跟误告警说再见,Smart Metrics 帮你用算法配告警
作者:董善东、陈昆仪
引言
某位资深 SRE 同学表示“一天不收个几十条告警,我都觉得不安心”,“告警天天告,我们的应用一点事情都没有”。这都反映了一个非常普遍的现象 – “误告警泛滥”,而“真”告警容易被淹没。ARMS AIOps 团队对超过 6 万条关于响应时间和错误率突增的告警进行了分析,发现其中只有 3.05%的告警是“真”告警。同时发现误告警泛滥根源在于单靠现有告警产品的能力很难配置出行之有效的告警规则。因此,ARMS 基于托管版 Grafana 推出智能告警插件——Smart Metrics,用算法帮助用户解决"告警配置难、维护难"的问题。
本文从两类常见的无效告警规则入手,分析有效告警配置难,误告警泛滥的原因,介绍 Smart Metrics 是如何帮助用户解决告警难配的问题的,并介绍一些最佳实践。最后,欢迎加入 SmartMetrics 交流群,钉钉群号 25125004458。
告警现状分析
误告警泛滥
我们通过对 ARMS 告警数据及用户访谈进行分析,发现许多用户一天收几百条告警,但其中真正有用的只有几条。更可怕的是,那几条“真”告警往往被淹没在大量误告警中,导致用户没能在第一时间对真实故障做出处理。这些误告警往往是由一些不良的告警配置习惯造成的,比较典型的有下面两种:
“一刀切”式配告警方式:
比如一位 SRE 同学要管理很多接口,但为了节省告警配置时间,所以选择对所有应用/接口的响应时间、错误率和调用量配置统一且固定阈值。然而,不同应用/接口正常状态下的响应时间、调用量和错误率指标的正常水位本身就不相同,成百上千的应用/接口使用同一阈值自然会产生大量误告警。
“疏于打理”的告警阈值:
有的告警规则在应用起初是没有问题的,但随着业务增长,响应时间、调用量等业务指标,以及 CPU 使用率等机器指标的平均水位线已发生变化。但 SRE 没有及时更新阈值,导致系统正常时也会不断产生告警。
一般而言,只要针对上述两种告警策略进行优化,就可以有效避免大量误告警。但实际上,它们的优化并不简单。原因在于现有告警产品往往只支持用户使用静态阈值配置告警。
我们先来看一下典型告警配置页面:它提供了很多常用聚合算子:均值、最大值、最小值、差分等,用户可以用这些算子自定义告警规则。

我们再来看看真实的运维指标,比如 qps(每分钟调用量),发现它长这个样子:

那么,现在应该 min\max\avg 什么?阈值该设置成多少?
有效告警配置难、维护难的原因
面对真实多变的运维指标,即使是经验丰富的运维专家也很难配出有效告警。我们总结有效告警配置难、维护难的主要原因:
1. 许多运维指标起伏不定,很难设定合适的静态阈值。
它们往往呈现出以小时、天、周为周期的季节性特征。这些指标本身就起伏不定,导致静态阈值、同比阈值都不好配。
2. 同一指标,不同应用\接口\主机阈值不同。
以 RT 指标(响应时间)举例, 有的接口正常时 RT 在 200ms 左右,那么当 RT 大于 300ms 时,可以判定为异常。然而,有些接口长期访问量大, 整体指标在 500ms 左右正常波动,合适的告警阈值可能是 600ms 左右。而一个应用可能有几百个接口,运维同学要对所有接口配置合适的阈值,时间成本非常高。
3. 指标的正常水位会随着业务的增长变化。
随着公司业务发展、新应用上线,一些指标正常状态水位会不断变化。如果没有及时更新阈值,就很容易产生大量误告警。
综上,靠现有告警产品中依赖静态阈值方式,需要 SRE 同学投入大量时间成本且难以取得较好效果。 为解决这个问题,ARMS推出基于 Grafana 的智能告警插件——SmartMetrics,用算法来帮助用户配置有效告警。
更简单的告警配置方式-SmartMetrics

SmartMetrics 是一款“智能、易用、效果可见”的告警插件,能够从历史指标数据学习指标的特征,并对未来一段时间内指标正常变化范围做出预测,生成上下边界。这里的上下边界围成的区间默认就是 90 置信区间。也就是按照前面几天的趋势,指标没有发生异常的话,有 90 的概率,它未来的值会落到我们预测得到的上下边界中。
SmartMetrics 支持 Grafana 原生告警功能,可利用 SmartMetrics 生成的上下边界作为配置告警的阈值。简单的配告警策略可以是当指标超过上界或低于下界时发出告警。也可以配置更多复杂策略,如原始曲线高于上边界 1.5 倍且过去一小时内没有出现过高于上边界的情况下才发出告警等。
目前,SmartMetrics 已在托管版 Grafana 上线,未来还将作为附加功能嵌入到 ARMS 的告警能力中。
SmartMetrics 如何生成上下边界
SmartMetrics 通过多模型融合方式为不同类型指标计算上下边界。SmartMetrics 先通过 Smart-PLR 算法捕捉指标关键特征,并利用分类算法确定该指标曲线类型;根据其类型来选择最适合时序预测模型与最佳参数;最后生成上下边界。
SmartMetrics 在采取业界热门开源算法 Prophet、STL、ARIMA, BiLSTM 基础上,基于阿里云内部大数据实践进行单周期/多周期识别、趋势识别、异常点识别、毛刺识别、变点识别等优化, 最终融合成一套多模型 Smart-Prophet 算法方案。SmartMetrics 具有以下几个特点:
a. 准确性:算法在阿里云内部进行多场景经历过验证, 拥有精准、全面的异常点发现能力。配合告警持续时间,起到精准告警效果。
b. 通用性:算法对于业务指标和基础指标有比较好支持, 对于周期性、趋势性、波动性指标进行比较好的曲线分类和模型参数配置。
c. 免维护:使用SmartMetrics的用户无需随业务变化对算法进行动态化调参,算法可自适应通过对指标变化的规律学习,从而适应业务变化。
SmartMetrics 如何解决有效告警配置难、维护难的问题
1. SmartMetrics 如何应对起伏不定的运维指标配置有效告警的需求
SmartMetrics 会自动根据 7 天历史数据预测曲线在未来 1 天内曲线在正常状态下的上下边界,并实时地写入指标实际值。用户可以利用 Grafana 自带的告警能力配置告警:当指标实际值超出上下边界时,或是实际值超出上边界值 1.5 倍时,发出告警。用户可自定义多种告警规则,更多最佳实践可以参考 SmartMetrics 的官方文档。

2. SmartMetrics如何应对同一指标,不同应用\接口\主机告警阈值不同的场景
对不同应用\接口\主机的指标分配用 SmartMetrics 生成上下边界,SmartMetrics 会自动学习各自特征,生成适合的动态基线,用户不需要再手工输入静态阈值。
3. SmartMetrics如何应对由于业务发展带来的静态阈值维护难的问题
SmartMetrics默认每天更新模型,自动学习由于业务变化带来的指标正常水位线变化,免人工维护。
SmartMetrics 最佳实践
步骤 1. 创建动态阈值任务
- 选择合适的数据源
- 选择所需要动态监控的指标
注意:目前只支持1条指标的任务, 因此需要明确指标中的 label value, 或者通过算子如 sum, count,实现单个指标查询。多指标配置目前规划中,依据用户反馈决定是否上线。
- 选择完成后, 执行 Run Query, 可以查询到对应的指标曲线。
- 设定合适的模型参数, 选则灵敏度等,建议使用默认配置。
- 填写正确的名称及描述。
- 点击创建预测,完成创建。

步骤 2. 查看指标
- 创建成功任务之后, 可以点击返回任务列表。
注意:创建任务后,任务立即启动, 完成数据拉取, 计算, 存储等任务, 该过程需要等待 1-2 分钟左右。
- 点击查看大盘, 查看具体的指标和对应上下边界情况。

- 大盘提供了原始指标时间序列数据和对应的上下边界组合成的正常区域。指标值在边界之内则可以理解为算法判定正常, 超出上下边界则可以理解为算法判定异常。
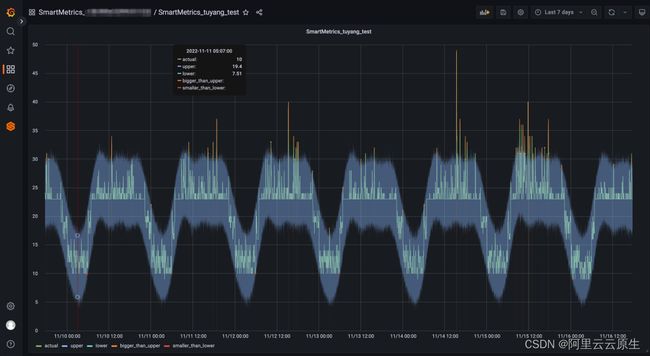
-
点击 Edit, 进入编辑页面。
-
当前指标和上下边界统一保存在promenthus数据源cloud_product_prometheus_cn-hangzhou_aiops_userId中。指标名称即为创建任务时的名称, 对应的label:smart_metric取不同的值(actual,upper, lower), 则对应着(原始指标, 上边界指标, 下边界指标)。例如:如果用户想单独查看上边界, 则只需要在对应的数据源cloud_product_prometheus_cn-hangzhou_aiops_userId 中查找对应的指标。

步骤 3. 异常检测&配置告警
- 在查看指标大盘页面中, 点击 Edit,进入编辑页面

- 在 Query 页面, 可以查看 D 查询指标中, 默认预置了超过上边界的指标查询:
tuyang_test{smart_metric=“actual”} > ignoring (smart_metric) tuyang_test{smart_metric=“upper”}

-
在 grafana 下方 tab 页面, 进入到 Alert 页面,并 Create Alert
-
配置 NULL 的情况下, 为 OK, 同时配置通知人和通知信息

其他查询玩法请参考:超出上边界:
test{smart_metric="actual"} > ignoring (smart_metric) test{smart_metric="upper"}
超出下边界:
test{smart_metric="actual"} < ignoring (smart_metric) test{smart_metric="lower"}
超出上/下边界:
test{smart_metric="actual"} > ignoring (smart_metric) test{smart_metric="upper"} or test{smart_metric="actual"} < ignoring (smart_metric) test{smart_metric="lower"}
超出上边界阈值比例 20%:
test{smart_metric="actual"} > ignoring (smart_metric) test{smart_metric="upper"} *1.2
步骤 4. 告警通知
- 对于发生的告警, 可以在配置的通知方式获取到告警, 点击链接并跳转到 grafana 中进行查看。

步骤 5. 任务管理
- 对于不需要的动态阈值检测任务, 可以在任务列表中进行删除。

欢迎加入 SmartMetrics 交流群
Last but not least,欢迎加入 SmartMetrics 交流群并提出更多的需求与指导意见!!
钉钉搜索群号:25125004458


首月免费,点击此处立即体验!