吴恩达·2022机器学习专项课程|House Price Prediction
House Price Prediction
Import
import copy, math
import numpy as np
import matplotlib.pyplot as plt
Load Dataset
def load_house_data():
data = np.loadtxt("./data/houses.txt", delimiter=',', skiprows=1)
X = data[:,:4]
y = data[:,4]
return X, y
# load the dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
Feature Scaling
To implement z-score normalization, adjust your input values as shown in this formula:
x j ( i ) = x j ( i ) − μ j σ j x^{(i)}_j = \dfrac{x^{(i)}_j - \mu_j}{\sigma_j} xj(i)=σjxj(i)−μj
where j j j selects a feature or a column in the X matrix. µ j µ_j µj is the mean of all the values for feature (j) and σ j \sigma_j σj is the standard deviation of feature (j).
μ j = 1 m ∑ i = 0 m − 1 x j ( i ) σ j 2 = 1 m ∑ i = 0 m − 1 ( x j ( i ) − μ j ) 2 \begin{align} \mu_j &= \frac{1}{m} \sum_{i=0}^{m-1} x^{(i)}_j\\ \sigma^2_j &= \frac{1}{m} \sum_{i=0}^{m-1} (x^{(i)}_j - \mu_j)^2 \end{align} μjσj2=m1i=0∑m−1xj(i)=m1i=0∑m−1(xj(i)−μj)2
def zscore_normalize_features(X):
"""
computes X, zcore normalized by column
Args:
X (ndarray): Shape (m,n) input data, m examples, n features
Returns:
X_norm (ndarray): Shape (m,n) input normalized by column
mu (ndarray): Shape (n,) mean of each feature
sigma (ndarray): Shape (n,) standard deviation of each feature
"""
# find the mean of each column/feature
mu = np.mean(X, axis=0) # mu will have shape (n,)
# find the standard deviation of each column/feature
sigma = np.std(X, axis=0) # sigma will have shape (n,)
# element-wise, subtract mu for that column from each example, divide by std for that column
X_norm = (X - mu) / sigma
return (X_norm, mu, sigma)
#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)
# normalize the original features
X_norm, X_mu, X_sigma = zscore_normalize_features(X_train)
Gradient Descent for Multiple Linear Regression
Model
f w , b ( x ( i ) ) = w ⋅ x ( i ) + b f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = \mathbf{w} \cdot \mathbf{x}^{(i)} + b fw,b(x(i))=w⋅x(i)+b
Compute Cost
J ( w , b ) = 1 2 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) 2 J(\mathbf{w},b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})^2 J(w,b)=2m1i=0∑m−1(fw,b(x(i))−y(i))2
def compute_cost(X, y, w, b):
"""
compute cost
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
f_wb_i = np.dot(X[i], w) + b #(n,)(n,) = scalar (see np.dot)
cost = cost + (f_wb_i - y[i])**2 #scalar
cost = cost / (2 * m) #scalar
return cost
Compute Gradient
∂ J ( w , b ) ∂ w j = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) ∂ J ( w , b ) ∂ b = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) \begin{align} \frac{\partial J(\mathbf{w},b)}{\partial w_j} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_{j}^{(i)} \\ \frac{\partial J(\mathbf{w},b)}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) \end{align} ∂wj∂J(w,b)∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))xj(i)=m1i=0∑m−1(fw,b(x(i))−y(i))
def compute_gradient(X, y, w, b):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar): The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape #(number of examples, number of features)
dj_dw = np.zeros((n,))
dj_db = 0.
for i in range(m):
err = (np.dot(X[i], w) + b) - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err * X[i, j]
dj_db = dj_db + err
dj_dw = dj_dw / m
dj_db = dj_db / m
return dj_db, dj_dw
Gradient Descent
repeat until convergence: { w j = w j − α ∂ J ( w , b ) ∂ w j for j = 0..n-1 b = b − α ∂ J ( w , b ) ∂ b } \begin{align*} \text{repeat}&\text{ until convergence:} \; \lbrace \newline\; & w_j = w_j - \alpha \frac{\partial J(\mathbf{w},b)}{\partial w_j} \; & \text{for j = 0..n-1}\newline &b\ \ = b - \alpha \frac{\partial J(\mathbf{w},b)}{\partial b} \newline \rbrace \end{align*} repeat} until convergence:{wj=wj−α∂wj∂J(w,b)b =b−α∂b∂J(w,b)for j = 0..n-1
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters):
"""
Performs batch gradient descent to learn theta. Updates theta by taking
num_iters gradient steps with learning rate alpha
Args:
X (ndarray (m,n)) : Data, m examples with n features
y (ndarray (m,)) : target values
w_in (ndarray (n,)) : initial model parameters
b_in (scalar) : initial model parameter
cost_function : function to compute cost
gradient_function : function to compute the gradient
alpha (float) : Learning rate
num_iters (int) : number of iterations to run gradient descent
Returns:
w (ndarray (n,)) : Updated values of parameters
b (scalar) : Updated value of parameter
"""
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_db,dj_dw = gradient_function(X, y, w, b) ##None
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw ##None
b = b - alpha * dj_db ##None
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( cost_function(X, y, w, b))
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]:8.2f} ")
return w, b, J_history #return final w,b and J history for graphing
Run Gradient Descent
m,n = X_train.shape
# initialize parameters
initial_w = np.zeros(n)
initial_b = 0.
# some gradient descent settings
iterations = 1000
alpha = 3.0e-2
w_final, b_final, J_hist = gradient_descent(X_norm, y_train, initial_w, initial_b,
compute_cost, compute_gradient,
alpha, iterations)
Iteration 0: Cost 67079.58
Iteration 100: Cost 601.08
Iteration 200: Cost 251.09
Iteration 300: Cost 223.40
Iteration 400: Cost 219.76
Iteration 500: Cost 219.28
Iteration 600: Cost 219.22
Iteration 700: Cost 219.21
Iteration 800: Cost 219.21
Iteration 900: Cost 219.21
Plot Cost versus Iterations
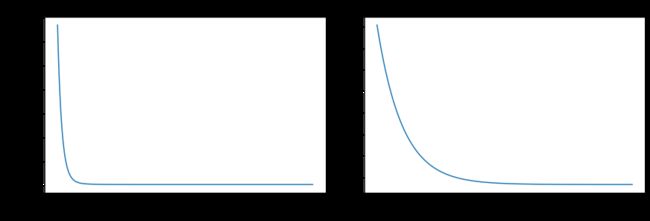
# plot cost versus iteration
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True, figsize=(12, 4))
ax1.plot(J_hist)
ax2.plot(500 + np.arange(len(J_hist[500:])), J_hist[500:])
ax1.set_title("Cost vs. iteration"); ax2.set_title("Cost vs. iteration (tail)")
ax1.set_ylabel('Cost') ; ax2.set_ylabel('Cost')
ax1.set_xlabel('iteration step') ; ax2.set_xlabel('iteration step')
plt.show()
Prediction
x_house = np.array([1200, 3, 1, 40])
x_house_norm = (x_house - X_mu) / X_sigma # normalization
print(x_house_norm)
x_house_predict = np.dot(x_house_norm, w_final) + b_final
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.0f}")
[-0.53052829 0.43380884 -0.78927234 0.06269567]
predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = $318710