深度学习-tensorflow2:03 - AI写诗
简介:利用tensorflow2框架,基于循环神经网络(RNN)的长短期记忆神经网络(LSTM)的生成算法,可以让AI生成诗歌,功能可以根据用户输入的起始字、意境等自定义参数生成诗歌。生成的每一首诗歌都是独一无二的,当然内容有些狗屁不通。
原作者github项目地址:
https://github.com/Stevengz/Poem_compose
历史攻略:
深度学习:win10安装TensorFlow
项目目录结构:
data.npy
ix2word.npy
tang.zip:唐诗数据集
test.py:测试运行最终结果
train.py:训练主体程序
training_checkpoints:训练结果
word2ix.npy
案例源码:请参考原作者github项目地址
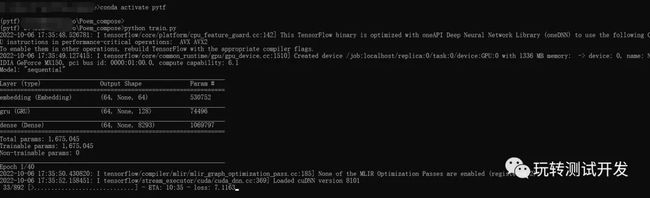
训练执行:python train.py
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import losses
import numpy as np
import os
# 导入数据集
data = np.load('data.npy', allow_pickle=True).tolist()
data_line = np.array([word for poem in data for word in poem])
ix2word = np.load('ix2word.npy', allow_pickle=True).item()
word2ix = np.load('word2ix.npy', allow_pickle=True).item()
# 构建模型的函数
def GRU_model(vocab_size, embedding_dim, units, batch_size):
model = keras.Sequential([
layers.Embedding(vocab_size,
embedding_dim,
batch_input_shape=[batch_size, None]),
layers.GRU(units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
layers.Dense(vocab_size)
])
return model
# 切分成输入和输出
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
# 损失函数
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
# 每批大小
BATCH_SIZE = 64
# 缓冲区大小
BUFFER_SIZE = 10000
# 训练周期
EPOCHS = 40
# 诗的长度
poem_size = 125
# 嵌入的维度
embedding_dim = 64
# RNN 的单元数量
units = 128
# 创建训练样本
poem_dataset = tf.data.Dataset.from_tensor_slices(data_line)
# 将每首诗提取出来并切分成输入输出
poems = poem_dataset.batch(poem_size + 1, drop_remainder=True)
dataset = poems.map(split_input_target)
# 分批并随机打乱
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
# 创建模型
model = GRU_model(vocab_size=len(ix2word),
embedding_dim=embedding_dim,
units=units,
batch_size=BATCH_SIZE)
model.summary()
model.compile(optimizer='adam', loss=loss)
# 检查点目录
checkpoint_dir = './training_checkpoints'
# 检查点设置
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix, save_weights_only=True)
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
训练中的运行结果:
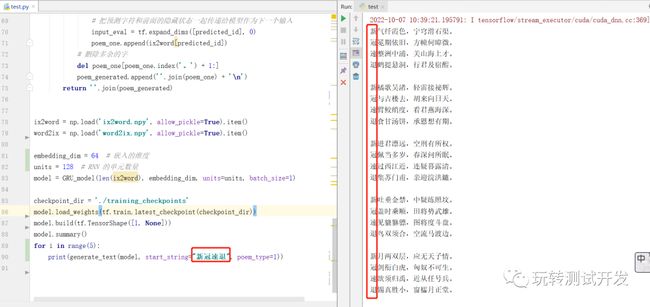
测试和生成诗句:test.py
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
def GRU_model(vocab_size, embedding_dim, units, batch_size):
model = keras.Sequential([
layers.Embedding(vocab_size,
embedding_dim,
batch_input_shape=[batch_size, None]),
layers.GRU(units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
# layers.GRU(units),
layers.Dense(vocab_size)
])
return model
# poem_type 为 0 表示整体生成,为 1 表示生成藏头诗
def generate_text(model, start_string, poem_type):
# 控制诗句意境
prefix_words = '白日依山尽,黄河入海流。欲穷千里目,更上一层楼。'
num_generate = 20 # 要生成的字符个数
poem_generated = [] # 空字符串用于存储结果
temperature = 1.0
# 以开头正常生成
if poem_type == 0:
# 将整个输入直接导入
input_eval = [word2ix[s] for s in prefix_words + start_string]
# 添加开始标识
input_eval.insert(0, word2ix['' ])
input_eval = tf.expand_dims(input_eval, 0)
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
# 删除批次的维度
predictions = tf.squeeze(predictions, 0)
# 用分类分布预测模型返回的字符
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions,
num_samples=1)[-1, 0].numpy()
# 把预测字符和前面的隐藏状态一起传递给模型作为下一个输入
input_eval = tf.expand_dims([predicted_id], 0)
poem_generated.append(ix2word[predicted_id])
# 删除多余的字
del poem_generated[poem_generated.index('' ):]
return (start_string + ''.join(poem_generated))
# 藏头诗
if poem_type == 1:
for i in range(len(start_string)):
# 藏头诗以每个字分别生成诗句
input_eval = [word2ix[s] for s in prefix_words + start_string[i]]
input_eval.insert(0, word2ix['' ])
input_eval = tf.expand_dims(input_eval, 0)
model.reset_states()
poem_one = [start_string[i]]
for j in range(num_generate):
predictions = model(input_eval)
# 删除批次的维度
predictions = tf.squeeze(predictions, 0)
# 用分类分布预测模型返回的字符
predictions = predictions / temperature
predicted_id = tf.random.categorical(
predictions, num_samples=1)[-1, 0].numpy()
# 把预测字符和前面的隐藏状态一起传递给模型作为下一个输入
input_eval = tf.expand_dims([predicted_id], 0)
poem_one.append(ix2word[predicted_id])
# 删除多余的字
del poem_one[poem_one.index('。') + 1:]
poem_generated.append(''.join(poem_one) + '\n')
return ''.join(poem_generated)
ix2word = np.load('ix2word.npy', allow_pickle=True).item()
word2ix = np.load('word2ix.npy', allow_pickle=True).item()
embedding_dim = 64 # 嵌入的维度
units = 128 # RNN 的单元数量
model = GRU_model(len(ix2word), embedding_dim, units=units, batch_size=1)
checkpoint_dir = './training_checkpoints'
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))
model.summary()
for i in range(5):
print(generate_text(model, start_string="新冠速退", poem_type=1))
运行结果: