论文阅读:SynGCN
Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks

摘要:
词嵌入已在多种 NLP 应用程序中得到广泛采用。大多数现有的词嵌入方法利用一个词的顺序上下文来学习它的嵌入。
虽然已经有一些尝试利用单词的句法上下文,但此类方法会导致词汇量激增。在本文中,我们通过提出 SynGCN 来克服这个问题,SynGCN 是一种灵活的基于图卷积的学习词嵌入的方法。 SynGCN 在不增加词汇量的情况下利用单词的依赖上下文。 SynGCN 学习的词嵌入在各种内在和外在任务上优于现有方法,并在与 ELMo 一起使用时提供优势。我们还提出了 SemGCN,这是一个有效的框架,可以结合不同的语义知识,进一步增强学习到的单词表示。我们提供两种模型的源代码以鼓励可重复的研究。
相关工作
词嵌入:最近,人们对学习有意义的词表示很感兴趣,例如基于连续词袋 (CBOW) 和 skip-gram (SG) 模型的神经语言建模 (Bengio et al, 2003) (Mikolov et al , 2013a). Pennington 等人 (2014) 进一步扩展了这一点,它通过分解单词共现矩阵来利用全局统计信息来学习嵌入。学习词嵌入的其他公式包括多任务学习(Collobert 等人,2011 年)和排名框架(Ji 等人,2015 年)。
基于语法的嵌入:基于依赖解析上下文的词嵌入由 Levy 和 Goldberg (2014) 首次引入。它们允许对单词之间的句法关系进行编码,并在功能相似性比主题相似性更相关的任务上表现出改进。通过二阶(Komninos 和 Manandhar,2016 年)和多阶(Li 等人,2018 年)依赖关系进一步增强了句法上下文的包含。然而,在所有这些现有方法中,为了合并句法关系,单词词汇表被严重扩展。
整合语义知识源:来自多个语义源的语义关系,如同义词、反义词、上位词等,已被用于提高单词表示的质量。现有方法要么联合利用它们,要么作为后处理步骤。 SynGCN 属于后一类,并且在合并语义约束方面更有效(第 9.2 和 9.3 节)。
图卷积网络:在本文中,我们通过(Kipf 和 Welling,2016)提出的逐层传播规则使用 GCN 的一阶公式。最近,还提出了 GCN 的一些变体。可以在 Bronstein 等人 (2017) 中找到 GCN 及其应用的详细描述。在 NLP 中,GCN 已被用于语义角色标记(Marcheggiani 和 Titov,2017)、机器翻译(Bastings 等人,2017)和关系提取(V ashishth 等人,2018b)。最近,Yao 等人 (2018) 通过联合嵌入单词和文档,使用 GCN 进行文本分类。然而,他们学习的嵌入是特定于任务的,而在我们的工作中,我们的目标是学习与任务无关的词表示。
学习词嵌入的任务
在无监督环境中学习单词表示的任务可以表述如下:给定一个文本语料库,目标是为词汇表中的每个单词学习一个 d 维嵌入。大多数基于分布假设的方法只对语料库中的每个单词使用顺序上下文。然而,当相关的上下文词超出窗口大小时,这就变得次优了。相反,较大的窗口大小可能允许不相关的词对词嵌入产生负面影响。使用基于依赖的上下文有助于缓解这个问题。然而,所有现有的基于句法上下文的方法都严重扩展了词汇量(如第 1 节所述),这限制了它们对大型语料库的可扩展性。
为了消除这个缺点,我们提出了 SynGCN,它使用图形卷积网络来更好地编码嵌入中的句法信息。因为 GCN 不将图限制为树,并且被发现在捕获全局信息方面更有效(Zhang 等人,2018)。
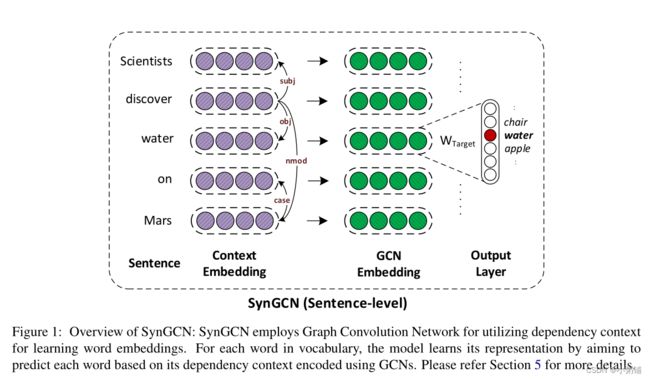
此外,它们提供了显着的加速,因为它们不涉及难以并行化的递归操作。总体架构如图 1 所示:
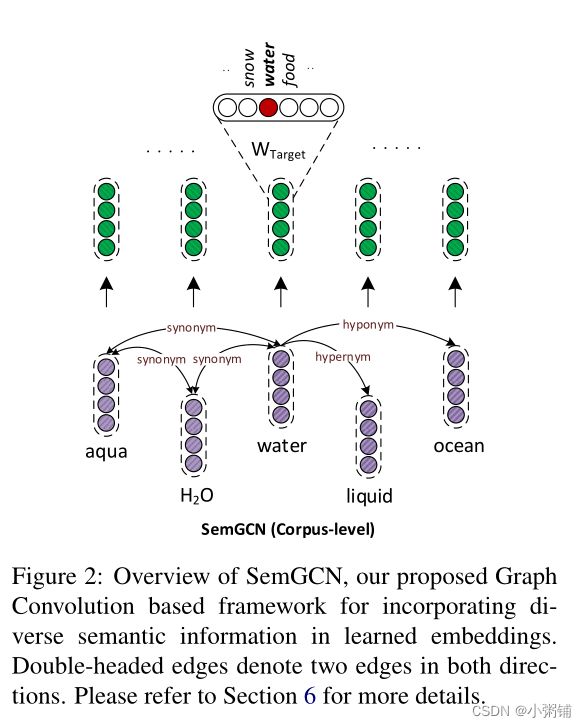
用语义知识丰富词嵌入有助于提高它们在多项 NLP 任务中的质量。在本文中,我们提出了 SemGCN,它通过将它们建模为不同的边缘类型来自动学习利用多个语义约束。可以作为类似于Faruqui et al (2014) 、Mrkši´c 等人 (2016)的后处理方法。
SynGCN
在本节中,我们详细描述了我们提出的方法 SynGCN。遵循 Mikolov 等人 (2013b); Levy 和 Goldberg (2014); Komninos 和 Manandhar (2016),我们分别为词汇表中的每个单词定义目标和上下文嵌入作为模型中的参数。对于给定的句子 s = ( w 1 , w 2 , . . . , w 3 ) s=(w_1,w_2,...,w_3) s=(w1,w2,...,w3),我们首先使用 Stanford CoreNLP 解析器提取其依赖解析图 G s = ( V s , E s ) \mathcal{G_s=(V_s,E_s)} Gs=(Vs,Es)(Manning et al, 2014)。这里, V s = ( w 1 , w 2 , . . . , w 3 ) \mathcal{V_s}=(w_1,w_2,...,w_3) Vs=(w1,w2,...,w3) 和 E s \mathcal{E_s} Es表示形式 ( w i , w j , l i j ) (w_i, w_j, l_{ij}) (wi,wj,lij) 的标记有向依赖边,其中 l i j l_{ij} lij 是 w i w_i wi 对 w j w_j wj 的依赖关系。
类似于 Mikolov 等人 (2013b) 的连续词袋 (CBOW) 模型,对于 大小为 c 的窗口,它将单词 w i w_i wi 的上下文定义为 C w i = w i + j : − c ≤ j ≤ c , j ≠ 0 C_{wi} = {w_{i+j} : −c ≤ j ≤ c, j \ne 0} Cwi=wi+j:−c≤j≤c,j=0,我们将上下文定义为其在 G s \mathcal{G_s} Gs 中的邻居,即 C w i = N ( w i ) C_{w_i} = \mathcal{N(w_i)} Cwi=N(wi)。
与 CBOW 不同的是,CBOW 使用 C w i C_{w_i} Cwi 中词的上下文嵌入的总和来预测 w i w_i wi,我们在 G s \mathcal{G_s} Gs 上应用有向图卷积网络,并将 s 中词的上下文嵌入作为输入特征。因此,对于 s 中的每个单词 w i w_i wi,我们使用下列等式在 GCN 的 k 层之后获得表示 h i k + 1 h^{k+1}_i hik+1:
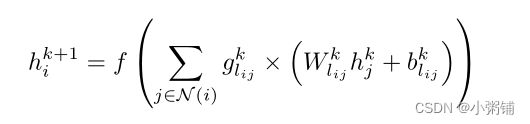
我们不在 Gs 中包含自循环。这有助于避免过度拟合初始嵌入,这在 SynGCN 的情况下是不可取的,因为它使用随机初始化。我们注意到 Mikolov 等人 (2013b) 也采用了类似的策略。此外,为了处理自动构建的依赖解析图中的错误边缘,我们执行边缘门控以重视相关边缘并抑制噪声边缘。然后使用获得的嵌入来计算损失。
SynGCN 利用句法上下文来学习更有意义的单词表示。我们在第 9.1 节中对此进行了验证。请注意,单词词汇表在整个学习过程中保持不变,这使得 SynGCN 与现有方法相比更具可扩展性。
请注意,SynGCN 是 CBOW 模型的推广。
SemGCN
在本节中,我们提出了另一个基于图卷积的框架 SemGCN,用于将语义知识整合到预训练词嵌入中,
大多数现有方法,如 Faruqui 等人 (2014); Mrkši´c 等人(2016)仅限于处理同义和反义等对称关系。另一方面,尽管最近提出的 (Alsuhaibani et al, 2018) 能够处理不对称信息,但它仍然需要手动定义关系强度函数,这可能是劳动密集型和次优的。
SemGCN 能够结合对称和非对称信息。 与 SynGCN 不同,SemGCN 在语料库级别的有向标记图上运行,以单词为节点,边表示来自不同来源的单词之间的语义关系。例如,在图 2 中,语义关系(例如下位词、上位词和同义词)一起表示在一个图中。 通过在两个方向上都包含有向边来处理对称信息。 给定语料库级别图 G,训练过程类似于 SynGCN,即根据 G 中的邻居预测单词 w。受 Faruqui 等人 (2014) 的启发,我们保留了预训练嵌入中编码的语义使用给定的词表示初始化目标和上下文嵌入,并在训练期间保持目标嵌入固定。
SemGCN 使用下列等式来更新节点嵌入:
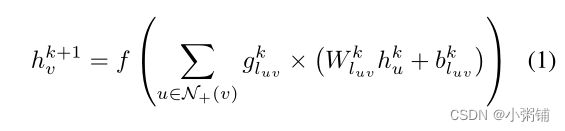
请注意,在这种情况下, N + ( v ) \mathcal{N}_+(v) N+(v) 用作邻域定义以保留单词的初始学习表示。
训练目标
给定一个词 ( w t ) (w_t) (wt) 的 GCN 表示 ( h t ) (h_t) (ht),SynGCN 和 SemGCN 的训练目标是在给定图中相邻词的情况下预测目标词。形式上,对于每种方法,我们最大化以下目标 :

其中, w t w_t wt 是目标词, w 1 t , w 2 t , . . . , w N t t w^t_1, w^t_2, ..., w^t_{N_t} w1t,w2t,...,wNtt 在图中是它的邻居。使用 softmax 函数计算概率 P ( w t ∣ w 1 t , w 2 t , . . . , w N t t ) P (w_t|w^t_1, w^t_2, ..., w^t_{N_t}) P(wt∣w1t,w2t,...,wNtt),定义为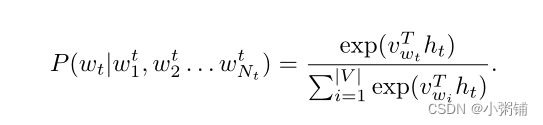
E可以化简为:
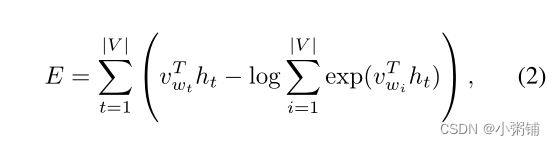
其中, ( h t ) (h_t) (ht) 是目标词 ( w t ) (w_t) (wt)的 GCN 表示, v w t v_{w_t} vwt 是其目标嵌入。
等式 2 中的第二项计算量很大,因为需要对整个词汇表求和。这可以使用多种近似来克服,例如噪声对比估计(Gutmann 和 Hyvärinen,2010)和分层 softmax(Morin 和 Bengio,2005)。在我们的方法中,我们使用 Mikolov 等人 (2013b) 使用的负采样。
总结
在本文中,我们提出了 SynGCN,一种基于图卷积的方法,它利用句法上下文来学习单词表示。 SynGCN 克服了词汇量爆炸的问题,并在几个内在和外在任务上优于最先进的词嵌入方法。我们还提出了 SemGCN,这是一个在预训练词嵌入中联合整合多种语义信息的框架。 SynGCN 和 SemGCN 的组合提供了最佳的整体性能。我们提供两种模型的源代码以鼓励可重复的研究。