【论文简述】PatchmatchNet: Learned Multi-View Patchmatch Stereo(CVPR 2021)
一、论文简述
1. 第一作者:Fangjinhua Wang
2. 发表年份:2021
3. 发表期刊:CVPR
4. 关键词:MVS、深度学习、Patchmatch、自适应、迭代优化
5. 探索动机:可扩展性、时间、内存占用等效率问题依然没有解决。
While being successful at the benchmark level, most of them do only pay limited attention to scalability, memory and run-time.
6. 工作目标:Patchmatch是一种很好的提高效率的解决方案,是否可以与深度学习方式相结合?
Several traditional MVS methods abandon the idea of holding a structured cost volume completely and instead are based on the seminal Patchmatch algorithm. Patchmatch adopts a randomized, iterative algorithm for approximate nearest neighbor field computation. In particular, the inherent spatial coherence of depth maps is exploited to quickly find a good solution without the need to look through all possibilities. Low memory requirements – independent of the disparity range – and an implicit smoothing effect make this method very attractive for our deep learning based MVS setup.
7. 核心思想:PatchmatchNet是一种基于学习的Patchmatch新的级联方式,目的是降低高分辨率MVS的内存消耗和运行时间。它继承了经典Patchmatch在效率上的优势,同时通过深度学习的优势来提高性能。
- 将Patchmatch思想引入到基于MVS的端到端可训练的从粗到细的深度学习框架中,以加快计算速度。
- 用可学习的、自适应的模块来增强Patchmatch的传统传播和代价评估步骤,以提高准确性,该模块建立在深度特征的基础上。此外,提出了一种鲁棒训练策略,将随机性引入到训练中,以提高可见性估计和泛化的鲁棒性。
8. 实验结果:在DTU、Tanks & Temples和ETH3D数据集上,与大多数基于学习的方法相比,PatchmatchNet实现了具有竞争力的性能和广泛性,效率比所有现有最好的模型都要好,比最先进的方法快至少2.5倍,内存使用量少两倍。下图中,误差、GPU内存和运行时长之间的关系,图像大小为1152×864。

9. 论文和代码下载:
https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_PatchmatchNet_Learned_Multi-View_Patchmatch_Stereo_CVPR_2021_paper.pdf
https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_PatchmatchNet_Learned_Multi-View_Patchmatch_Stereo_CVPR_2021_paper.pdf
二、实现过程
1. PatchmatchNet概述
PatchmatchNet的结构,由多尺度特征提取、基于学习的Patchmatch(从粗到细的迭代框架)和空间改进模块组成。Patchmatch用于多个阶段的进行多次迭代,以从粗到细的方式预测深度图。改进模块使用输入来指导最终深度图的上采样。输入图像大小为W×H,在阶段k,深度图的分辨率为W/k2×H/k2。

因为手残,写了一天的帖子没了......csdn的撤回真的很不智能,大家慎用!
这篇写的很好,直接看:MVSNet系列论文详解-PatchmatchNet
总体感受,这篇文章用词高级,逻辑清晰,每个部分开头都会讲清楚设计缘由,值得反复学习。
6. 实验
6.1. 数据集
DTU Dataset、Tanks and Temples Benchmark、ETH3D
The DTU dataset [1] is an indoor multi-view stereo dataset with 124 different scenes where all scenes share the same camera trajectory.
6.2. Robust Training Strategy
第一次见这样的训练方式
Many learning-based methods [7,16,26,36,38,39] select two best source views based on view selection scores [39] to train models on DTU [1]. However, the selected source views have a strong visibility correlation with the reference view, which may affect the training of the pixel-wise view weight network. Instead, we propose a robust training strategy based on PVSNet [37].For each reference view, we randomly choose four from the ten best source views for training. This strategy increases the diversity at training time and augments the dataset on the fly, which improves the generalization performance. In addition, training on those random source views with weak visibility correlation generates further robustness for our visibility estimation.
6.3. 实现
训练:通过PyTorch实现,使用DTU数据集训练。深度图尺寸为160×128。输入视图数N=5,图像大小裁剪到640 × 512,输入图像的总数设置为N = 5。将阶段3,2,1上的Patchmatch迭代次数设置为2,2。批大小为4,并在2个Nvidia GTX 1080Ti gpu上进行训练。深度估计后重建点云,类似于MVSNet的方法。
6.4. 结果
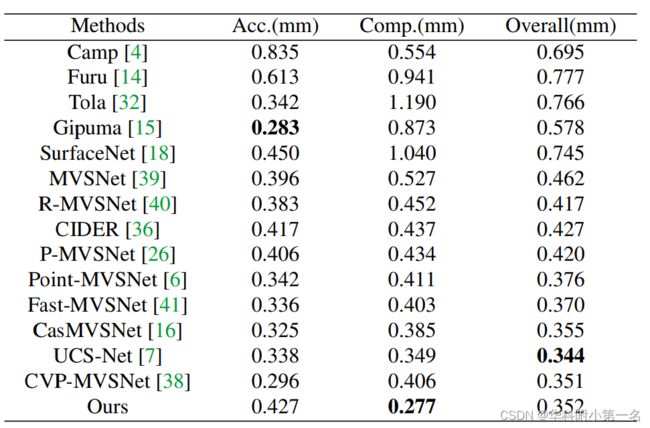
DTU数据集基准:输入原始大小的图像(1600×1200),设置视图数N为5,效果很好。
内存和运行时长比较。使用DTU的数据集,GPU内存、运行时长与输入分辨率的关系。原图像分辨率为1600×1200(100%)。在较高的分辨率下,其他方法无法在Nvidia RTX 2080 GPU评估。

Tanks & Temples:输入图像大小为1920×1056,视图数N为7。在计算过程中,深度图的GPU内存和运行时间分别为2887MB和0.505s。通过OpenMVG得到相机参数和稀疏点云。对于更复杂的高级数据集,该方法在所有方法中表现最好。

ETH3D。输入图像大小为2688 × 1792。由于在ETH3D中有很强的视图变化,我们也使用N = 7个视图以利用更多的多视图信息。相机参数和稀疏点云通过COLMAP得到。

ETH3D的场景中像素级视图权重的可视化。源图像和参考图像中用方框标记的区域是共可见的。右边:相应的像素级视图权重,颜色鲜艳(大值)表示共同可见的。像素附近深度不连续处比周围区域略暗。像素级视图权重确实能够确定参考视图和源视图之间的共同可见区域。
6.5. 消融实验
- Adaptive Propagation (AP) & Adaptive Evaluation(AE)
- Number of Iterations of Patchmatch
- Pixel-wise View Weight (VW) & Robust Training Strategy (RT)
- Number of Views