- Low Power概念介绍-Voltage Area
飞奔的大虎
随着智能手机,以及物联网的普及,芯片功耗的问题最近几年得到了越来越多的重视。为了实现集成电路的低功耗设计目标,我们需要在系统设计阶段就采用低功耗设计的方案。而且,随着设计流程的逐步推进,到了芯片后端设计阶段,降低芯片功耗的方法已经很少了,节省的功耗百分比也不断下降。芯片的功耗主要由静态功耗(staticleakagepower)和动态功耗(dynamicpower)构成。静态功耗主要是指电路处于等
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- 基于STM32与Qt的自动平衡机器人:从控制到人机交互的的详细设计流程
极客小张
stm32qt机器人物联网人机交互毕业设计c语言
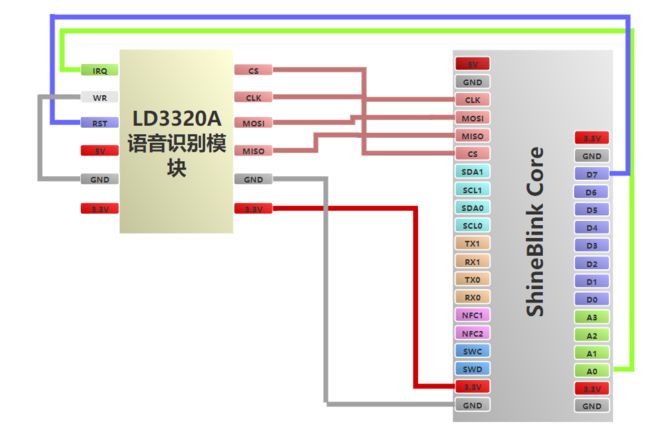
一、项目概述目标和用途本项目旨在开发一款基于STM32控制的自动平衡机器人,结合步进电机和陀螺仪传感器,实现对平衡机器人的精确控制。该机器人可以用于教育、科研、娱乐等多个领域,帮助用户了解自动控制、机器人运动学等相关知识。技术栈关键词STM32单片机步进电机陀螺仪传感器AD采集电路Qt人机界面实时数据监控二、系统架构系统架构设计本项目的系统架构设计包括以下主要组件:控制单元:STM32单片机传感器
- 助力新能源汽车产业发展,2025第五届广州国际新能源汽车产业智能制造技术展览会将于11月在广州召开
ws201907
制造汽车
助力新能源汽车产业发展,2025第五届广州国际新能源汽车产业智能制造技术展览会将于11月在广州召开伴随着全球新一轮科技革命和产业变革,汽车与能源、半导体、物联网等领域有关技术加速融合,新能源汽车已成为全球汽车产业转型升级的主要方向。近年来,在相关政策的影响下,新能源汽车市场呈现出快速增长的态势,市场规模不断扩大。截至2020年,中国新能源汽车保有量已超过500万辆,成为全球最大的新能源汽车市场。随
- 51单片机——I2C总线存储器24C02的应用
老侯(Old monkey)
51单片机嵌入式硬件单片机
目标实现功能单片机先向24C02写入256个字节的数据,再从24C02中一次读取2个字节的数据、并在数码管上动态显示,直至读完24C02中256个字节的数据。1.I2C总线简介I2C总线有两根双向的信号线,一根是数据线SDA,另一根是时钟线SCL。I2C总线通过上拉电阻接正电源,因此,当总线空闲时为高电平。2.I2C通信协议起始信号、停止信号由主机发出。在数据传送时,当时钟线为高电平时,数据线上的
- 嵌入式单片机中数码管基本实现方法
嵌入式开发星球
单片机项目实战操作之优秀单片机
1.点亮数码管本节课利用已经学习的LED知识去控制一个8位数码管。本节的原理比较简单。不需要多少时间讲。更多时间是跟大家一起编码调试,从中学习一些编码思路和学习方法。1.1.什么是数码管数码管是什么?下图就是一个数码管从硬件上个看,其实就是8个LED组合在一起。8个LED应该有16个引脚,但是数码管上只有10个引脚。为什么呢?请看下图:1个LED有两个引脚,要控制LED,1个引脚接控制信号,另外一
- 【C#生态园】深度剖析:C#嵌入式开发工具大揭秘
friklogff
C#生态园c#开发语言
C#嵌入式开发:全面了解六大框架与库前言随着物联网和嵌入式系统的快速发展,越来越多的开发者开始关注使用C#语言进行嵌入式开发。本文将介绍几种用于C#的嵌入式开发框架和相关库,以及它们的核心功能、安装配置方法和API概览,帮助读者了解并选择适合自己项目的工具和资源。欢迎订阅专栏:C#生态园文章目录C#嵌入式开发:全面了解六大框架与库前言1.nanoFramework:一个用于C#的嵌入式开发框架1.
- 4×4矩阵键盘详解(STM32)
辰哥单片机设计
STM32传感器教学矩阵计算机外设stm32嵌入式硬件单片机传感器
目录一、介绍二、传感器原理1.原理图2.工作原理介绍三、程序设计main.c文件button4_4.h文件button4_4.c文件四、实验效果五、资料获取项目分享一、介绍矩阵键盘,又称为行列式键盘,是用4条I/O线作为行线,4条I/O线作为列线组成的键盘。在行线和列线的每一个交叉点上设置一个按键,因此键盘中按键的个数是4×4个。这种行列式键盘结构能够有效地提高单片机系统中I/O口的利用率,节约单
- SAP IoT能力揭秘
小哈公社
SAP是企业软件行业的一哥,不过一哥也要拓展地盘。物联网(IoT)就是SAP最近很想占据的新地盘,让我们来看看SAP有些什么新菜端上桌。很多人都知道SAP推出了Leonardo这个最新的产品组合,其中就包括了物联网(InternetofThings,IoT)解决方案。SAP试图在Leonardo这个产品中把未来企业数字化转型所需的各种功能都包括进来,而IoT就是相当重要的一块拼图。Leonardo
- 学单片机怎么在3-5个月内找到工作?
无际单片机编程
单片机嵌入式开发物联网stm32c语言
每个初学者,都如履薄冰,10几年前,我自学单片机时,也一样。想通过学习,找一份体面点的工作,又害怕辛辛苦苦学出来,找不到工作。好在,当初执行力,还算可以,自学java没成功,后面自学单片机,成功入行了。转眼间,毕业到现在有13年了,马上也到了奔4的年纪。这13年一直在跟单片机打交道,打过工,创过业,对行业,对企业,都有一定的认知,坚持看完这篇内容,相信能帮你少走几个月弯路。有些老铁,加了我很久,时
- 【物联网技术大作业】设计一个智能家居的应用场景
Dream_Chaser~
期末复习智能家居物联网技术期末大作业
前言:本人的物联网技术的期末大作业,希望对你有帮助。目录大作业设计题(1)智能家居的概述。(2)介绍智能家居应用。要求至少5个方面的应用,包括每个应用所采用的设备,性能,功能。(3)画出智能家居应用图,并设计使用。大作业设计题设计一个智能家居的应用场景。要求:(1)智能家居的概述。答:智能家居,又称为智能住宅或家庭自动化,是指运用综合布线、网络通信、安全防范、自动控制及音视频等技术,将家居设施集成
- 【数字化供应链】数字化供应链架构、全景管理、全流程贯通方案
数字化建设方案
数字化转型数据治理主数据数据仓库供应链数字仓储智慧物流智慧仓储物流园区架构微服务数据挖掘大数据人工智能
原文《数字化供应链架构、全景管理、全流程贯通方案》PPT格式。主要从供应链管理全景、智慧供应链建设总体目标、供应链总体业务流程、供应链总体功能架构、供应链总体技术架构、供应链全流程贯通、供应链全领域管理、供应链数据数据分析、供应链决策中台等进行建设。本文仅对主要内容进行介绍。来源网络公开渠道,旨在交流学习,如有侵权联系速删,更多参考公众号:优享智库基于先进IT技术、大数据能力、物联网应用、区块链平
- 数字化智能工厂数字化供应链架构、全景管理、全流程贯通方案
数字化建设方案
智能制造数字工厂制造业数字化转型工业互联网架构
随着信息技术的飞速发展,数字化转型已成为制造企业提升竞争力的关键途径。数字化智能工厂通过集成先进的物联网(IoT)、大数据、云计算、人工智能(AI)等技术,实现了生产过程的智能化、供应链管理的精准化及决策的科学化。本方案旨在构建一套完善的数字化供应链架构,实现全景管理、全流程贯通、智慧化升级,以数据为驱动,强化技术支撑与安全管理体系,推动企业向智能制造迈进。一、数字化供应链架构1.**集成化平台构
- 51单片机:P3.3口输入/P 1口输出实验
li星野
单片机
51单片机:P3.3口输入/P1口输出实验一、实验内容1P3.3口做输入口,外接一脉冲,每输入一个脉冲,P1口按十六进制除2(乘2)。2.P1口做输出口,P1口接的8个发光二极管L1—L8按十六进制除2(乘2)方式点亮。二、仿真图三、代码实现C语言实现:#include#includesbitKEY=P3^3;voiddelay10ms(void);voidmain(){charnum=0xfe;
- 2020-11-12 写单片机内存的脚本 nc openocd 事务自动测试
linuxScripter
这是写单片机内存的脚本:z@z-ThinkPad-T400:~/zworkT400/EDA_heiche/zREPOgit/simple-gcc-stm32-project$catz.wholeRun.oneCase.cmdcattmp6.toWrite|awk'{system("echomwb"$1""$2"|nclocalhost4444");}'catUSER/DEBUG/debug.h|g
- 高职人工智能训练师边缘计算实训室解决方案
武汉唯众智创
人工智能训练师边缘计算实训室人工智能训练师实训室边缘计算实训室
一、引言随着物联网(IoT)、大数据、人工智能(AI)等技术的飞速发展,计算需求日益复杂和多样化。传统的云计算模式虽在一定程度上满足了这些需求,但在处理海量数据、保障实时性与安全性、提升计算效率等方面仍面临诸多挑战。在此背景下,边缘计算作为一种新兴的计算模式应运而生,通过将计算能力推向数据生成或用户所在的网络边缘,显著降低了数据传输的延迟,提升了处理效率,并增强了数据安全性。针对高等职业院校的人工
- 工业智能网关在工业生产中的核心作用-天拓四方
weixin_36369259
随着工业4.0时代的到来,物联网(IoT)和智能制造技术日益成熟,工业智能网关作为连接工业设备与物联网系统的关键设备,正逐步成为现代工业生产不可或缺的重要组成部分。本文将详细探讨工业智能网关在工业生产中的多重作用,揭示其如何助力企业实现数字化转型与智能化管理。一、工业智能网关概述工业智能网关,也称为工业物联网网关、工业边缘计算网关等,是一种专为工业环境设计的网络连接设备。它集成了数据采集、传输、协
- 单片机中断
woainizhongguo.
STM32单片机原理解析篇单片机嵌入式硬件
**在51单片机中,中断向量表的地址是如何被设置的?**在51单片机中,中断向量表的设置是中断系统的核心部分,它定义了中断服务程序的入口地址。以下是中断向量表的设置方法:中断向量表的位置:51单片机的中断向量表通常位于程序存储器的起始位置,即地址0x0000到0x000F(对于双字节的中断向量,实际占用0x0000到0x001F)。这些地址是固定的,由单片机的硬件设计决定。中断向量的分配:每个中断
- 数字化(电子化)招标采购平台系统核心功能详细介绍
xinyuan_123456
oracle
数智化招标采购平台覆盖全业务类型、全采购流程、全采购方式,是郑州信源公司运用“互联网+”、大数据、人工智能、区块链、物联网等新兴技术,结合供应链管理理念,以招标采购为核心,提供交易、管理、数据、服务、监管为一体的高标准采购管理平台,赋能政企用户实现采购业务全流程的电子化、数字化、智慧化。根据产品功能及应用领域,产品包括:企业数智化招采供应链平台、金融数智化招采平台、政府数智化采购平台、公共资源数智
- 数据结构.
小珑也要变强
数据结构
文章目录自我介绍数据结构基础概念简介线性结构和非线性结构线性结构非线性结构前驱和后继你的点赞评论就是对博主最大的鼓励当然喜欢的小伙伴可以:点赞+关注+评论+收藏(一键四连)哦~自我介绍 Hello,大家好,我是小珑也要变强(也是小珑),我是易编程·终身成长社群的一名“创始团队·嘉宾”和“内容共创官”,现在我来为大家介绍一下有关物联网-嵌入式方面的内容。数据结构基础概念简介 1968年美国克务特
- 新质农业-再生农业的应用
橙蜂智农
人工智能制造创业创新
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、埃域知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。橙蜂智农的智慧农业产品涵盖了多方面的功能,如智能化推荐、数据分析、远程监控和决策支持系统。用户可以通过应用获得个性化的作物种植建议、实时的生长状态监控以及精确的灌溉和施肥指导,提升农业生产效率。文
- 当水泵遇上物联网:智能水务新时代的浪漫交响
蓝蜂物联网
PLC远程下载物联网网关PLC远程控制物联网信息可视化
在当代科技的宏伟乐章中,物联网(IoT)技术宛如一位技艺高超的指挥家,引领着各行各业迈向智能化的新纪元。当这股创新浪潮涌向古老的水务行业时,一场前所未有的“智能水务”革命便悄然上演,而水泵——这一传统水利设施的核心组件,也在这场变革中被赋予了全新的角色与使命,成为了智能水务新时代浪漫交响中的一个动人音符。智能化的脉动:水泵与物联网的融合传统水泵,作为输送水资源的“心脏”,长久以来承担着调节水流、保
- 一文看懂物联网通信技术
SEEKSEE AIoT
物联网
无线通信传输是实现万物互联的重要环节,其在传输速度及成本方面具有显著优势。今天我们将一起聊聊物联网无线通信的几种常见类型,了解其优势及应用。你好!物联网的无线通信技术种类繁多,从通信距离上可分为短距离(近距离)无线通信技术和低功耗广域网(远距离)通信技术。近距离通信技术包括Wi-Fi、蓝牙、ZigBee等,远距离通信技术以2G/3G/4G/5G、LPWAN(NB-IoT、eMTC、LoRa等)为代
- 三相电表智能抄表是什么?
BZWL_BZWL
自动化运维人工智能数据分析大数据
一、三相电表智能抄表简述三相电表智能抄表操作系统是电力领域科学化管理不可或缺的一部分,它利用先进的物联网,完成了对三相电表数据库的自动采集、传送、解决与分析,大大提升了电力经营效率和服务水平。二、原理与优势1.原理:智能电表内嵌感应器,可精准测量三相电电压、电流和功率等数据。这些信息根据无线通讯模块(如GPRS、NB-IoT等)传送到云服务器,完成智能抄表。与此同时,电度表还能实时检测电网情况,防
- 4G MQTT网关在物联网应用中的优势-天拓四方
北京天拓四方
边缘计算iot物联网其他
随着物联网(IoT)技术的飞速发展,各种设备和系统之间的互联互通变得日益重要。MQTT(MessageQueuingTelemetryTransport)作为一种轻量级的发布/订阅消息传输协议,因其高效、可靠、简单的特性,在物联网领域得到了广泛的应用。而4GMQTT网关,作为连接物联网设备和MQTT服务器的桥梁,其在物联网应用中的作用愈发凸显。本文将探讨4GMQTT网关在物联网应用中的优势。4GM
- 4G物联网智能电表是什么?什么叫4G物联网智能电表?
HZZD_HZZD
物联网人工智能服务器数据分析大数据数据库
4G物联网智能电表是一种结合了4G无线通信技术的新型电能计量设备,用于实时采集和传输用户的用电数据。它通过集成现代信息技术和电力电子技术,不仅能够精确测量电力消耗,还能实现远程数据传输、数据分析、远程控制等多种功能。本文将详细介绍4G物联网智能电表的主要功能、技术优势及其应用场景。一、定义与功能1.定义4G物联网智能电表是一种能够通过4G网络将电能消耗数据实时传输到电力公司或数据中心的智能计量设备
- 华为 HCIP 认证费用和报名资格
咕噜Yuki0609
华为培训认证HCIP华为认证
在当今竞争激烈的信息技术领域,华为HCIP认证备受关注。它不仅能提升个人的技术实力与职业竞争力,也为企业选拔优秀人才提供了重要依据。以下将详细介绍华为HCIP认证的费用和报名资格。一、HCIP认证费用华为HCIP认证的费用主要由考试费和培训费构成。1.考试费用:根据不同的技术方向,考试费用有所差异。例如,数通、安全等方向的考试费用通常为480美元;WLAN方向的考试费用为600美元;物联网方向的考
- 基于STC12C5A60S2单片机的LED汉字显示系统的设计
lantiandianzi
单片机嵌入式硬件
本设计基于单片机的LED汉字显示装置,该设计以STC12C5A60S2单片机为核心,利用最小系统和多个模块完成设计,包括点阵驱动模块、时钟模块、串口通信模块、红外线接收模块以及LED点阵屏。其中,点阵驱动模块采用74HC245芯片设计完成,结合DS1302时钟芯片完成LED点阵显示屏的汉字与时间显示,使用按键、串口、红外线遥控可以完成时间的实时更新、自定义汉字显示、改变汉字显示颜色、改变汉字滚动方
- 51单片机-AT24C02-实验2-秒表实验(可参考上一节)
Whappy001
51单片机嵌入式硬件单片机
利用定时器去对按键和数码管进行扫描(Whappy)main.c#include#include"LCD1602.h"#include"AT24C02.h"#include"Delay.h"#include"Timer0.h"#include"Nixie.h"#include"Key.h"unsignedcharKeyNum;unsignedcharMin,Sec,MiniSec;unsignedc
- 绿色智慧档案馆构想之智慧档案馆环境综合管控一体化平台
盛世宏博智慧档案
智慧档案馆智慧档案馆
【智慧档案馆整体效果图】智慧档案库房一体化平台通过智慧档案管理,实现智慧档案感知协同处置功能;实现对档案实体的智能化识别、定位、跟踪监控;实现对档案至智能密集架、空气恒湿净化一体设备、安防设备,门禁设备等智能化巡检与即时处理。智慧档案平台基于物联网、云计算、大数据、档案人健康防护、档案安全防护等新技术,实现了对档案的收、管、存、用全业务流程管理;实现了对档案实体资源与数字资源的集中建设与管理;实现
- knob UI插件使用
换个号韩国红果果
JavaScriptjsonpknob
图形是用canvas绘制的
js代码
var paras = {
max:800,
min:100,
skin:'tron',//button type
thickness:.3,//button width
width:'200',//define canvas width.,canvas height
displayInput:'tr
- Android+Jquery Mobile学习系列(5)-SQLite数据库
白糖_
JQuery Mobile
目录导航
SQLite是轻量级的、嵌入式的、关系型数据库,目前已经在iPhone、Android等手机系统中使用,SQLite可移植性好,很容易使用,很小,高效而且可靠。
因为Android已经集成了SQLite,所以开发人员无需引入任何JAR包,而且Android也针对SQLite封装了专属的API,调用起来非常快捷方便。
我也是第一次接触S
- impala-2.1.2-CDH5.3.2
dayutianfei
impala
最近在整理impala编译的东西,简单记录几个要点:
根据官网的信息(https://github.com/cloudera/Impala/wiki/How-to-build-Impala):
1. 首次编译impala,推荐使用命令:
${IMPALA_HOME}/buildall.sh -skiptests -build_shared_libs -format
2.仅编译BE
${I
- 求二进制数中1的个数
周凡杨
java算法二进制
解法一:
对于一个正整数如果是偶数,该数的二进制数的最后一位是 0 ,反之若是奇数,则该数的二进制数的最后一位是 1 。因此,可以考虑利用位移、判断奇偶来实现。
public int bitCount(int x){
int count = 0;
while(x!=0){
if(x%2!=0){ /
- spring中hibernate及事务配置
g21121
Hibernate
hibernate的sessionFactory配置:
<!-- hibernate sessionFactory配置 -->
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<
- log4j.properties 使用
510888780
log4j
log4j.properties 使用
一.参数意义说明
输出级别的种类
ERROR、WARN、INFO、DEBUG
ERROR 为严重错误 主要是程序的错误
WARN 为一般警告,比如session丢失
INFO 为一般要显示的信息,比如登录登出
DEBUG 为程序的调试信息
配置日志信息输出目的地
log4j.appender.appenderName = fully.qua
- Spring mvc-jfreeChart柱图(2)
布衣凌宇
jfreechart
上一篇中生成的图是静态的,这篇将按条件进行搜索,并统计成图表,左面为统计图,右面显示搜索出的结果。
第一步:导包
第二步;配置web.xml(上一篇有代码)
建BarRenderer类用于柱子颜色
import java.awt.Color;
import java.awt.Paint;
import org.jfree.chart.renderer.category.BarR
- 我的spring学习笔记14-容器扩展点之PropertyPlaceholderConfigurer
aijuans
Spring3
PropertyPlaceholderConfigurer是个bean工厂后置处理器的实现,也就是BeanFactoryPostProcessor接口的一个实现。关于BeanFactoryPostProcessor和BeanPostProcessor类似。我会在其他地方介绍。
PropertyPlaceholderConfigurer可以将上下文(配置文件)中的属性值放在另一个单独的标准java
- maven 之 cobertura 简单使用
antlove
maventestunitcoberturareport
1. 创建一个maven项目
2. 创建com.CoberturaStart.java
package com;
public class CoberturaStart {
public void helloEveryone(){
System.out.println("=================================================
- 程序的执行顺序
百合不是茶
JAVA执行顺序
刚在看java核心技术时发现对java的执行顺序不是很明白了,百度一下也没有找到适合自己的资料,所以就简单的回顾一下吧
代码如下;
经典的程序执行面试题
//关于程序执行的顺序
//例如:
//定义一个基类
public class A(){
public A(
- 设置session失效的几种方法
bijian1013
web.xmlsession失效监听器
在系统登录后,都会设置一个当前session失效的时间,以确保在用户长时间不与服务器交互,自动退出登录,销毁session。具体设置很简单,方法有三种:(1)在主页面或者公共页面中加入:session.setMaxInactiveInterval(900);参数900单位是秒,即在没有活动15分钟后,session将失效。这里要注意这个session设置的时间是根据服务器来计算的,而不是客户端。所
- java jvm常用命令工具
bijian1013
javajvm
一.概述
程序运行中经常会遇到各种问题,定位问题时通常需要综合各种信息,如系统日志、堆dump文件、线程dump文件、GC日志等。通过虚拟机监控和诊断工具可以帮忙我们快速获取、分析需要的数据,进而提高问题解决速度。 本文将介绍虚拟机常用监控和问题诊断命令工具的使用方法,主要包含以下工具:
&nbs
- 【Spring框架一】Spring常用注解之Autowired和Resource注解
bit1129
Spring常用注解
Spring自从2.0引入注解的方式取代XML配置的方式来做IOC之后,对Spring一些常用注解的含义行为一直处于比较模糊的状态,写几篇总结下Spring常用的注解。本篇包含的注解有如下几个:
Autowired
Resource
Component
Service
Controller
Transactional
根据它们的功能、目的,可以分为三组,Autow
- mysql 操作遇到safe update mode问题
bitray
update
我并不知道出现这个问题的实际原理,只是通过其他朋友的博客,文章得知的一个解决方案,目前先记录一个解决方法,未来要是真了解以后,还会继续补全.
在mysql5中有一个safe update mode,这个模式让sql操作更加安全,据说要求有where条件,防止全表更新操作.如果必须要进行全表操作,我们可以执行
SET
- nginx_perl试用
ronin47
nginx_perl试用
因为空闲时间比较多,所以在CPAN上乱翻,看到了nginx_perl这个项目(原名Nginx::Engine),现在托管在github.com上。地址见:https://github.com/zzzcpan/nginx-perl
这个模块的目的,是在nginx内置官方perl模块的基础上,实现一系列异步非阻塞的api。用connector/writer/reader完成类似proxy的功能(这里
- java-63-在字符串中删除特定的字符
bylijinnan
java
public class DeleteSpecificChars {
/**
* Q 63 在字符串中删除特定的字符
* 输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。
* 例如,输入”They are students.”和”aeiou”,则删除之后的第一个字符串变成”Thy r stdnts.”
*/
public static voi
- EffectiveJava--创建和销毁对象
ccii
创建和销毁对象
本章内容:
1. 考虑用静态工厂方法代替构造器
2. 遇到多个构造器参数时要考虑用构建器(Builder模式)
3. 用私有构造器或者枚举类型强化Singleton属性
4. 通过私有构造器强化不可实例化的能力
5. 避免创建不必要的对象
6. 消除过期的对象引用
7. 避免使用终结方法
1. 考虑用静态工厂方法代替构造器
类可以通过
- [宇宙时代]四边形理论与光速飞行
comsci
从四边形理论来推论 为什么光子飞船必须获得星光信号才能够进行光速飞行?
一组星体组成星座 向空间辐射一组由复杂星光信号组成的辐射频带,按照四边形-频率假说 一组频率就代表一个时空的入口
那么这种由星光信号组成的辐射频带就代表由这些星体所控制的时空通道,该时空通道在三维空间的投影是一
- ubuntu server下python脚本迁移数据
cywhoyi
pythonKettlepymysqlcx_Oracleubuntu server
因为是在Ubuntu下,所以安装python、pip、pymysql等都极其方便,sudo apt-get install pymysql,
但是在安装cx_Oracle(连接oracle的模块)出现许多问题,查阅相关资料,发现这边文章能够帮我解决,希望大家少走点弯路。http://www.tbdazhe.com/archives/602
1.安装python
2.安装pip、pymysql
- Ajax正确但是请求不到值解决方案
dashuaifu
Ajaxasync
Ajax正确但是请求不到值解决方案
解决方案:1 . async: false , 2. 设置延时执行js里的ajax或者延时后台java方法!!!!!!!
例如:
$.ajax({ &
- windows安装配置php+memcached
dcj3sjt126com
PHPInstallmemcache
Windows下Memcached的安装配置方法
1、将第一个包解压放某个盘下面,比如在c:\memcached。
2、在终端(也即cmd命令界面)下输入 'c:\memcached\memcached.exe -d install' 安装。
3、再输入: 'c:\memcached\memcached.exe -d start' 启动。(需要注意的: 以后memcached将作为windo
- iOS开发学习路径的一些建议
dcj3sjt126com
ios
iOS论坛里有朋友要求回答帖子,帖子的标题是: 想学IOS开发高阶一点的东西,从何开始,然后我吧啦吧啦回答写了很多。既然敲了那么多字,我就把我写的回复也贴到博客里来分享,希望能对大家有帮助。欢迎大家也到帖子里讨论和分享,地址:http://bbs.csdn.net/topics/390920759
下面是我回复的内容:
结合自己情况聊下iOS学习建议,
- Javascript闭包概念
fanfanlovey
JavaScript闭包
1.参考资料
http://www.jb51.net/article/24101.htm
http://blog.csdn.net/yn49782026/article/details/8549462
2.内容概述
要理解闭包,首先需要理解变量作用域问题
内部函数可以饮用外面全局变量
var n=999;
functio
- yum安装mysql5.6
haisheng
mysql
1、安装http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
2、yum install mysql
3、yum install mysql-server
4、vi /etc/my.cnf 添加character_set_server=utf8
- po/bo/vo/dao/pojo的详介
IT_zhlp80
javaBOVODAOPOJOpo
JAVA几种对象的解释
PO:persistant object持久对象,可以看成是与数据库中的表相映射的java对象。最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合。PO中应该不包含任何对数据库的操作.
VO:value object值对象。通常用于业务层之间的数据传递,和PO一样也是仅仅包含数据而已。但应是抽象出的业务对象,可
- java设计模式
kerryg
java设计模式
设计模式的分类:
一、 设计模式总体分为三大类:
1、创建型模式(5种):工厂方法模式,抽象工厂模式,单例模式,建造者模式,原型模式。
2、结构型模式(7种):适配器模式,装饰器模式,代理模式,外观模式,桥接模式,组合模式,享元模式。
3、行为型模式(11种):策略模式,模版方法模式,观察者模式,迭代子模式,责任链模式,命令模式,备忘录模式,状态模式,访问者
- [1]CXF3.1整合Spring开发webservice——helloworld篇
木头.java
springwebserviceCXF
Spring 版本3.2.10
CXF 版本3.1.1
项目采用MAVEN组织依赖jar
我这里是有parent的pom,为了简洁明了,我直接把所有的依赖都列一起了,所以都没version,反正上面已经写了版本
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="ht
- Google 工程师亲授:菜鸟开发者一定要投资的十大目标
qindongliang1922
工作感悟人生
身为软件开发者,有什么是一定得投资的? Google 软件工程师 Emanuel Saringan 整理了十项他认为必要的投资,第一项就是身体健康,英文与数学也都是必备能力吗?来看看他怎么说。(以下文字以作者第一人称撰写)) 你的健康 无疑地,软件开发者是世界上最久坐不动的职业之一。 每天连坐八到十六小时,休息时间只有一点点,绝对会让你的鲔鱼肚肆无忌惮的生长。肥胖容易扩大罹患其他疾病的风险,
- linux打开最大文件数量1,048,576
tianzhihehe
clinux
File descriptors are represented by the C int type. Not using a special type is often considered odd, but is, historically, the Unix way. Each Linux process has a maximum number of files th
- java语言中PO、VO、DAO、BO、POJO几种对象的解释
衞酆夼
javaVOBOPOJOpo
PO:persistant object持久对象
最形象的理解就是一个PO就是数据库中的一条记录。好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。可以看成是与数据库中的表相映射的java对象。最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合。PO中应该不包含任何对数据库的操作。
BO:business object业务对象
封装业务逻辑的java对象