【论文笔记】LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities.
做视觉文本的理解任务,需要模型能理解视觉概念和文本语义信息,但最重要的是视觉和文本的对齐问题。
数据库:VQA GQA NLVR
简介
we present one of the first works in building a pre-trained vision-and-language cross-modality framework and show its strong performance on several datasets.
本文的作者注意到在文本和视觉的专门领域内都诞生了很多性能表现十分优秀的预训练模型,但是在这两个领域的跨模态任务中还不存在预训练模型,因此提出了一种文本视觉的跨模态预训练模型。
Our new cross-modality model focuses on learning vision-and-language interactions, especially for representations of a single image and its descriptive sentence.
.
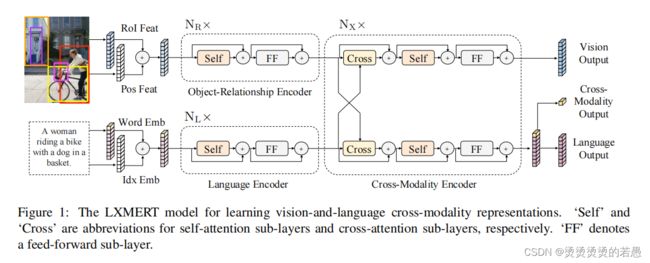
It consists of three Transformer (Vaswani et al., 2017) encoders: an object relationship encoder, a language encoder, and a cross-modality encoder.
.
In order to better learn the cross-modal alignments between vision and language, we next pre-train our model with five diverse representative tasks:
- masked cross modality language modeling,
- masked object prediction via RoI-feature regression,
- masked object prediction via detected-label classification,
- cross-modality matching,
- image question answering.
模型功能:图片和描述性文字
.
模型结构:3个Transformer的编码器
- object relationship encoder(关系)
- language encoder(语言)
- cross-modality encoder(跨模态)
.
模型预训练:5个训练任务
- 跨模态语言遮盖建模
- 目标预测-回归
- 目标预测-分类
- 跨模态匹配
- 图片问答
模型架构
our model takes two inputs: an image and its related sentence (e.g., a
caption or a question). Each image is represented as a sequence of objects, and each sentence is rep resented as a sequence of words.
输入是一张图片和一句话(描述或问题),输入嵌入层会把输入转为***词级别的句嵌入***和***目标级别的图嵌入***
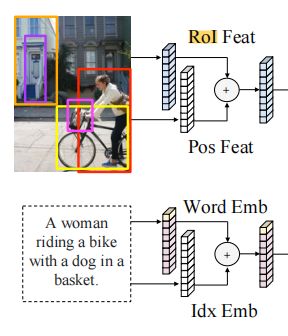
输入嵌入层
词级别句子嵌入
A sentence is first split into words {w1, . . . , wn} with length of n by the same WordPiece tokenizer (Wu et al., 2016) in Devlin et al. (2019). Next, as shown in Fig. 1, the word wi and its index i (wi’s absolute position in the sentence) are projected to vectors by embedding sub-layers, and then added to the index-aware word embeddings:
- 先把句子分词,固定分成n个词,使用的是WordPiece tokenizer。
- 然后分别位置编码和词编码
- 最后把位置编码和词编码得到的向量相加,做LayerNorm

目标级别图嵌入
Instead of using the feature map output by a convolutional neural network, we follow Anderson et al. (2018) in taking the features of detected objects as the embeddings of images.
- 没有使用卷积神经网络进行特征提取,而是使用目标的RoI特征作为图片嵌入
- 所谓的目标,是指目标检测得到的目标,即图片框住部分
Specifically, the object detector detects m objects {o1, . . . , om} from the image (denoted by bounding boxes on the image in Fig. 1). Each object oj is represented by its position feature (i.e., bounding box coordinates) pj and its 2048-dimensional region-of-interest (RoI) feature fj . Then, we learn a position-aware embedding vj by adding outputs of 2 fully-connected layers:
- pj是图片框的坐标
- fj是图片的2048维RoI特征(CV领域的方法,Bottom-up and top-down attention for image captioning and visual question answering.这篇论文可能有介绍)
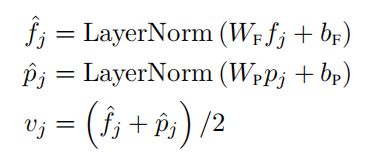
编码器
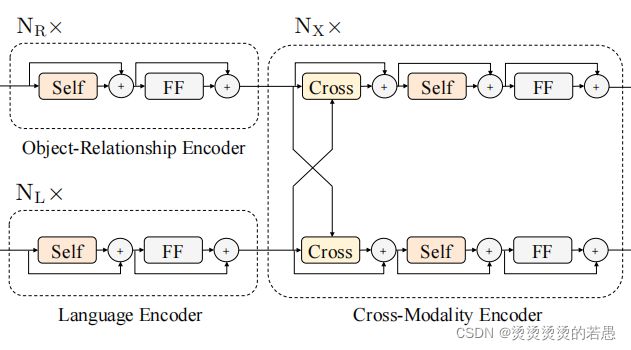
单模态编码器
After the embedding layers, we first apply two transformer encoders (Vaswani et al., 2017), i.e., a language encoder and an object-relationship encoder, and each of them only focuses on a single modality (i.e., language or vision). Different from BERT (Devlin et al., 2019), which applies the transformer encoder only to language inputs, we apply it to vision inputs as well.
单模态编码器中包含以下:
- 自注意力层
- 残差连接
- LayerNorm(+号代表)
- 前馈层
跨模态编码器
the cross-modality encoder consists of two self-attention sub-layers, one bi-directional cross-attention sublayer, and two feed-forward sub-layers.
跨模态编码器中包含以下:
- 1个双向cross-attention层
- 2个自注意力层
- 2个前馈层
.
the bi-directional cross-attention sub-layer (‘Cross’) is first applied, which contains two uni-directional cross-attention sub-layers: one from
language to vision and one from vision to language.
The query and context vectors are the outputs of the (k-1)-th layer
- 对于文本向量K而言,所有视觉向量都是Q
- 对于视觉向量K而言,所有文本向量都是Q
- K+1层以k层的输出作为QK
The cross-attention sub-layer is used to exchange the information and align the entities between the two modalities in order to learn joint cross-modality representations.
- Cros目的是实现两个模态之间的对齐
- 对齐之后再次进行self-attention以提取信息
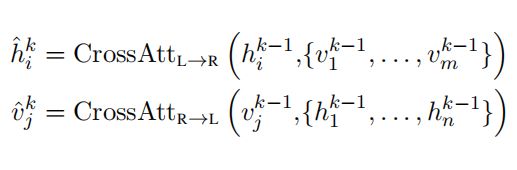
输出层
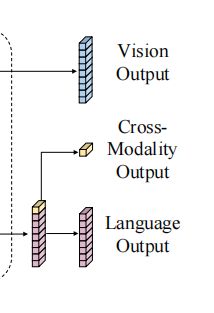
As shown in the right-most part of Fig. 1, our LXMERT cross-modality model has three outputs for language, vision, and cross-modality, respectively. The language and vision outputs are the feature sequences generated by the cross-modality encoder. For the cross-modality output, following the practice in Devlin et al. (2019), we append a special token [CLS] (denoted as the top yellow block in the bottom branch of Fig. 1) before the sentence words, and the corresponding feature vector of this special token in language feature sequences is used as the cross-modality output.
输出有三种类别:
- 视觉输出:跨模态编码器的视觉部分特征输出
- 文本输出:跨模态编码器的文本部分特征输出
- 跨模态输出:跨模态编码器的文本部分特征输出的[CLS]对应输出
模型预训练
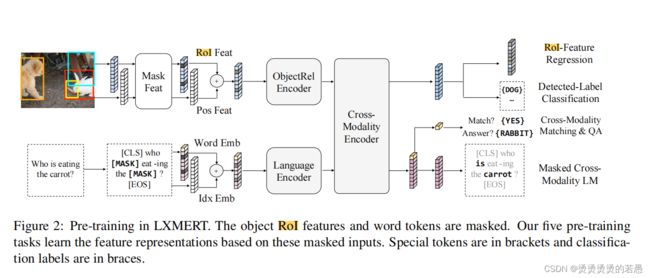
五种预训练任务
文本任务:Mask Language Model
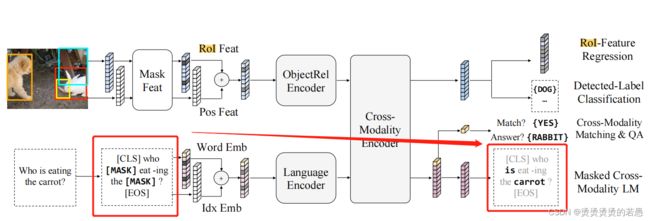
In addition to BERT where masked words are predicted from the non-masked words in the language modality, LXMERT, with its cross-modality model architecture, could predict masked words from the vision modality as well, so as to resolve ambiguity.
与Bert的预训练过程的区别在于:
- Bert预训练只能通过上下文去预测Mask
- LXMERT可以通过上下文结合图片信息共同预测Mask
.
比如在上图中,如果carrot被Mask住,仅凭文本信息是无法完成预测的,此时模型就会利用图片模态的信息进行预测。也就是说在训练过程中两个模态是共同参与的,在此过程中两个模态就会建立联系。
视觉任务:遮盖目标预测
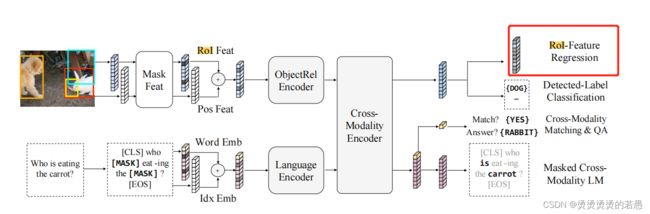
we pretrain the vision side by randomly masking objects (i.e., masking RoI features with zeros) with a probability of 0.15 and asking the model to predict proprieties of these masked objects.
- 文字mask是把原文用mask住
- 视觉mask是把ROI特征值用零替代(相当于把框内图扣掉)
ROI特征值回归
- 文字mask任务目标是恢复原词(分类任务)
- 视觉mask任务目标是恢复ROI特征值(回归任务)
标签分类
- 文字mask任务目标是恢复原词(分类任务)
- 视觉mask任务目标是预测遮盖住部分的标签(分类任务)
In the ‘Detected Label Classification’ sub-task, although most of our pre-training images have object-level annotations, the ground truth labels of the annotated objects are inconsistent in different datasets (e.g., different number of label classes). For these reasons, we take detected labels output by Faster R-CNN (Ren et al., 2015).
虽然原数据集都是有标签的,但是不同数据集的标签是不统一的,因此不能通用。最终,使用了额外的自动标注器对图片进行了统一标注。虽然标注器并不一定准确,但最终效果还是有提升的。
跨模态任务
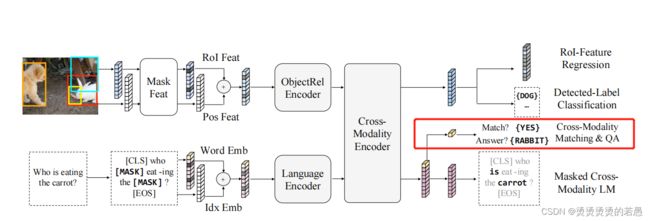
匹配
For each sentence, with a probability of 0.5, we replace it with a mismatched sentence. Then, we train a classifier to predict whether an image and a sentence match each other.
判断图片和其描述性文本是否匹配。
问答
We ask the model to predict the answer to these image related questions.
为了增加数据量,还在一些没有配套问题和答案的数据集中加入了假问题。让模型先进性匹配检测,再进行问答。
预训练数据
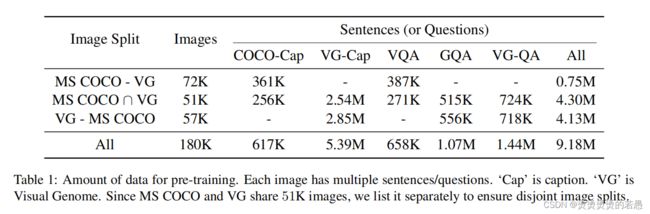
- MS COCO
- Visual Genome
- VQA
- GQA
- VG-QA
预训练流程(参数设置)
实验结果
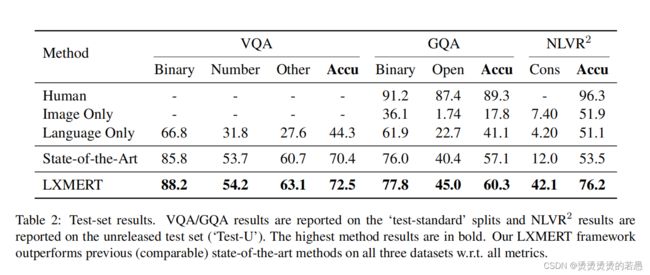
消融实验
忽略掉了,看不完了