【基础知识】---BN层相关原理详解
在神经网络中, 数据分布对训练会产生影响. 比如某个神经元 x 的值为1, 某个 Weights 的初始值为 0.1, 这样后一层神经元计算结果就是 Wx = 0.1; 又或者 x = 20, 这样 Wx 的结果就为 2. 现在还不能看出什么问题, 但是, 当我们加上一层激励函数, 激活这个 Wx 值的时候, 问题就来了. 如果使用 像 tanh 的激励函数, Wx 的激活值就变成了 ~0.1 和 ~1, 接近于 1 的部已经处在了 激励函数的饱和阶段, 也就是如果 x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感了. 这样很糟糕, 想象我轻轻拍自己的感觉和重重打自己的感觉居然没什么差别, 这就证明我的感官系统失效了. 当然我们是可以用之前提到的对数据做 normalization 预处理, 使得输入的 x 变化范围不会太大, 让输入值经过激励函数的敏感部分. 但刚刚这个不敏感问题不仅仅发生在神经网络的输入层, 而且在隐藏层中也经常会发生.
只是时候 x 换到了隐藏层当中, 我们能不能对隐藏层的输入结果进行像之前那样的normalization 处理呢? 答案是可以的, 因为大牛们发明了一种技术, 叫做 batch normalization, 正是处理这种情况.

1 训练数据为什么要和测试数据同分布?
看看下图,如果我们的网络在左上角的数据训练的,已经找到了两者的分隔面w,如果测试数据是右下角这样子,跟训练数据完全不在同一个分布上面,你觉得泛化能力能好吗?

2 为什么白化训练数据能够加速训练进程
如下图,训练数据如果分布在右上角,我们在初始化网络参数w和b的时候,可能得到的分界面是左下角那些线,需要经过训练不断调整才能得到穿过数据点的分界面,这个就使训练过程变慢了;如果我们将数据白化后,均值为0,方差为1,各个维度数据去相关,得到的数据点就是坐标上的一个圆形分布,如下图中间的数据点,这时候随便初始化一个w,b设置为0,得到的分界面已经穿过数据了,因此训练调整,训练进程会加快
3 什么是梯度爆炸
如果网络使用sigmod激活函数,误差在向前传递的时候,经过sigmod单元,需要乘sigmod的梯度,而sigmod的梯度最大是0.25,因此越向前传递,误差就越小了,这就是梯度消散,但是梯度爆炸是什么?注意误差在经过全连接或者卷积层时,也要乘以权重w,如果w都比较大,大过sigmod造成的减小,这样越往前误差就越来越大,梯度爆炸了!
4 为什么BN层可以加速网络收敛速度
减去平均数再除以标准差相当于对原始数据进行了线性变换,没有改变数据之间的相对位置,改变了数据的分布(此分布指数学上的概率密度分布,值域,定义域都变了),变成了近似正态分布,数据的平均数变成0,标准差变成1。各个维度数据去相关,得到的数据点就是坐标上的一个圆形分布,如下图中间的数据点,这时候随便初始化一个w,b设置为0,得到的分界面已经穿过数据了,因此训练调整,训练进程会加快
原理如上面2类似,BN层的计算图如下面所示,x是输入数据,到xhat均值方差归一化,也就是类似2中白化的加速的原理,后面xhat到y其实就是普通的一个线性变换,类似全连接但是没有交叉,将这个线性变换和后面的网络看成一体的,是不是就跟2中情况一样了?如果没有BN层,x直接输入后面的网络,训练过程中x分布的变换必然导致后面的网络去调整学习以来适应x的均值和方差,映入了BN层,xhat是一个归一化的数据,代价就是网络中多了一个线性层y,但是前者带来的性能更加大,因此加速了。

我们引入一些 batch normalization 的公式. 这三步就是我们在刚刚一直说的 normalization 工序, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.
后面想想,感觉还是有点不清楚,虽然xhat是个归一化分布,但是y不一定是啊,最终是y输入到子网络,对原网络不一定有效吧?这里怀疑真正对加速起作用的是xhat到y的变换,这种单独对维度的线性变换只是在全连接的基础上少了输入输出间的交叉连接,这种形式的变换可能非常有利于分布的调整,如果在网络输入最前端加入这样一层,那岂不是无需对输入进行归一化了?后面有时间进行验证。那是不是x到xhat的变换就可以去掉了呢?不是,x到xhat的变换作用是缓解梯度弥散,这一点可以看下下面一点
5 为什么BN层可以改善梯度弥散
下面xhat到x的梯度公式,可以表示为正常梯度乘一个系数a,再加b,这里加了个b,整体给梯度一个提升,补偿sigmod上的损失,改善了梯度弥散问题。


6 为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
原文中是这样解释的,因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。其实想想也是的,像relu这样的激活函数,如果你输入的数据是一个高斯分布,经过他变换出来的数据能是一个什么形状?小于0的被抑制了,也就是分布小于0的部分直接变成0了,这样不是很高斯了。
补充

之前说过, 计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 normalization, 下者进行了 normalization, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程.
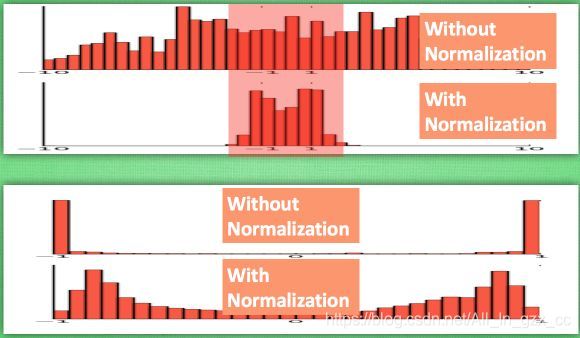
没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 他还进行了反 normalize 的手续. 为什么要这样呢?见第4条分析。

最后我们来看看一张神经网络训练到最后, 代表了每层输出值的结果的分布图. 这样我们就能一眼看出 Batch normalization 的功效啦. 让每一层的值在有效的范围内传递下去.
优点
- 训练的更快
因为在每一轮训练中的前向传播和反响传播的额外计算会造成更慢的训练。Batch normalization可以让收敛速度更快。总的训练时间更短。
- 容忍更高的学习率(learning rate)
为了网络能收敛,梯度下降通常需要更小的学习率。但是神经网络的层次越深,则反响传播时梯度越来越小,因此需要更多的训练迭代次数。Batch normalization可以容忍更高的学习率,则梯度下降的幅度更大,也就加快了训练的速度。
- 让权重更容易初始化
权重的初始化通常来说比较麻烦,尤其是深层的神经网络。Batch normalization可以降低权重初始化的值的分布的影响。
- 可支持更多的激活函数
有些激活函数在某些场景下表现很差。比如Sigmoid的随层次的增加梯度衰减的俄很快,也就无法用在深层的神经网络。ReLU的问题是可能导致神经元的死亡(即ReLU掉入0的区域),所以我们要小心输入他的值的范围。Batch normalization可以规范化输入,这些激活函数也可以使用了。
- 简化创建深层的神经网络
以上四点就降低了创建神经网络的要求,可以创建更深层的神经网络,而更深层的网络也更有机会表现的更好。
- 提供了一点正则化的功能
虽然Batch normalization 在某些情况下增加了一些网络的噪声。在Inception模型中,Batch normalization 起到了和dropout一样的正则化效果。考虑用Batch normalization 替代一些dropout的情况。
可能得到更好的结果
一些实验结果表明Batch normalization 可以提高训练的表现。不过他主要还是用优化训练,让训练更快的方面。因为他能让你的网络训练的更快,你就能比不用Batch normalization 的时候迭代更多次或者收敛的更快。他也能让你构建更深的网络,深的网络有机会表现的更好。