hard example mining(困难样本挖掘)
分类中的一些基础概念:
- 正样本:包含我们想要识别类别的样本,例如,我们在做猫狗分类,那么在训练的时候,包括猫或者狗的图片就是正样本
- 负样本:在上面的例子中,不包含猫或者狗的其他所有的图片都是负样本
- 难分正样本(hard positives):易错分成负样本的正样本,对应在训练过程中损失最高的正样本,loss比较大(label与prediction相差较大)。
- 难分负样本(hard negatives):易错分成正样本的负样本,对应在训练过程中损失最高的负样本**
- 易分正样本(easy positive):容易正确分类的正样本,该类的概率最高。对应在训练过程中损失最低的正样本
- 易分负样本(easy negatives):容易正确分类的负样本,该类的概率最高。对应在练过程中损失最低的负样本。
**举例补充:**如果roi里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫easy negative;如果roi里有二分之一个物体,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是had negative。
为什么要进行困难样本挖掘?
在区域提议(Region Proposal) 的目标检测算法中,负样本的数量会远高于正样本的数量,其中大部分都是对网络训练作用相对较小的易分负样本(easy negatives)。根据Focal Loss论文的统计,一般包含少量信息的“easy examples”(基本都是负例),与包含有用信息的“hard examples”(正例+难负例)之比为100000:100!这导致这些简单例的损失函数值将是难例损失函数的40倍!

由于正样本数量一般较少,所有对于困难样本挖掘(hard example mining)一般是指难负例挖掘(Hard Negative Mining)。
为了让模型正常训练,我们必须要通过某种方法抑制大量的简单负例,挖掘所有难例的信息,这就是难例挖掘的初衷。即在训练时,尽量多挖掘些难负例(hard negative)加入负样本集参与模型的训练,这样会比easy negative组成的负样本集效果更好。
关于hard negative mining,比较生动的例子是高中时期你准备的错题集。错题集不会是每次所有的题目你都往上放。放上去的都是你最没有掌握的那些知识点(错的最厉害的),而这一部分是对你学习最有帮助的。
方法:离线和在线
离线:
在样本训练过程中,会将训练结果与GroundTruth计算IOU。通常会设定一个阈值(0.5),结果超过阈值认为是正样本,低于一定阈值的则认为是负样本,然后扔进网络中训练。
但是,随着训练的进行,这样的策略也许会出现一个问题,那就是正样本的数量会远远小于负样本,这样会导致数据的分布不平衡,使得网络的训练结果不是很好。
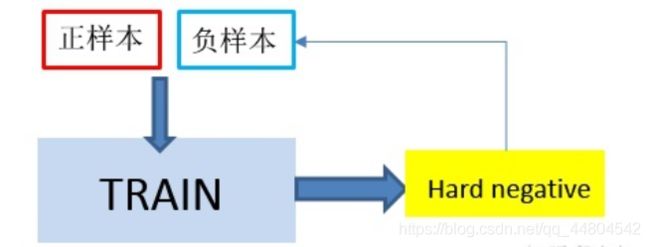
当然有些论文作者针对这种导致不平衡的数据,提出了一种对称的模型。就是类似上图,将Hard Posiotive也重新赋给正样本。
在线:
CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)将难分样本挖掘(hard example mining)机制嵌入到SGD算法中,使得Fast R-CNN在训练的过程中根据region proposal的损失自动选取合适的Region Proposal作为正负例训练。
上面的论文就是讲的在线的方法:Online Hard Example Mining,简称OHEM
实验结果表明使用OHEM(Online Hard Example Mining)机制可以使得Fast R-CNN算法在VOC2007和VOC2012上mAP提高 4%左右。
即:训练的时候选择hard negative来进行迭代,从而提高训练的效果。
简单来说就是从ROI中选择hard,而不是简单的采样。
Forward: 全部的ROI通过网络,根据loss排序;
Backward:根据排序,选择B/N个loss值最大的(worst)样本来后向传播更新model的weights.
这里会有一个问题,即位置相近的ROI在map中可能对应的是同一个位置,loss值是相近的,所以针对这个问题,提出的解决方法是:对hard做nms,然后再选择B/N个ROI反向传播,这里nms选择的IoU=0.7。
在后向传播时,直觉想到的方法就是将那些未被选中的ROI的loss直接设置为0即可,但这实际上还是将所有的ROI进行反向传播,时间和空间消耗都很大,所以作者在这里提出了本文的网络框架,用两隔网络,一个只用来前向传播,另一个则根据选择的ROIs进行后向传播,的确增加了空间消耗(1G),但是有效的减少了时间消耗,实际的实验结果也是可以接受的。
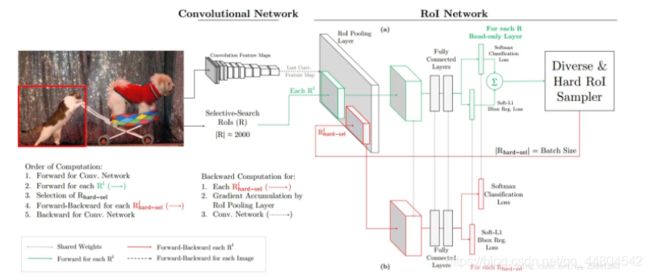
在绿色部分的(a)中,一个只读的RoI网络对特征图和所有RoI进行前向传播,然后Hard RoI module利用这些RoI的loss选择B个样本。在红色部分(b)中,这些选择出的样本(hard examples)进入RoI网络,进一步进行前向和后向传播。同样是利用loss选择,但是针对的是two stage的方案,选取的是第一阶段的rois。
在mmdetection中的实现
在正负样本的挑选过程中,采用困难样例挖掘的方法进行筛选而不是简单的随机挑选;
def _sample_pos(self,
assign_result,
num_expected,
bboxes=None,
feats=None,
**kwargs):
# Sample some hard positive samples
pos_inds = torch.nonzero(assign_result.gt_inds > 0)
if pos_inds.numel() != 0:
pos_inds = pos_inds.squeeze(1)
if pos_inds.numel() <= num_expected: #如果样本量本身少于期望值不进行困难样本挖掘
return pos_inds
else:
return self.hard_mining(pos_inds, num_expected, bboxes[pos_inds],
assign_result.labels[pos_inds], feats)
def _sample_neg(self,
assign_result,
num_expected,
bboxes=None,
feats=None,
**kwargs):
# Sample some hard negative samples
neg_inds = torch.nonzero(assign_result.gt_inds == 0)
if neg_inds.numel() != 0:
neg_inds = neg_inds.squeeze(1)
if len(neg_inds) <= num_expected:
return neg_inds
else: #如果样本量多于期望值,进行困难样本挖掘进行筛选
return self.hard_mining(neg_inds, num_expected, bboxes[neg_inds],
assign_result.labels[neg_inds], feats)
计算样本的损失值,根据类别的loss挑选出损失比较大的样本【困难样本】
def hard_mining(self, inds, num_expected, bboxes, labels, feats):
#inds: 正负样本的索引; num_expected:期望的正负样本数量; bboxes:正负样本【anchor】, labels:类别标签 feats:特征图
with torch.no_grad(): #不参与梯度的计算
rois = bbox2roi([bboxes])
bbox_feats = self.bbox_roi_extractor(
feats[:self.bbox_roi_extractor.num_inputs], rois)
cls_score, _ = self.bbox_head(bbox_feats)
loss = self.bbox_head.loss(
cls_score=cls_score,
bbox_pred=None,
labels=labels,
label_weights=cls_score.new_ones(cls_score.size(0)),
bbox_targets=None,
bbox_weights=None,
reduction_override='none')['loss_cls']
_, topk_loss_inds = loss.topk(num_expected)
return inds[topk_loss_inds]