机器学习-白板推导-系列(二)笔记:高斯分布与概率
文章目录
- 0 笔记说明
- 1 高斯分布
-
- 1.1 求uMLE
- 1.2 求σMLE
- 2 有偏估计与无偏估计
-
- 2.1 uMLE为无偏估计
- 2.2 σ2MLE为有偏估计
- 3 高斯分布的概率密度函数
- 4 高斯分布的局限性
- 5 边缘概率与条件概率的求解
-
- 5.1 边缘概率分布P(xa)与P(xb)
- 5.2 条件概率分布P(xa|xb)与P(xb|xa)
- 6 联合概率分布的求解
-
- 6.1 p(y)的求解
- 6.2 p(x|y)的求解
0 笔记说明
来源于【机器学习】【白板推导系列】【合集 1~23】,我在学习时会跟着up主一起在纸上推导,博客内容为对笔记的二次书面整理,根据自身学习需要,我可能会增加必要内容。
注意:本笔记主要是为了方便自己日后复习学习,而且确实是本人亲手一个字一个公式手打,如果遇到复杂公式,由于未学习LaTeX,我会上传手写图片代替(手机相机可能会拍的不太清楚,但是我会尽可能使内容完整可见),因此我将博客标记为【原创】,若您觉得不妥可以私信我,我会根据您的回复判断是否将博客设置为仅自己可见或其他,谢谢!
本博客为(系列二)的笔记,对应的视频是:【(系列二) 数学基础-概率-高斯分布1-极大似然估计】、【(系列二) 数学基础-概率-高斯分布2-极大似然估计-无偏VS有偏】、【(系列二) 数学基础-概率-高斯分布3-从概率密度角度观察】、【(系列二) 数学基础-概率-高斯分布4-局限性】、【(系列二) 数学基础-概率-高斯分布5-求边缘概率以及条件概率】、【(系列二) 数学基础-概率-高斯分布6-求联合概率分布】。
下面开始即为正文。
1 高斯分布
数据集X中有N个样本实例,每个样本有p个维度。用符号表示为X = (x1,x2,…,xN)T,xi∈Rp,i=1…N,X为N*P阶矩阵。
设xi独立同分布于高维(维度为p)的高斯分布N(α,β),即xi~N(α,β),i=1…N。这里参数θ=(α,β),此时概率密度函数P(x)为:

为方便讨论,现在令p=1,θ=(μ,σ2),即【α=μ,β=σ2】。此时xi~N(μ,σ2),i=1…N。则xi的期望值E(xi)=μ,此时变成一维高斯分布(或称为一维正态分布)概率密度函数P(x)为:
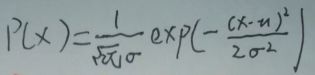
根据此文【机器学习-白板推导-系列(一)笔记:频率派/贝叶斯派】中【2 频率派:θ为未知常量】一节的图片可得:

因为此时θ=(μ,σ2),既然求θMLE,就求【uMLE】和【σMLE】好了。
1.1 求uMLE

然后对uMLE关于μ求导,并令导数等于0:
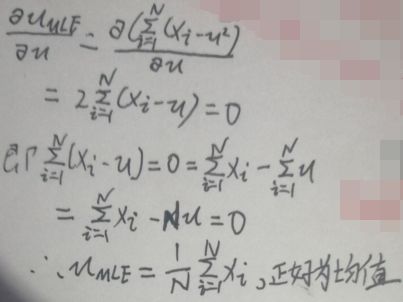
1.2 求σMLE

然后对σMLE关于σ求导,并令导数等于0:

2 有偏估计与无偏估计
有偏估计就是估计值与实际值有偏差;无偏估计就是估计值与实际值相同。举个栗子:设μ1为μ的估计,若μ1的期望E(μ1)=μ,则μ1为μ的无偏估计;设σ21为σ2的估计,若σ21的期望E(σ21)≠σ2,则σ21为σ2的有偏估计。
那么问题来了,在前一节即【1 高斯分布】一节中求出的uMLE和σ2MLE属于哪种估计呢?
2.1 uMLE为无偏估计

2.2 σ2MLE为有偏估计
第一步,化简:
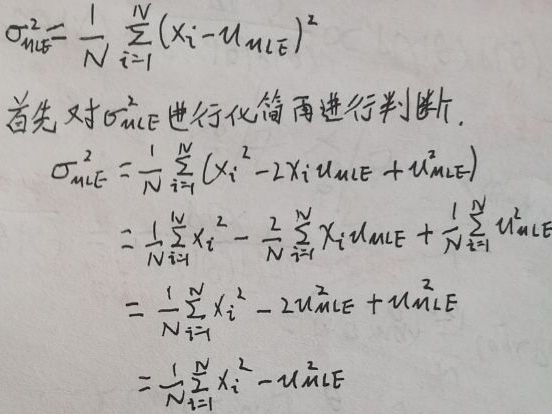
第二步,判断:

3 高斯分布的概率密度函数
现在有一个数据集X中有N个样本实例,每个样本有p个维度。用符号表示为X = (x1,x2,…,xN)T,xi∈Rp,i=1…N。
设x为随机变量(小写的哦),且x本身是一个p维向量,x=(x1,x2,…,xp)T。假设x~N(μ,Σ),μ为x的期望即【E(x)=μ】,则μ也为p维向量,设μ=(μ1,μ2,…,μp)T;Σ为x的协方差矩阵,Σ为对称矩阵且是半正定的。下图给出了Σ矩阵:

下图是高维的高斯分布的概率密度函数(【(x-μ)TΣ-1(x-μ)】本质是一个二次型,是半正定的,但是为了方便讨论,下文假设为正定的):

【(x-μ)TΣ-1(x-μ)】是向量x与μ的马氏距离,为【(1×p)×(p×p)×(p×1)=1】维的一个数。当Σ为p维单位矩阵,则马氏距离变成欧氏距离。下面对Σ做特征分解(也称为谱分解):

将上面算好的Σ代入【(x-μ)TΣ-1(x-μ)】:

利用一个小技巧(根据up主的说法,向量yi为向量x-μ在向量μi方向上的投影,我线代和矩阵学的不好,暂时不太了解),如下:

p为维度,令p=2。为了书写方便,令【Δ=(x-μ)TΣ-1(x-μ)】,则:

4 高斯分布的局限性

5 边缘概率与条件概率的求解
现在将x分为两部分,令x=(xa,xb)T,xa为m维向量,xb为n维向量,且m+n=p。不难看出xa与xb的联合概率分布即为x的概率分布。
同样地,将μ分为两部分,令μ=(μa,μb)T,μa为m维向量,μb为n维向量,且m+n=p。
也将Σ矩阵划分为四部分:
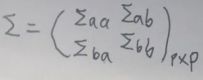
由于Σ是对称矩阵,所以ΣabT=Σba,ΣaaT=Σaa,ΣbbT=Σbb。
现在的问题就是求解:① 边缘概率分布P(xa)与P(xb);② 条件概率分布P(xa|xb)与P(xb|xa)。
先给出一个定理:设x~N(μ,Σ),y=Ax+B,A与B均为矩阵,则y~N(Aμ+B,AΣAT)。记此定理为*(下面会用到,一定记住)。
现在开始求解。
5.1 边缘概率分布P(xa)与P(xb)

则边缘概率分布P(xa)与P(xb)可由对应的高斯分布的概率密度函数给出。
5.2 条件概率分布P(xa|xb)与P(xb|xa)

现给出高斯分布的另一条定理:设x~N(μ,Σ),则Mx⊥Nx⇔MΣNT=0,这里Mx⊥Nx指Mx与Nx相互独立,M与N均为矩阵,Σ还是上面的分块矩阵:

记上面的定理为**(下面会用到,一定记住)。下面证明xba与xa的独立性,用到了**定理哦:
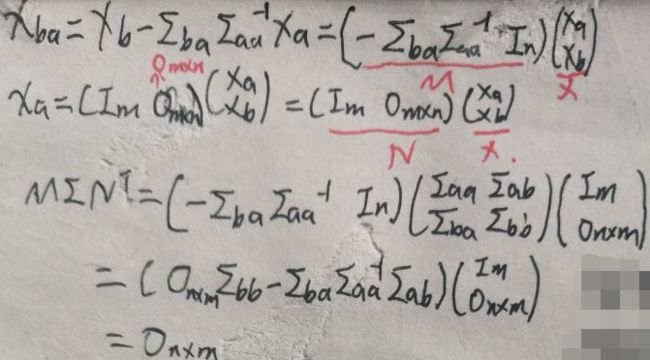
因为MΣNT=0,所以xba是xa相互独立的,所以结合条件概率与独立性【P(xba|xa)=P(xba)】。下面继续推:

6 联合概率分布的求解
已知x~N(μ,Λ-1),其中Λ-1称为精度矩阵,为协方差矩阵Σ的逆矩阵。y=Ax+b+ε,其中A与b为系数,ε~N(0,L-1),ε与x独立,则y|x~N(Aμ+b,L-1)。现在要求的是:① p(y);② p(x|y)。
6.1 p(y)的求解
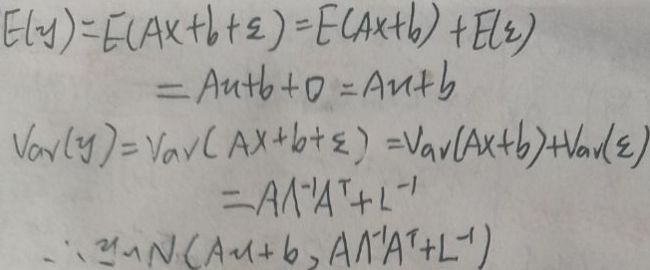
则p(y)可由对应的高斯分布的概率密度函数给出。
6.2 p(x|y)的求解
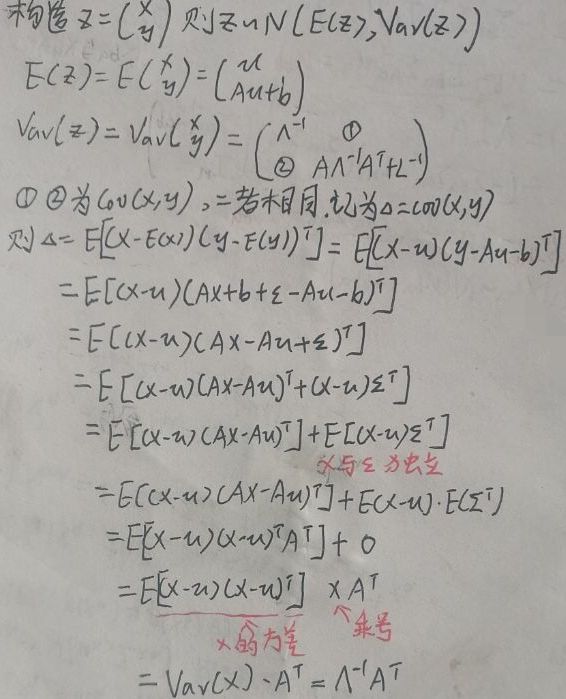
上面算出了E(z)与Var(z),则x与y的联合概率分布即z的分布为N(E(z),Var(z))。
在【5 边缘概率与条件概率的求解】一节中,x=(xa,xb)T,xa|xb的分布为:
![]()
其中的各个符号为:

根据上面的公式,x|y~N(μxy+ΣxyΣyy-1y,Σxxy),对应地,前面这个式子的各个符号为:
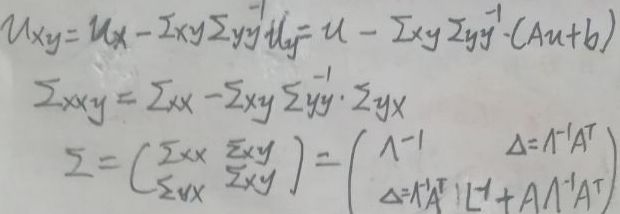
则p(x|y)可由对应的高斯分布的概率密度函数给出。
END