【Pytorch深度学习50篇】·······第六篇:【常见损失函数篇】-----BCELoss及其变种
新年新气象,兄弟们新年快乐。撒花!!!
之前我们的项目已经讲过了常见的4种深度学习任务(当然还有一些没有接触到的,例如GAN和今年大红的Transformer),今天这个blog我们就来谈谈一谈常见的损失函数。损失函数的更新也是非常的快,各位大佬的想法也是层出不穷,我们站在巨人的肩膀上,就可以看的更远,走的更远。
1.BCELoss
BCELoss又叫二分类交叉熵损失,顾名思义,它是用来做二分类的损失函数,我们先来看看BCELoss的公式。
![]()
其中pt---模型预测值,target---标签值, w---权重值,一般是1
上面这个公式是单个样本的,当一个batch有N个样本时
![]()
这么说是不是显得很苍白无力,所以我们来一个例子吧,我们先创建一个pt和target
torch.manual_seed(0)
pt = torch.rand(2, 3)
target = torch.tensor([[0., 0., 1.], [1., 0., 0.]])
print(pt)
print(target)pt我用的随机数代替的,target一般是0或者1,我们print一下,看看目前的数值是多少
这里的torch.rand(2, 3)中的2代表2个样本,3代表每个样本是一个1*3的向量

好了,我们来挨个计算:
pt的第一行第一列的值是 0.4963,它对应的标签target的第一行第一列的值是0,所以求根据刚才的公式L(pt,target) = -w*(target * ln(pt) + (1-target) * ln(1-pt)),w一般取1
L = -1 * (0*ln(0.4963)+1*ln(1-0.4963)) = -ln(1-0.4963) = 0.685774426230532 ≈ 0.6857
pt的第一行第二列的值是 0.7682,它对应的标签target的第一行第一列的值是0
L = -1 * (0*ln(0.7682)+1*ln(1-0.7682)) = -ln(1-0.7682) = 1.46188034807648 ≈ 1.4620
pt的第一行第三列的值是 0.0885,它对应的标签target的第一行第一列的值是1
L = -1 * (1*ln(0.0885)+0*ln(1-0.0885)) = -ln(0.0885) = -2.424752726968253 ≈ 2.4250
接下去,我就不算了,留个兄弟们来算,我们用代码来验证一下算对了没有吧
def com(x, y):
loss = -(y * torch.log(x) + (1 - y) * torch.log(1 - x))
return loss
losss = com(pt, target)
print(losss)此时x就是pt,y也就是target,值得注意的是torch.log = ln,它不是真的log,看看计算结果吧

看第一行,和我们刚刚的计算结果完全吻合,确实是这么算的,没跑了
别忘了,同时每一个样本也要求一下平均值
第一个样本的平均值是 (0.6857 + 1.4620 + 2.4250)/ 3 = 1.524233333333333333333
第二个样本的平均值是 (2.0247 + 0.3673 + 1.0053)/ 3 = 1.132433333333333333333
根据公式:
![]()
所以loss = (1.524233333333333333333 + 1.132433333333333333333)/ 2 ≈1.328333
上代码看看是不是这么回事吧
torch.manual_seed(0)
pt = torch.rand(2, 3)
target = torch.tensor([[0., 0., 1.], [1., 0., 0.]])
print('pt:',pt)
print('target:',target)
def com(x, y):
loss = -(y * torch.log(x) + (1 - y) * torch.log(1 - x))
return loss
losss = com(pt, target)
print(losss)
losss = torch.mean(com(pt, target))
print('总loss:',losss)看看结果
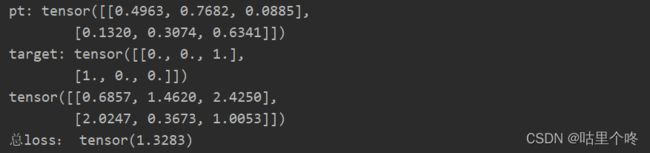
不错,一模一样,算对了。但是你肯定有疑问了,你这是你自己手算的,代码也是你自己写的,你只能证明你的计算和你的代码是对上了,怎么证明真正的和BCELoss对上了,那我们请出Pytorch的nn.BCELoss来看看结果吧
torch.manual_seed(0)
pt = torch.rand(2, 3)
target = torch.tensor([[0., 0., 1.], [1., 0., 0.]])
print('pt:',pt)
print('target:',target)
loss = nn.BCELoss()
print('pytorch loss:',loss(pt, target))
怎么样,我是不是算对了。
值得注意的是,在用BCELoss的时候,要记得先经过一个sigmoid或者softmax,以保证pt是0-1之间的。当然了,pytorch不可能想不到这个啊,所以它还提供了一个函数nn.BCEWithLogitsLoss()他会自动进行sigmoid操作。棒棒的!
2.带权重的BCELoss
先看看BCELoss的公式,w就是所谓的权重
![]()
torch.nn.BCELoss()中,其实提供了一个weight的参数

我们要保持weight的形状和维度与target一致就可以了。
于是我手写一个带权重BCELoss,上代码
class BCE_WITH_WEIGHT(torch.nn.Module):
def __init__(self, alpha=0.25, reduction='mean'):
super(BCE_WITH_WEIGHT, self).__init__()
self.alpha = alpha
self.reduction = reduction
def forward(self, predict, target):
pt = predict
loss = -((1-self.alpha) * target * torch.log(pt+1e-5) + self.alpha * (1 - target) * torch.log(1 - pt+1e-5))
if self.reduction == 'mean':
loss = torch.mean(loss)
elif self.reduction == 'sum':
loss = torch.sum(loss)
return loss核心带代码是
loss = -((1-self.alpha) * target * torch.log(pt+1e-5) + self.alpha * (1 - target) * torch.log(1 - pt+1e-5))alpha就是权重了,一般很多时候,正负样本是不平衡的,如果不加入权重,网络训练的时候,训练的关注的重点就跑到了样本多的那一类样本上去,对样本少的就不公平了,所以为了维护世界和平,贯彻爱与真实的邪恶,可爱又迷人的反派角色,带权重的损失函数就出现了。
大家可以看到,我在有一个地方是torch.log(pt+1e-5),1e-5的意思就是10的-5次方,为什么要加入1e-5,这个跟ln函数有关系,因为ln(0) = -无穷大,这样损失就爆炸了,训练就会出错误,所以默认就把它加上了。
3.BCE版本的Focal_Loss
FocalLoss的公式
![]()
此时的pt就是刚刚的那个pt了,此时的pt就是刚刚我们的BCEloss的结果了
先上代码看看吧
class BCEFocalLoss(torch.nn.Module):
def __init__(self, gamma=2, alpha=0.25, reduction='mean'):
super(BCEFocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
self.reduction = reduction
def forward(self, predict, target):
pt = predict
loss = - ((1 - self.alpha) * ((1 - pt+1e-5) ** self.gamma) * (target * torch.log(pt+1e-5)) + self.alpha * (
(pt++1e-5) ** self.gamma) * ((1 - target) * torch.log(1 - pt+1e-5)))
if self.reduction == 'mean':
loss = torch.mean(loss)
elif self.reduction == 'sum':
loss = torch.sum(loss)
return loss核心代码:
loss = - ((1 - self.alpha) * ((1 - pt+1e-5) ** self.gamma) * (target * torch.log(pt+1e-5)) + self.alpha * (
(pt+1e-5) ** self.gamma) * ((1 - target) * torch.log(1 - pt+1e-5)))Focalloss的目前不仅是为了控制样本不平衡的现象,还有个作用就是,让网络着重训练难样本。
好了,BCE讲的差不多了,讲的不对的地方,欢迎大家指出。
至此,敬礼,salute!!!
老规矩,上咩咩狗
