注释,包括146617个二维多边形和64595个具有精确对象方向的三维边界框,以及每个图像的三维房间布局和场景类别。这个数据集使我们能够为场景理解任务训练数据密集型算法,使用有意义的3D度量对其进行评估,避免过度适合小的测试集,并研究交叉传感器偏差。
1。介绍
场景理解是计算机视觉中最基本的问题之一。虽然在过去的几十年中取得了显著的进展,但对通用场景的理解仍然被认为是非常具有挑战性的。与此同时,最近在消费市场上出现了价格合理的深度传感器,使我们能够以非常低的成本获得可靠的深度图,从而在身体姿势识别[56,58]、内在图像估计[4]、三维建模[27]和SFM重建[72]等几个视觉任务中取得突破。
此外,RGB-D传感器还使场景理解取得了快速进展(如[20、19、53、38、30、17、32、49])。然而,虽然我们可以轻松地从互联网上抓取彩色图像,但无法在线获取大规模的RGB-D数据。因此,现有的RGB-D识别基准(如NYU Depth V2[49])比彩色图像的现代识别数据集(如Pascal VOC[9])小一个数量级。尽管这些小数据集在过去几年成功地引导了RGB-D场景理解的初步进展,但大小限制现在正成为将研究提升到下一个层次的关键共同瓶颈。除了在评估过程中导致算法的过度拟合外,它们还不能支持当前基于颜色识别技术的训练数据饥饿算法(如[15,36])。如果有一个大规模的rgb-d数据集可用,我们也可以向rgb-d域借用同样的成功。此外,尽管这些数据集中的RGB-D图像包含深度图,但注释和评估指标大多在二维图像领域,而不是直接在三维图像中(图1)。对于大多数应用来说,场景理解在真实的三维空间中更有用。我们希望对场景进行推理,并在3D中评估算法。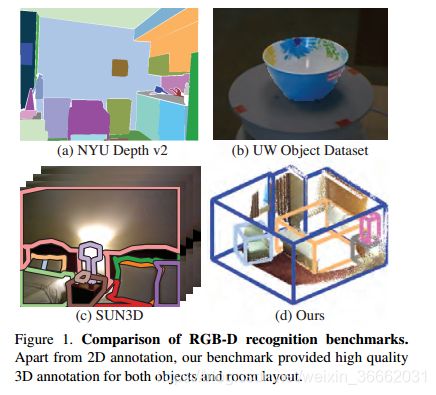
为此,我们介绍了sun rgb-d,它是一个包含10335个rgb-d图像的数据集,在二维和三维中都有密集的注释,用于对象和房间。基于此数据集,我们将重点放在六个重要的识别任务上,以实现对场景的整体理解,这些任务识别对象、房间布局和场景类别。对于每项任务,我们都提出了3D度量标准,并评估了从现有技术中获得的基线算法。由于有几种流行的RGB-D传感器,每种传感器都有不同的尺寸和功耗,因此我们使用四种不同的传感器构建数据集,以研究算法在传感器之间的通用性。通过构造PASCAL尺度数据集,并定义具有3D评价指标的基准,希望为今后几年内推进RGB-D场景理解奠定基础。

1.1。相关工作
关于RGB-D场景理解有很多有趣的工作,包括语义分割[53,49,19]对象分类[69]、对象检测[59,20,62]、上下文推理[38]、中层识别[32,31]以及表面方向和房间布局估计[13,14,74]。
有一个坚实的基准套件来评估这些任务将有助于进一步推进该领域。现有的RGB-D数据集很多[54、47、1、25、44、60、49、45、29、66、57、52、46、16、21、73、35、67、3、41、10、63、42、64、65、48、12、33、8、50、26、6]。图1显示了其中一些。在这里,我们将简要介绍几个最相关的1。有一些数据集[61,37]捕捉转盘上的对象,而不是真实场景。
对于自然室内场景数据集,纽约大学深度2[49]可能是最流行的。他们使用图像域上的二维语义分割,对1449个短RGB-D视频中选定的帧进行了标记。[18]通过将CAD模型与三维点云对齐来注释每个对象。但是,3D注释非常嘈杂,在我们的基准测试中,我们重用了二维分割,但自己重新创建了3D注释。尽管这个数据集非常好,但与其他现代识别数据集(如PascalVOC[9]或ImageNet[7])相比,它的大小仍然很小。b3do[28]是另一个在rgb-d图像上具有二维边界框注释的数据集。但是它的尺寸比纽约大学要小,而且它有许多带有不现实场景布局的图像(例如地板上的电脑鼠标快照)。康奈尔rgbd数据集[2,34]包含52个室内场景,在缝合的点云上每个点都有注释。sun3d[72]包含415个rgb-d视频序列,在某些关键帧上具有二维多边形注释。虽然它们在三维中缝合了点云,但是注释仍然纯粹在二维图像域中,并且只有8个注释序列。

2。数据集构造
我们的数据集构建的目标是以与PascalVOC目标检测基准相似的比例获取各种RGB-D传感器捕获的图像数据集。为了提高深度图的质量,我们拍摄了短视频,并使用多帧来获得一个精细的深度图。对于每个图像,我们都用二维多边形和三维边界框来注释对象,用三维多边形来注释房间布局。
2.1。传感器
由于有几种流行的传感器,具有不同的尺寸和功耗,因此我们使用四种类型构建数据集:用于平板电脑的Intel Realsense 3D相机、用于笔记本电脑的Asus Xtion Live Pro和用于台式机的Microsoft Kinect 1和2版。表1显示了每个传感器的规格。图2显示了捕获的示例颜色和深度图像。
Intel Realsense是一款专为平板电脑设计的轻量、低功耗深度传感器。它将很快到达消费者;我们从Intel获得了两个预发布样本。它将红外图像投影到环境中,利用立体匹配获得深度图。对于室外环境,它可以自动切换到立体匹配和-out红外模式;但是,我们目视检查了三维点云,认为深度图质量太低,无法用于室外精确的物体识别。因此,我们只使用这个传感器捕捉室内场景。图2显示,它的原始深度比其他的RGB-D传感器要差,并且可靠深度的有效范围较短(深度在3.5米左右变得非常嘈杂)。但是,这种类型的轻量化传感器可以嵌入到便携式设备中,并在消费市场大规模部署,因此研究其算法性能具有重要意义。

华硕Xtion和Kinect v1采用近红外模式。华硕Xtion更轻,仅由USB供电,比Kinect v1的彩色图像质量差。但是,Kinect v1需要额外的电源。两个传感器的原始深度图具有可观测的量化效果。Kinect V2基于飞行时间,同时也消耗大量能量。捕获的原始深度图更准确,具有高保真度,可测量详细的深度差,但对于黑色物体和轻微反射的表面,失败的频率更高。硬件支持长距离深度范围,但官方的Kinect for Windows SDK将深度限制在4.5米,并应用一些容易丢失对象细节的过滤。因此,我们编写了自己的驱动程序,并在GPU中对原始深度进行解码(Kinect V2需要软件深度解码),以便在没有深度截止或附加过滤的情况下捕获实时视频。
2.2.传感器校准
对于RGB-D传感器,我们必须校准相机的内部参数以及深度和颜色相机之间的转换。对于Intel Realsense,我们使用默认的工厂参数。对于asus xtion,我们依赖openni库返回的默认参数,而不建模径向变形。对于Kinect V2,径向畸变非常强烈。因此,我们使用标准校准工具箱[5]校准所有摄像头。我们通过计算与深度相机相同的红外图像参数来校准深度相机。为了在红外上看不到过度曝光的棋盘,我们用一张纸覆盖发射器。我们使用立体校准功能来校准深度(IR)和彩色相机之间的转换。
2.3.深度图改进
由于测量噪声、到规则反射表面的视角以及遮挡边界,这些相机的深度贴图并不完美。因为所有的rgbd传感器都像摄像机一样工作,所以我们可以使用附近的帧来改进深度图,提供冗余数据来消除和填充丢失的深度。
提出了一种基于多个RGB-D帧的深度图融合的鲁棒算法。对于时间窗口中的每一个相邻帧,我们将点投影到三维,从相邻点获取三角网格,并估计该帧与目标帧之间的三维旋转和平移,以提高深度。使用这种估计变换,我们从目标帧相机渲染网格的深度图。当我们得到对齐和扭曲的深度图后,我们将它们进行整合,得到一个稳健的估计。对于每个像素位置,我们计算中值深度和25%和75%的百分位数。如果原始目标深度缺失或超出25%—75%的范围,并且根据至少10张弯曲深度图计算中间值,则使用中间值深度值。否则,我们保留原始值以避免过度协商。示例如图2所示。与使用基于三维体素的TSDF表示的[72]相比,我们的深度图改进算法需要更少的内存,以相同的分辨率运行更快,从而实现高分辨率集成。
该算法的关键是对邻近帧和目标帧之间的精确三维变换进行鲁棒估计。为此,我们首先利用SIFT获取两幅彩色图像之间的点地形对应关系,从原始深度图中获取SIFT关键点的三维坐标,然后利用三点RANSAC估计这两个稀疏的三维SIFT云之间的刚性三维旋转和平移。为了获得更准确的估计,我们希望使用全深度地图与ICP进行密集对齐,但根据3D结构,ICP可能会有严重的漂移。因此,我们首先使用sift+ransac的估计值来初始化ICP的转换,并计算出ICP匹配的点数百分比。使用初始化和百分比阈值,我们运行点平面ICP直到收敛,然后用RANSAC的原始SIFT关键点输入检查3D距离。如果距离显著增加,则意味着ICP会使结果偏离事实;我们将使用原始的RANSAC估计,而不使用ICP。否则,我们使用ICP结果。
2.4。数据采集
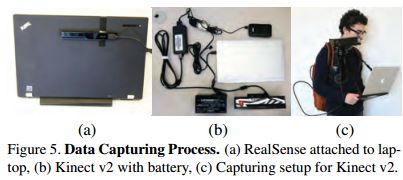
为了在PascalVOC尺度上构建一个数据集,我们自己捕获了大量的新数据,并结合了一些现有的RGB-D数据集。我们使用Kinect v2捕获3784个图像,使用Intel Realsense捕获1159个图像。我们包括了纽约大学深度2版的1449张图片[49],还手动选择了伯克利B3DO数据集的554张真实场景图片[28],这两张图片都是由Kinect 1版拍摄的。我们从华硕Xtion拍摄的Sun3d视频[72]中手动选择了3389个没有明显运动模糊的不同帧。共获得10335幅RGB-D图像。
如图5所示,我们将IntelRealsense连接到笔记本电脑上,然后随身携带它来捕获数据。对于Kinect V2,我们使用移动笔记本电脑线束和相机稳定器。因为Kinect V2消耗大量的电能,我们使用12伏汽车电池和5伏智能手机电池为传感器和适配器电路供电。RGB-D传感器只能在室内工作。我们专注于北美和亚洲的大学、房屋和家具店。一些示例图像如图3所示。
2.5。地面真值注释
对于每个RGB-D图像,我们获得labelme样式的二维多边形注释、对象的三维边界框注释和房间布局的三维多边形注释。为了确保注释质量和一致性,我们从其他数据集中获得了自己的图像地面真值标签;唯一的例外是纽约大学,我们使用它的二维分割。
对于二维多边形注释,我们为AmazonMechanical Turk开发了一个labelmestyle[55]工具。为了保证高的标签质量,我们在工具中添加了自动评估。要完成点击,每个图像必须至少有6个标记的对象;所有对象多边形的联合必须至少覆盖总图像的80%。为了防止工人用大多边形覆盖所有东西而作弊,小多边形的联合(面积小于图像的30%)必须至少覆盖总图像面积的30%。最后,作者对标签结果进行了外观检查,并在必要时手动更正图层顺序。低质量的标签被送回重新贴标签。我们为每张图片支付了0:10美元;有些图片需要多次标记以满足我们的质量标准。
对于三维注释,首先使用自动算法旋转点云以与重力方向对齐。我们用25个最近的三维点估计每个三维点的法向。然后在一个三维半球面上累积一个柱状图,从中选取最大计数,得到第一个轴。对于第二个轴,我们从与第一个轴正交的方向选取最大计数。这样,我们就得到了旋转矩阵来旋转点云,使其与重力方向对齐。当算法失败时,我们手动调整旋转。
我们设计了一个基于网络的注释工具,并雇用了Odesk的工作人员在3D中注释对象和房间布局。对于对象,该工具需要在顶视图上绘制一个带有方向箭头的矩形,并调整顶部和底部使其膨胀为3D。对于房间布局,该工具允许顶视图上的任意多边形描述复杂的结构。房间的构造(图3)。我们的工具还可以实时显示三维框到图像的投影,以便在注释期间提供直观的反馈。我们雇佣了18名Odesk员工,并在Skype上对他们进行培训。平均小时工资是3.90美元,他们总共花了2051小时。最后,作者对所有标记结果进行了彻底的检查和纠正。对于场景类别,我们手动将图像分类为基本级别的场景类别。

2.6。标签统计信息
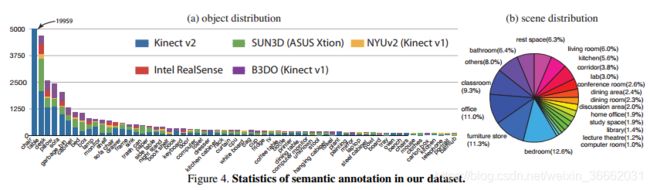
对于10335个RGB-D图像,我们有146617个二维多边形和64595个三维边界框(对象的精确方向)注释。因此,每个图像中平均有14.2个对象。总共有47个场景类别和800个对象类别。图4显示了主要对象和场景类别的语义注释的统计信息。
3。基准设计
为了评估整个场景理解管道,我们选择了六个任务,既包括流行的现有任务,也包括新的但重要的任务,包括基于单个对象的任务和场景任务,以及集成所有内容的最终总体场景理解任务。
场景分类 场景分类是理解场景的一项非常流行的任务[70]。在这个任务中,我们得到一个RGB-D图像,将图像分类为一个预先定义的场景类别,并使用标准的平均分类精度进行评估。
语义分割 二维图像领域中的语义分割是目前最常用的RGB-D场景理解任务。在这个任务中,算法为RGB-D图像中的每个像素输出一个语义标签。我们使用跨对象类别的标准平均精度进行评估。
目标检测 目标检测是场景理解的另一个重要步骤。我们通过将二维目标检测的标准评估标准扩展到三维来评估二维和三维方法。假设方框与重力方向对齐,我们使用预测和地面真值框联合的三维交叉点进行三维评估。
对象方向 除了预测目标的位置和类别外,另一个重要的视觉任务是估计目标的姿态。例如,知道椅子的方向对于正确坐在椅子上至关重要。因为我们假设一个对象边界框与重力对齐,所以估计方向的偏航角只有一个自由度。我们通过预测与地面真实度的角度差来评价预测。
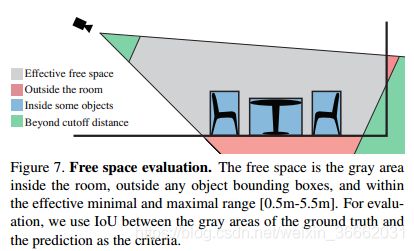
房间布局估算 整个场景空间的空间布局允许对自由空间进行更精确的推理(例如,我可以在哪里行走?)改进了对象推理。对于基于颜色的场景理解来说,这是一项受欢迎但具有挑战性的任务(例如[22、23、24])。有了RGB-D图像中的额外深度信息,这项任务被认为是更可行的[74]。通过计算地面真值自由空间与算法输出预测的自由空间的交集(IOU),对三维空间中的房间布局估计进行了评估。
如图7所示,自由空间定义为满足以下四个条件的空间:1)在摄像机视场内,2)在有效范围内,3)在房间内,4)在任何对象边界框外(对于房间布局估计,我们假设没有对象的空房间)。在实现上,我们在空间上定义了一个0:1×0:1×0:1米3的体素网格,并选择了摄像机视场内距离摄像机0.5到5.5米的体素,这是大多数RGB-D传感器的有效范围。对于每一个有效的体素,给定一个房间布局的三维多边形,我们检查体素是否在里面。这样,我们就可以通过计算三维体素来计算交点和并集。
该评价指标直接衡量自由空间预测精度。然而,我们只关心5.5米范围内的空间;如果一个房间太大,所有有效的体素都将在地面实况室中。如果一个算法预测一个超过5.5米的大房间,那么IOU将等于1,这就引入了偏差:算法将倾向于一个大房间。为了解决这个问题,我们只评估具有合理尺寸(不太大)的房间的算法,因为没有一个RGB-D传感器可以看到非常远的距离。如果地面实况室中有效三维体素的百分比大于95%,我们将在评估中丢弃该空间。
总场景理解 我们的场景理解基准的最终任务是估计整个场景,包括3D中的对象和房间布局[38]。这项任务在[71]中也被称为“基本级场景理解”。我们建议将此基准任务作为最终目标,将目标检测和房间布局估计结合起来,以获得全面的场景理解、识别和定位所有对象和房间结构。
我们通过比较地面真值对象和预测对象来评估结果。为了将预测结果与地面实况相匹配,我们计算了所有对预测框和地面实况框之间的IOU,并按降序对IOU得分进行排序。我们用最大的借据选择每个可用的对,并将这两个框标记为不可用。我们重复这个过程,直到IOU低于阈值τ(在这种情况下,τ=0:25)。对于地面真值和预测值之间的每一对匹配,我们比较它们的目标标签,以了解它是否是正确的预测。jjj为地面真值箱数,jjj为预测箱数,jmj为IOU>τ的匹配对数,jjj为标签正确的匹配对数。我们通过计算三个数字来评估算法:rr=jcj=jgj来测量语义和几何的识别召回,rg=jmj=jgj来测量几何预测召回,pg=jmj=jpj来测量几何预测精度。我们还通过使用与房间布局类似的方案来评估自由空间:计算自由空间的可见三维体素,即房间多边形内部但任何对象边界框外部。再次,我们计算了地面真理的自由空间和预测之间的IOU。
4。实验评价
我们选择一些最先进的算法来评估每个任务。对于没有现有算法或实现的任务,我们采用其他任务的流行算法。对于每一项任务,只要有可能,我们都会尝试使用颜色、深度以及RGB-D图像来评估算法,以研究颜色和深度的相对重要性,并在多大程度上衡量这两种信息的互补性。各种评估结果表明,我们可以将针对颜色设计的标准技术(如手工艺特征、深度学习特征、检测器、筛选流标签传输)应用到深度域中,并且可以在各种任务中达到可比的性能。在大多数情况下,当我们结合这两个信息源时,性能会得到提高。
为了进行评估,我们仔细地将数据分为训练和测试集,确保每个传感器有大约一半用于训练,一半用于测试,因为有些图像是从相同的建筑物或具有相似家具风格的房子中捕获的,为了确保公平性,我们仔细地将训练和测试集分割,确保这些图像来自同一栋建筑要么都进入了训练场,要么进入了测试场,而不是分散在两个测试场。对于来自纽约大学深度V2[49]的数据,我们使用原始分割。
场景分类 对于这个任务,我们使用19个场景类别,其中有80多个图像。我们选择了以RBF内核1和所有SVM为基线的GIST[51]。我们还选择了最先进的Places CNN[75]场景功能,在Sun数据库[70]上实现了基于颜色的场景分类的最佳性能。这项功能是使用深度卷积神经网络(Alexnet[36])和250万幅场景图像学习的[75]。我们将线性支持向量机和RBF内核支持向量机与CNN功能结合使用。此外,经验实验[20]表明,传统的图像特征和彩色图像的深度学习特征都可以用来提取深度图的强大特征,因此,我们还计算了要点,并将CNN放在深度图上。我们还评估了深度和颜色特征的串联。在提取特征之前,深度图像编码为hha图像,如[20]所示。图6报告了这些实验的准确性。我们可以看到,深度学习功能确实表现得更好,颜色和深度功能的组合也有帮助。
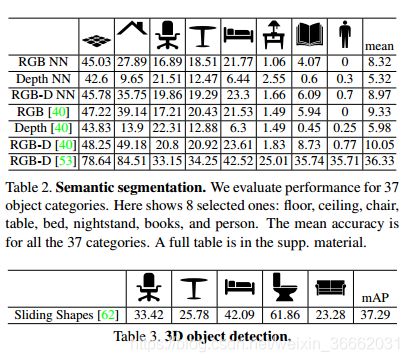
语义分割 我们在基准上运行了最先进的语义分割算法[53],并将结果报告在表2中。由于我们的数据集非常大,我们希望非参数标签传输能够很好地工作。我们首先使用places cnn功能[75]找到最近的邻居,并直接复制其分割结果。我们惊奇地发现,这种简单的方法非常有效,尤其是对于大的物体(如地板、床)。然后,我们在颜色和深度上调整了筛选流算法[40,39],以估计流。但它只是稍微提高了性能。
目标检测 我们评估了四种最先进的目标检测算法:dpm[11]、exampar svm[43]、rgb-d rcnn[20]和滑动形状[62]。对于DPM和示例SVM,我们使用深度作为另一个图像通道和连接从该图像和彩色图像计算出的HOG。为了评估前三种二维算法,我们使用阈值为0.5的二维IOU,结果如表4所示。二维地面真值框是通过将三维地面真值框内的点投影回二维并找到包含这些二维点的紧框来获得的。对于三维检测,我们使用[62]中最初使用的CAD模型评估最新的滑动形状算法的状态,并评估其算法
五大类。我们使用3D框进行评估,IOU为0.25,如[62]所示,结果报告于表3。
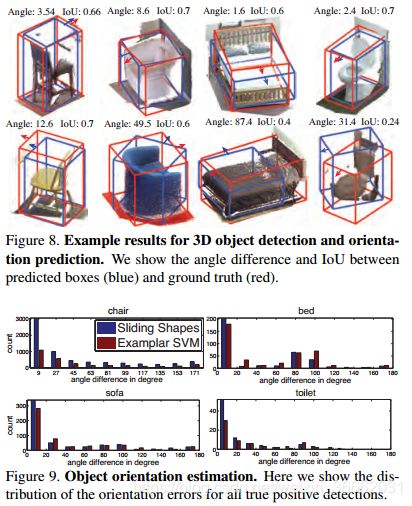
对象方向 我们评估了两种基于范例的方法:范例SVM[43]和滑动形状[62]。我们将训练样本的方向转移到预测的边界框中。有些类别(例如圆桌)没有明确的方向,不包括在评估中。图8显示了示例结果,图9显示了预测误差的分布。

房间布局估算
尽管存在此任务的算法[74],但我们找不到开源实现。因此,我们设计了三个基线:最简单的基线(称为凸壳)通过沿重力方向取三维点的0.1和99.9%来计算地板和天花板高度,并计算点投影到地板平面上的凸壳来估计墙壁。我们更强的基线(称为曼哈顿盒)使用平面拟合来估计一个三维矩形房间盒。我们首先根据法向直方图估计点云的三个主要方向(见第2.5节)。然后根据法向对点云进行分割,寻找距离中心最远的平面,形成一个房间布局框。为了与基于颜色的方法进行比较,我们在彩色图像上运行几何上下文[22]来估计二维的房间布局,然后使用重力方向估计的相机倾斜角度和传感器的焦距来重建三维的单视图几何布局,使用估计的楼层高度来缩放三维布局Pro。乖乖。
图10显示了这些算法的结果示例。几何上下文的平均IOU为0.442,凸面外壳为0.713,曼哈顿盒子为0.734表现最佳。
全面了解现场
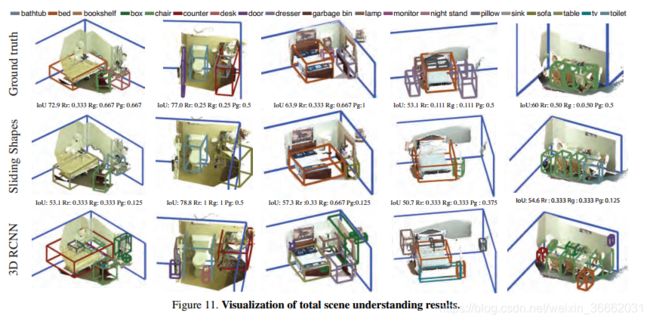
我们使用RGB-D RCNN和滑动形状进行物体检测,并将它们与曼哈顿盒子结合起来进行房间布局估计。我们对对象类别进行非最大值抑制。对于rgbd rcnn,我们从二维检测结果估计对象的三维边界框。为了得到3D框,我们首先将2D窗口中的点投影到3D。沿着房间的每个主要方向,我们建立一个点计数的柱状图。从柱状图的中值开始,我们将框边界设置在第一个不连续的位置。我们还设置了一个检测置信度阈值和一个房间内的最大对象数,以进一步减少检测次数。结合现有的物品和房间布局,我们提出了四种简单的整合方法:(1)直接合并;(2)去除估计房间布局之外的物品检测;(3)调整房间,使其符合90%的物品要求;(4)根据大多数物品调整房间,并去除房间外的物品。图11和表5显示了结果。
交叉传感器
因为真实数据可能来自不同的传感器,所以一个算法可以在它们之间推广是很重要的。与数据集偏差[68]相似,我们研究了不同RGB-D传感器的传感器偏差。我们利用一个传感器捕捉到的数据对一个DPM目标探测器进行了训练,并对另一个传感器捕捉到的数据进行了测试,以评估交叉传感器的通用性。为了分离数据集偏差,我们对数据的一个子集进行了这个实验,其中Xtion和Kinect v2安装在具有相同位置的大重叠视图的装备上。从表6的结果中,我们可以看到传感器偏差确实存在。基于颜色和深度的算法都显示出一些性能下降。我们希望这一基准能够刺激具有更好传感器泛化能力的RGB-D算法的发展。

5.结论
我们在PascalVOC尺度上引入了一个RGB-D基准套件,在二维和三维标注中都有注释。我们提出了三维度量,并对所有主要任务的算法进行了评估,以实现对场景的全面理解。我们希望,我们的基准将在未来几年为了解RGB-D场景取得重大进展。
Acknowledgement。
这项工作由英特尔公司的赠款支持。感谢Thomas Funkhouser、Jitendra Malik、Alexi A.Efros和Szymon Rusinkiewicz的宝贵讨论。我们还感谢Linguang Zhang、Fisher Yu、Yinda Zhang、Luna Song、Zhirong Wu、Pingmei Xu、Guoxuan Zhang和其他人收集和标记数据。
References
[1] A. Aldoma, F. Tombari, L. Di Stefano, and M. Vincze. A global hypotheses verification method for 3d object recognition. In ECCV. 2012. 2
[2] A. Anand, H. S. Koppula, T. Joachims, and A. Saxena.Contextually guided semantic labeling and search for threedimensional point clouds. IJRR, 2012. 2
[3] B. I. Barbosa, M. Cristani, A. Del Bue, L. Bazzani, and V. Murino. Re-identification with rgb-d sensors. In First International Workshop on Re-Identification, 2012. 2
[4] J. T. Barron and J. Malik. Intrinsic scene properties from a single rgb-d image. CVPR, 2013. 1
[5] J.-Y. Bouguet. Camera calibration toolbox for matlab. 2004. 3
[6] C. S. Catalin Ionescu, Fuxin Li. Latent structured models for human pose estimation. In ICCV, 2011. 2
[7] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 2
[8] N. Erdogmus and S. Marcel. Spoofing in 2d face recognition with 3d masks and anti-spoofing with kinect. In BTAS, 2013.2
[9] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. IJCV, 2010. 1, 2
[10] G. Fanelli, M. Dantone, J. Gall, A. Fossati, and L. Van Gool. Random forests for real time 3d face analysis. IJCV, 2013. 2
[11] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. PAMI, 2010. 7
[12] S. Fothergill, H. M. Mentis, P. Kohli, and S. Nowozin. Instructing people for training gestural interactive systems. In CHI, 2012. 2
[13] D. F. Fouhey, A. Gupta, and M. Hebert. Data-driven 3d primitives for single image understanding. In ICCV, 2013. 2
[14] D. F. Fouhey, A. Gupta, and M. Hebert. Unfolding an indoor origami world. In ECCV. 2014. 2
[15] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1
[16] D. Gossow, D. Weikersdorfer, and M. Beetz. Distinctive texture features from perspective-invariant keypoints. In ICPR, 2012. 2
[17] R. Guo and D. Hoiem. Support surface prediction in indoor scenes. In ICCV, 2013. 1
[18] R. Guo and D. Hoiem. Support surface prediction in indoor scenes. In ICCV, 2013. 2
[19] S. Gupta, P. Arbelaez, and J. Malik. Perceptual organization and recognition of indoor scenes from RGB-D images. In
CVPR, 2013. 1, 2
[20] S. Gupta, R. Girshick, P. Arbelaez, and J. Malik. Learning rich features from RGB-D images for object detection and segmentation. In ECCV, 2014. 1, 2, 7
[21] A. Handa, T. Whelan, J. McDonald, and A. Davison. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In ICRA, 2014. 2
[22] V. Hedau, D. Hoiem, and D. Forsyth. Recovering the spatial layout of cluttered rooms. In ICCV, 2009. 5, 8
[23] V. Hedau, D. Hoiem, and D. Forsyth. Thinking inside the box: Using appearance models and context based on room geometry. In ECCV. 2010. 5
[24] V. Hedau, D. Hoiem, and D. Forsyth. Recovering free space of indoor scenes from a single image. In CVPR, 2012. 5
[25] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, and N. Navab. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. In ACCV. 2013. 2
[26] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. PAMI, 2014. 2
[27] S. Izadi, D. Kim, O. Hilliges, D. Molyneaux, R. Newcombe, P. Kohli, J. Shotton, S. Hodges, D. Freeman, A. Davison, and
A. Fitzgibbon. Kinectfusion: Real-time 3d reconstruction and interaction using a moving depth camera. In UIST, 2011. 1
[28] A. Janoch, S. Karayev, Y. Jia, J. T. Barron, M. Fritz, K. Saenko, and T. Darrell. A category-level 3-d object dataset: Putting the kinect to work. In ICCV Workshop on Consumer Depth Cameras for Computer Vision, 2011. 2, 4
[29] A. Janoch, S. Karayev, Y. Jia, J. T. Barron, M. Fritz, K. Saenko, and T. Darrell. A category-level 3d object dataset: Putting the kinect to work. 2013. 2
[30] Z. Jia, A. Gallagher, A. Saxena, and T. Chen. 3d-based reasoning with blocks, support, and stability. In CVPR, 2013. 1
[31] H. Jiang. Finding approximate convex shapes in rgbd images. In ECCV. 2014. 2
[32] H. Jiang and J. Xiao. A linear approach to matching cuboids in RGBD images. In CVPR, 2013. 1, 2
[33] M. Kepski and B. Kwolek. Fall detection using ceilingmounted 3d depth camera. 2
[34] H. S. Koppula, A. Anand, T. Joachims, and A. Saxena. Semantic labeling of 3d point clouds for indoor scenes. In NIPS, 2011. 2
[35] H. S. Koppula, R. Gupta, and A. Saxena. Learning human activities and object affordances from rgb-d videos. IJRR,2013. 2
[36] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1, 7
[37] K. Lai, L. Bo, X. Ren, and D. Fox. A large-scale hierarchical multi-view rgb-d object dataset. In ICRA, 2011. 2
[38] D. Lin, S. Fidler, and R. Urtasun. Holistic scene understanding for 3d object detection with RGBD cameras. In ICCV 2013. 1, 2, 6
[39] C. Liu, J. Yuen, and A. Torralba. Nonparametric scene parsing: Label transfer via dense scene alignment. In CVPR 2009. 7
[40] C. Liu, J. Yuen, and A. Torralba. Sift flow: Dense correspondence across scenes and its applications. PAMI, 2011. 6, 7
[41] L. Liu and L. Shao. Learning discriminative representations from rgb-d video data. In IJCAI, 2013. 2
[42] M. Luber, L. Spinello, and K. O. Arras. People tracking in rgb-d data with on-line boosted target models. In IROS, 2011. 2
[43] T. Malisiewicz, A. Gupta, and A. A. Efros. Ensemble of exemplar-svms for object detection and beyond. In ICCV, 2011. 7
[44] J. Mason, B. Marthi, and R. Parr. Object disappearance for object discovery. In IROS, 2012. 2
[45] O. Mattausch, D. Panozzo, C. Mura, O. Sorkine-Hornung, and R. Pajarola. Object detection and classification from large-scale cluttered indoor scans. In Computer Graphics Forum, 2014. 2
[46] S. Meister, S. Izadi, P. Kohli, M. Hammerle, C. Rother, and ¨ D. Kondermann. When can we use kinectfusion for ground truth acquisition? In Proc. Workshop on Color-Depth Camera Fusion in Robotics, 2012. 2
[47] A. Mian, M. Bennamoun, and R. Owens. On the repeatability and quality of keypoints for local feature-based 3d object retrieval from cluttered scenes. IJCV, 2010. 2
[48] R. Min, N. Kose, and J.-L. Dugelay. Kinectfacedb: A kinect database for face recognition. 2
[49] P. K. Nathan Silberman, Derek Hoiem and R. Fergus. Indoor segmentation and support inference from rgbd images. In ECCV, 2012. 1, 2, 4, 7
[50] B. Ni, G. Wang, and P. Moulin. Rgbd-hudaact: A color-depth video database for human daily activity recognition. 2011. 2
[51] A. Oliva and A. Torralba. Modeling the shape of the scene: A holistic representation of the spatial envelope. IJCV, 2001.5, 7
[52] F. Pomerleau, S. Magnenat, F. Colas, M. Liu, and R. Siegwart. Tracking a depth camera: Parameter exploration for fast icp. In IROS, 2011. 2
[53] X. Ren, L. Bo, and D. Fox. Rgb-(d) scene labeling: Features and algorithms. In CVPR, 2012. 1, 2, 6, 7
[54] A. Richtsfeld, T. Morwald, J. Prankl, M. Zillich, and M. Vincze. Segmentation of unknown objects in indoor environments. In IROS, 2012. 2
[55] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman. Labelme: a database and web-based tool for image annotation. IJCV, 2008. 4
[56] J. Shotton, R. Girshick, A. Fitzgibbon, T. Sharp, M. Cook, M. Finocchio, R. Moore, P. Kohli, A. Criminisi, A. Kipman, et al. Efficient human pose estimation from single depth images. PAMI, 2013. 1
[57] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. In CVPR, 2013. 2
[58] J. Shotton, T. Sharp, A. Kipman, A. Fitzgibbon, M. Finocchio, A. Blake, M. Cook, and R. Moore. Real-time human pose recognition in parts from single depth images. Communications of the ACM, 2013. 1
[59] A. Shrivastava and A. Gupta. Building part-based object detectors via 3d geometry. In ICCV, 2013. 2
[60] N. Silberman and R. Fergus. Indoor scene segmentation using a structured light sensor. In Proceedings of the International Conference on Computer Vision - Workshop on 3D Representation and Recognition, 2011. 2
[61] A. Singh, J. Sha, K. S. Narayan, T. Achim, and P. Abbeel. Bigbird: A large-scale 3d database of object instances. In ICRA, 2014. 2
[62] S. Song and J. Xiao. Sliding Shapes for 3D object detection in RGB-D images. In ECCV, 2014. 2, 6, 7
[63] L. Spinello and K. O. Arras. People detection in rgb-d data. In IROS, 2011. 2
[64] S. Stein and S. J. McKenna. Combining embedded accelerometers with computer vision for recognizing food preparation activities. In Proceedings of the 2013 ACM international joint conference on Pervasive and ubiquitous computing, 2013. 2
[65] S. Stein and S. J. McKenna. User-adaptive models for recognizing food preparation activities. 2013. 2
[66] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers. A benchmark for the evaluation of rgb-d slam systems. In IROS, 2012. 2
[67] J. Sung, C. Ponce, B. Selman, and A. Saxena. Human activity detection from rgbd images. Plan, Activity, and Intent Recognition, 2011. 2
[68] A. Torralba and A. A. Efros. Unbiased look at dataset bias. In CVPR, 2011. 8
[69] Z. Wu, S. Song, A. Khosla, X. Tang, and J. Xiao. 3D ShapeNets: A deep representation for volumetric shape modeling. CVPR, 2015. 2
[70] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba. SUN database: Large-scale scene recognition from abbey to zoo. In CVPR, 2010. 5, 7
[71] J. Xiao, J. Hays, B. C. Russell, G. Patterson, K. Ehinger, A. Torralba, and A. Oliva. Basic level scene understanding: Categories, attributes and structures. Frontiers in Psychology, 4(506), 2013. 6
[72] J. Xiao, A. Owens, and A. Torralba. SUN3D: A database of big spaces reconstructed using SfM and object labels. In
ICCV, 2013. 1, 2, 3, 4
[73] B. Zeisl, K. Koser, and M. Pollefeys. Automatic registration of rgb-d scans via salient directions. In ICCV, 2013. 2
[74] J. Zhang, C. Kan, A. G. Schwing, and R. Urtasun. Estimating the 3d layout of indoor scenes and its clutter from depth sensors. In ICCV, 2013. 2, 5, 7
[75] B. Zhou, J. Xiao, A. Lapedriza, A. Torralba, and A. Oliva. Learning deep features for scene recognition using places database. In NIPS, 2014. 5, 7