项目:广告点击预测率评估
背景:一方面有流量的企业希望最大化广告收益;另一方面需要流量的个体希望最小化广告投放成本但同时最大化效果,这就是一个博弈的过程。
目前市面上流行的百度信息流、微信朋友圈投广都是基于这类的博弈过程。你可以设想一下: 假如有几家公司想在百度投放广告,但是广告位是有限的,那这时候该选择哪一家的广告呢? 这里就有一个很关键的概念,叫作竞价!
也就是谁出的钱越多,就放谁的, 但这里有一个很重要的前提:是否用户会点击广告! 如果一个用户没有点击广告其实也赚不到钱,即便出价很高。所以这就衍生出了一个极其重要的问题:如何提升用户的点击率?
所以除了价格,AI算法也需要通过判断一个广告被一个用户点击的概率来决定要不要呈现给这个用户。这就是广告点击率问题。
一个用户属性和广告属性匹配时,点击率自然会变高。那具体的匹配的概率又如何计算呢? 这就是这次项目要解决的问题。
The project is from Kaggle, Avazu
https://www.kaggle.com/c/avazu-ctr-prediction
在项目里,也需要用到特征选择、参数搜索、以及F1的评估方法。
准确率(Accuracy)
acc = # of correct / # of total
准确率的缺陷
假设实际1000个病人里有2个人有癌症,
一个系统对于所有的检测,都判断为非癌症,那么
准确率 = 998 / 1000 = 99.8% 但是这种数据没有意义(因为样本不均衡,负样本少)。
Data imbalance

精确率(precision):
召回率(Recall):

对于正常邮件的精确率:
Precision:被AI算法识别并且确实是正常邮件的数量 / 所有被AI算法识别为正常邮件的数量
Recall: 被AI算法识别并且确实是正常邮件的数量 / 实际所有正常邮件的数量
对于垃圾邮件的精确率:
Precision: 被AI算法识别并且确实是垃圾邮件的数量 / 所有被AI算法识别为垃圾邮件的数量
Recall: 被AI算法识别并且确实是垃圾邮件的数量 / 实际所有垃圾邮件的数量
两个关系互斥
F1-Score

如果我们使用F1-Score, 这个值越大,就意味着模型表现越好。 当我们计算完每一个类别的F1-Score之后,可以通过求它们的平均来获得最终整体的F1-score。
特征选择技术:
这也是建模过程中最为核心的部分。因为不一定所有的特征都有效,而且特征里包含的噪声也会影响着模型的效果。
所以,最直接的方式就是:在建模前做一次特征选择,只保留有价值的特征。
常见方法:
特征多容易导致模型过拟合,有些特征是噪声

1)尝试所有的组合:

复杂度是指数级组合,只适合特征数少的情况
2)贪心算法:
stop-wise forward selection

这种方法必须要结合具体某一种模型一起使用。这也就说,如果我们使用的模型不一样,则选出来的特征也可能是不一样的。比如一开始使用了逻辑回归,但之后改换成神经网络,那这时候就需要重新进行特征的选择。
3) 基于L1正则的特征选择

会是模型复杂,梯度连续被破坏,实际工业界很少使用L1正则
L1正则特别适用于样本量少,但特征维度特别高的情况。一个经典的场景就是神经科学。如果把每个人大脑里的神经元看作是特征,那这个特征维度非常之高。另外,我们也知道这个领域的样本是非常昂贵的。
4)基于树模型的特征选择(决策树算法)
一般根节点重要性最高, 第二层次重要,以此类推
特征排序,

5)相关性计算

Chi-square test
https://blog.csdn.net/CHCH998/article/details/81019815
Pearson Correlation
https://blog.csdn.net/chao2016/article/details/80917579
Feature Selection
https://scikit-learn.org/stable/modules/feature_selection.html
GridSearchCV and Bayesian Optimization
The stragety for hyperparameter

The GridSearchCV support parallelism
Heuristic Algorithm
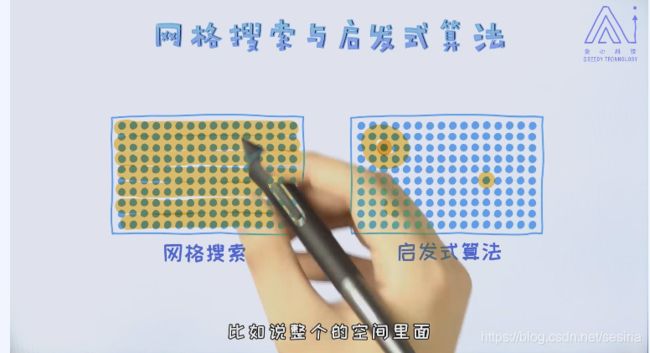
Genetic Algorithm
http://www.sohu.com/a/228201142_609518
Bayesian Optimization
https://www.cs.princeton.edu/~rpa/